


3.2 用tensorflow进行猫狗分类
import os
import zipfile
import random
import tensorflow as tf
from tensorflow.keras.optimizers import RMSprop
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from shutil import copyfile准备工作
!wget --no-check-certificate \
"https://download.microsoft.com/download/3/E/1/3E1C3F21-ECDB-4869-8368-6DEBA77B919F/kagglecatsanddogs_3367a.zip" \
-O "/tmp/cats-and-dogs.zip"
local_zip = '/tmp/cats-and-dogs.zip'
zip_ref = zipfile.ZipFile(local_zip, 'r')
zip_ref.extractall('/tmp')
zip_ref.close()print(len(os.listdir('/tmp/PetImages/Cat/')))
print(len(os.listdir('/tmp/PetImages/Dog/')))
# 12501
# 12501try:
os.mkdir('/tmp/cats-v-dogs')
os.mkdir('/tmp/cats-v-dogs/training')
os.mkdir('/tmp/cats-v-dogs/testing')
os.mkdir('/tmp/cats-v-dogs/training/cats')
os.mkdir('/tmp/cats-v-dogs/training/dogs')
os.mkdir('/tmp/cats-v-dogs/testing/cats')
os.mkdir('/tmp/cats-v-dogs/testing/dogs')
except OSError:
passimport os
import shutil
def split_data(SOURCE, TRAINING, TESTING, SPLIT_SIZE):
files = []
for filename in os.listdir(SOURCE):
file = SOURCE + filename
if os.path.getsize(file) > 0:
files.append(filename)
else:
print(filename + " is zero length, so ignoring.")
training_length = int(len(files) * SPLIT_SIZE)
testing_length = int(len(files) - training_length)
shuffled_set = random.sample(files, len(files))
training_set = shuffled_set[0:training_length]
testing_set = shuffled_set[-testing_length:]
for filename in training_set:
this_file = SOURCE + filename
destination = TRAINING + filename
copyfile(this_file, destination)
for filename in testing_set:
this_file = SOURCE + filename
destination = TESTING + filename
copyfile(this_file, destination)
CAT_SOURCE_DIR = "/tmp/PetImages/Cat/"
TRAINING_CATS_DIR = "/tmp/cats-v-dogs/training/cats/"
TESTING_CATS_DIR = "/tmp/cats-v-dogs/testing/cats/"
DOG_SOURCE_DIR = "/tmp/PetImages/Dog/"
TRAINING_DOGS_DIR = "/tmp/cats-v-dogs/training/dogs/"
TESTING_DOGS_DIR = "/tmp/cats-v-dogs/testing/dogs/"
def create_dir(file_dir):
if os.path.exists(file_dir):
print('true')
#os.rmdir(file_dir)
shutil.rmtree(file_dir)#删除再建立
os.makedirs(file_dir)
else:
os.makedirs(file_dir)
create_dir(TRAINING_CATS_DIR)
create_dir(TESTING_CATS_DIR)
create_dir(TRAINING_DOGS_DIR)
create_dir(TESTING_CATS_DIR)
split_size = .9
split_data(CAT_SOURCE_DIR, TRAINING_CATS_DIR, TESTING_CATS_DIR, split_size)
split_data(DOG_SOURCE_DIR, TRAINING_DOGS_DIR, TESTING_DOGS_DIR, split_size)
## true
## true
## true
## true
## 666.jpg is zero length, so ignoring.
## 11702.jpg is zero length, so ignoring.print(len(os.listdir('/tmp/cats-v-dogs/training/cats/')))
print(len(os.listdir('/tmp/cats-v-dogs/training/dogs/')))
print(len(os.listdir('/tmp/cats-v-dogs/testing/cats/')))
print(len(os.listdir('/tmp/cats-v-dogs/testing/dogs/')))
## 11250
## 11250
## 1250
## 1250模型定义
model = tf.keras.models.Sequential([
tf.keras.layers.Conv2D(16, (3, 3), activation='relu', input_shape=(150, 150, 3)),
tf.keras.layers.MaxPooling2D(2, 2),
tf.keras.layers.Conv2D(32, (3, 3), activation='relu'),
tf.keras.layers.MaxPooling2D(2, 2),
tf.keras.layers.Conv2D(64, (3, 3), activation='relu'),
tf.keras.layers.MaxPooling2D(2, 2),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(512, activation='relu'),
tf.keras.layers.Dense(1, activation='sigmoid')
])
model.compile(optimizer=RMSprop(lr=0.001), loss='binary_crossentropy', metrics=['acc'])TRAINING_DIR = "/tmp/cats-v-dogs/training/"
train_datagen = ImageDataGenerator(rescale=1.0/255.)
train_generator = train_datagen.flow_from_directory(TRAINING_DIR,
batch_size=100,
class_mode='binary',
target_size=(150, 150))
VALIDATION_DIR = "/tmp/cats-v-dogs/testing/"
validation_datagen = ImageDataGenerator(rescale=1.0/255.)
validation_generator = validation_datagen.flow_from_directory(VALIDATION_DIR,
batch_size=100,
class_mode='binary',
target_size=(150, 150))
## Found 22498 images belonging to 2 classes.
## Found 2500 images belonging to 2 classes.开始训练
太慢了,就只训练两个周期吧。
history = model.fit_generator(train_generator,
epochs=2,
verbose=1,
validation_data=validation_generator)Epoch 1/2
225/225 [==============================] - 222s 988ms/step - loss: 0.5015 - acc: 0.7553 - val_loss: 0.4552 - val_acc: 0.7812
Epoch 2/2
225/225 [==============================] - 223s 989ms/step - loss: 0.4282 - acc: 0.7993 - val_loss: 0.4371 - val_acc: 0.8012绘图比较
分别绘出训练数据和测试数据的loss值与准确率。
%matplotlib inline
import matplotlib.image as mpimg
import matplotlib.pyplot as plt
#-----------------------------------------------------------
# Retrieve a list of list results on training and test data
# sets for each training epoch
#-----------------------------------------------------------
acc=history.history['acc']
val_acc=history.history['val_acc']
loss=history.history['loss']
val_loss=history.history['val_loss']
epochs=range(len(acc)) # Get number of epochs
#------------------------------------------------
# Plot training and validation accuracy per epoch
#------------------------------------------------
plt.plot(epochs, acc, 'r', "Training Accuracy")
plt.plot(epochs, val_acc, 'b', "Validation Accuracy")
plt.title('Training and validation accuracy')
plt.figure()
#------------------------------------------------
# Plot training and validation loss per epoch
#------------------------------------------------
plt.plot(epochs, loss, 'r', "Training Loss")
plt.plot(epochs, val_loss, 'b', "Validation Loss")
plt.figure()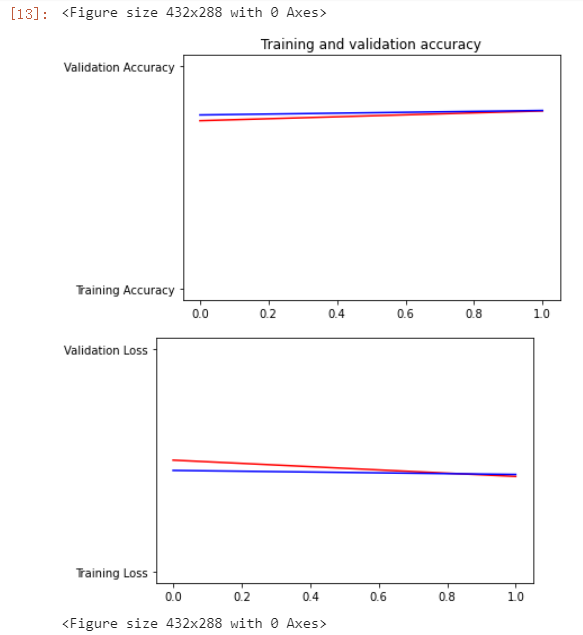
进行预测
import numpy as np
from google.colab import files
from keras.preprocessing import image
uploaded = files.upload()
for fn in uploaded.keys():
# predicting images
path = '/content/' + fn
img = image.load_img(path, target_size=(150, 150))
x = image.img_to_array(img)
x = np.expand_dims(x, axis=0)
images = np.vstack([x])
classes = model.predict(images, batch_size=10)
print(classes[0])
if classes[0]>0.5:
print(fn + " is a dog")
else:
print(fn + " is a cat")
Comments NOTHING