


CNN
CNN:即Convolutional Neural Network,卷积神经网络。
1.Why CNN for Image?
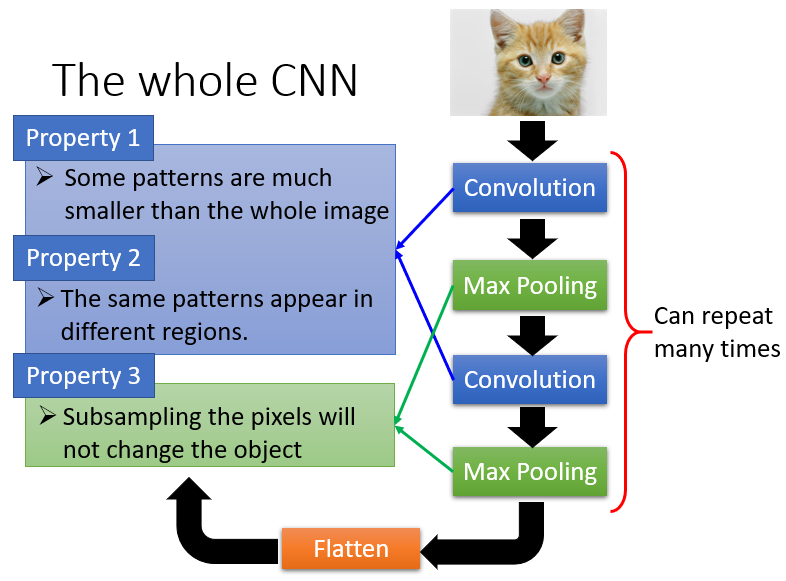
①.Some patterns are much smaller than the whole image.
一张图仅凭一块可能就可以进行识别,就具有明显的特征,例如下图识别这是一只鸟可能只需要鸟嘴部分,而不需要整张图。

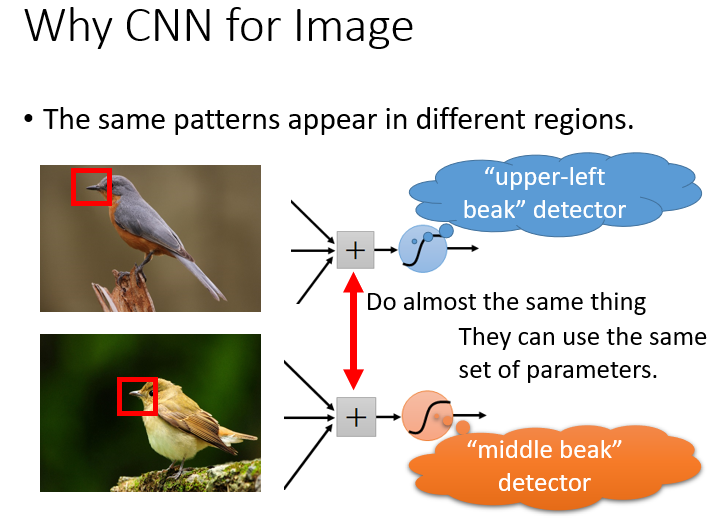
②.The same patterns appear in different regions.
且这个特征在不同位置上具有相似性,识别时可以进行复用。
③.Subsampling the pixels will not change the object
从图片中拿掉一部分像素,不影响整体的识别。

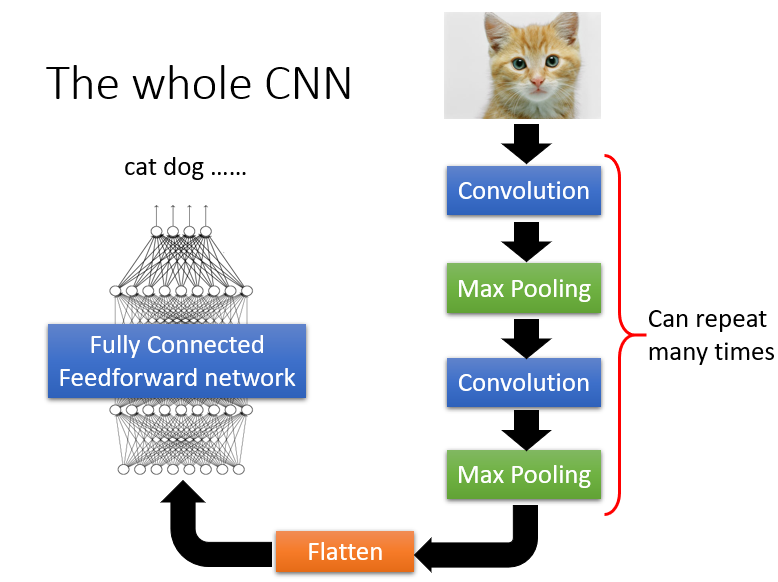
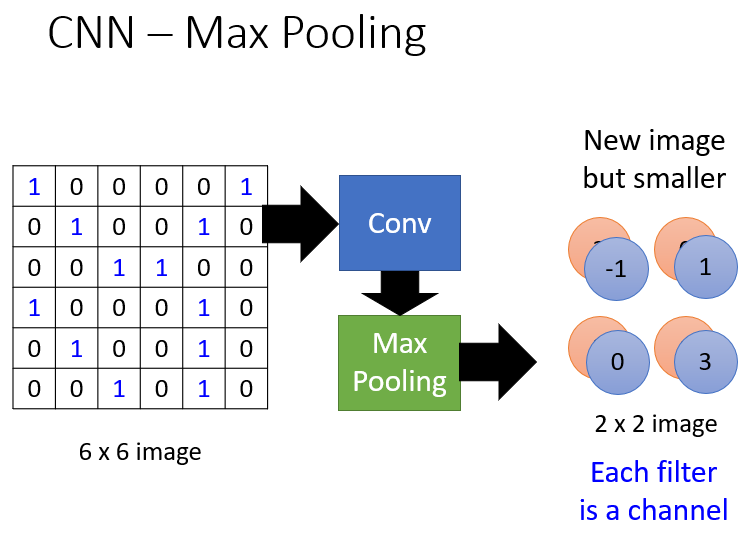
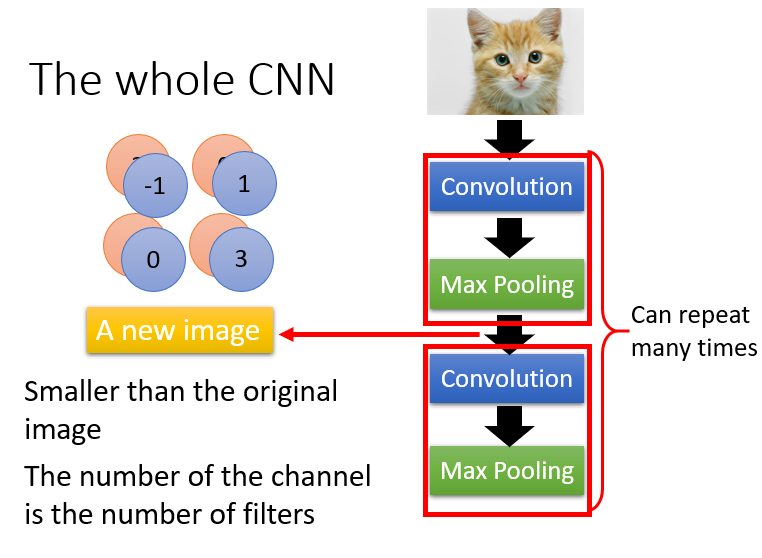
2.一个完整的CNN,流程如下图:
多次进行卷积选最大值,最后拉直,塞到一个大型的NN中。
其中Convolution主要针对上面图片识别的①和②,而Max Pooling只取最大值做的就是③。
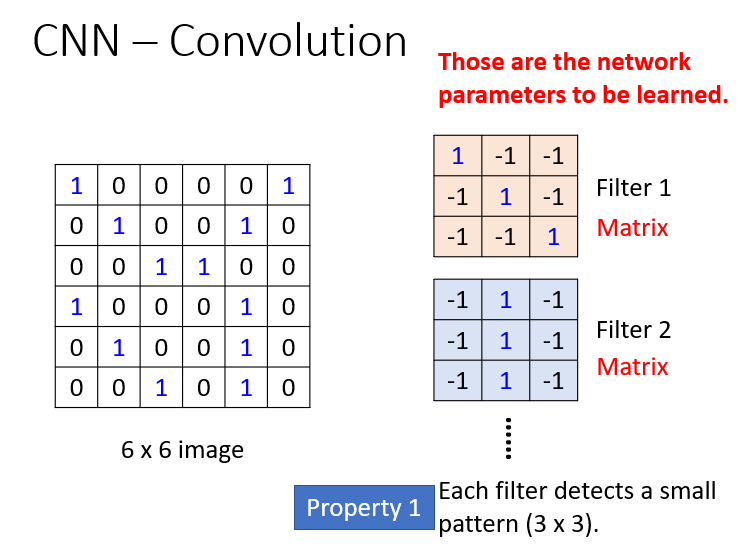
3.Convolution
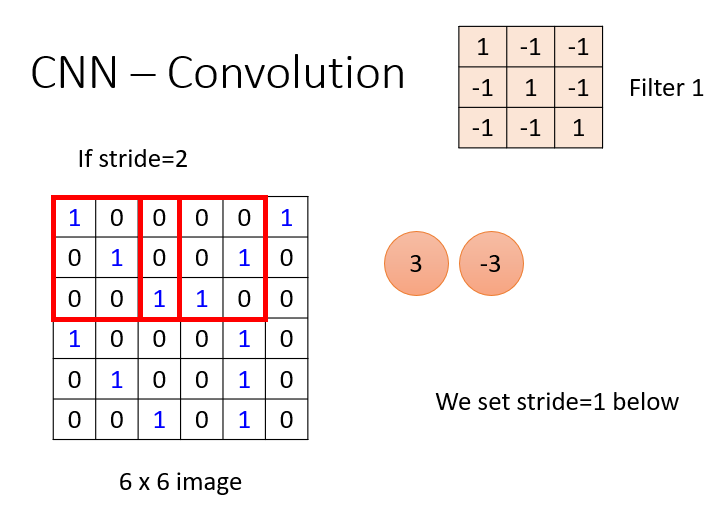
Convolution主要的工作是用过滤器(代表一个特征)去检测局部特征。它实际进行的是和与它大小一致的局部区域做内积,然后不断移动,直到与所有局部区域都做一遍。
这样即考虑到了上面的①局部特征识别,还考虑到了②不同位置相同的特征内积完结果一样。
就是下面的结果:
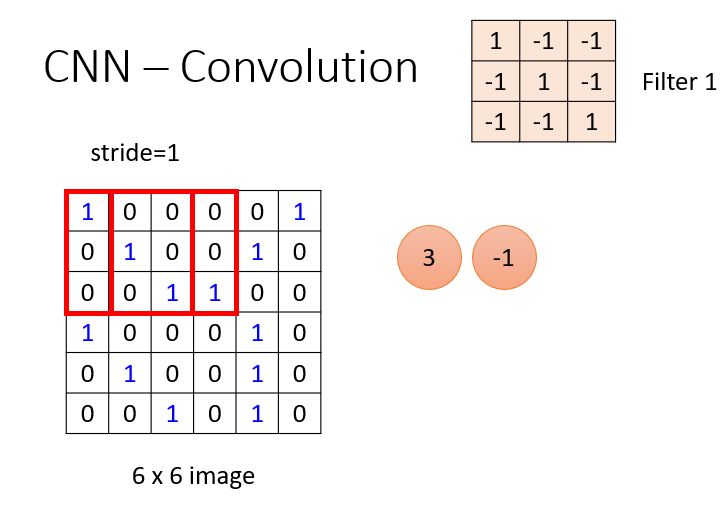
全部积完会得到一个相识度的矩阵,数字一样就代表在这两个位置特征一样。
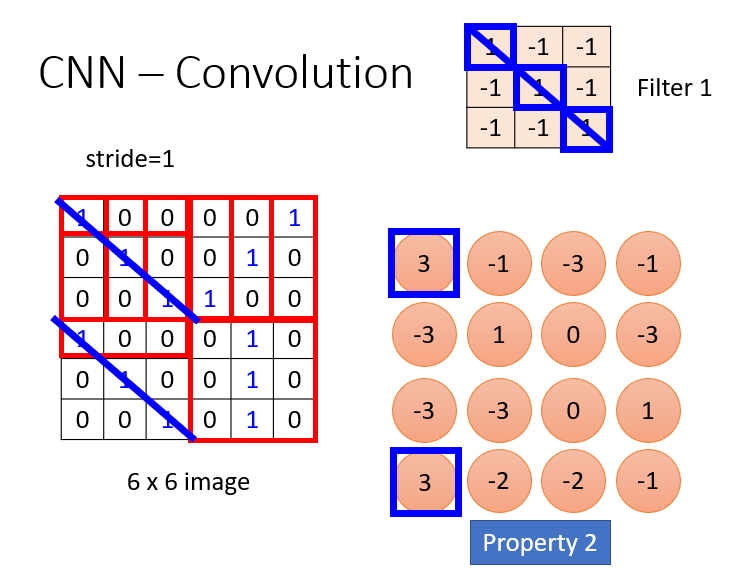
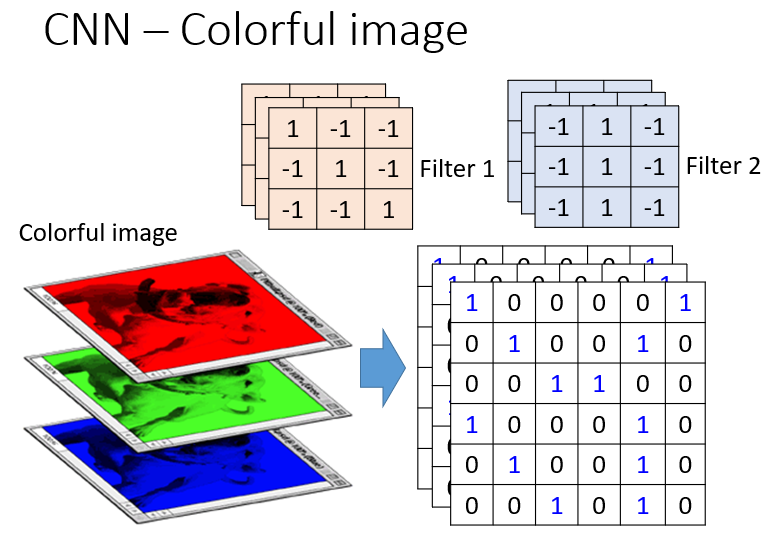
这时候如果有第二个过滤器,即第二个特征,它也会也形成一个矩阵,一样的步骤,这两个特征形成的结果合起来叫做Feature Map。
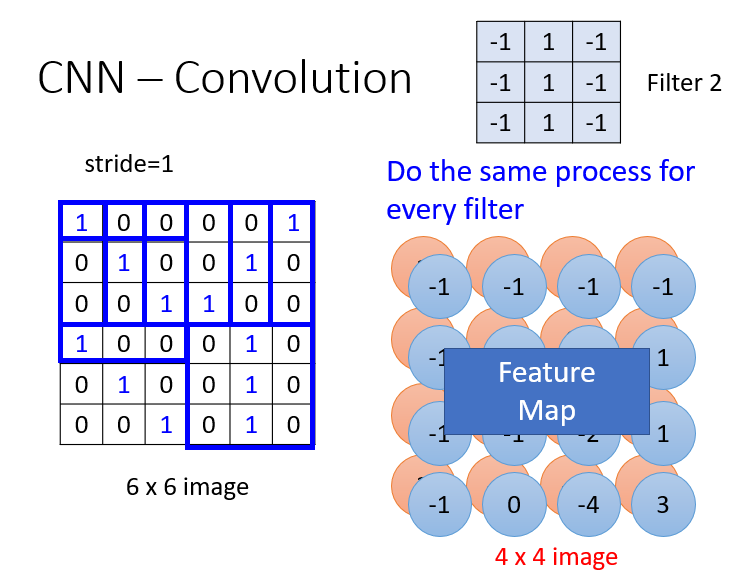
对于图片识别来讲他的过滤器可能就是三维的,但是算的时候还是用9个值做内积,而不是把R,G,B分开来算。
4.Convolution与Fully Connected的区别
乍一看,好像没什么关系。
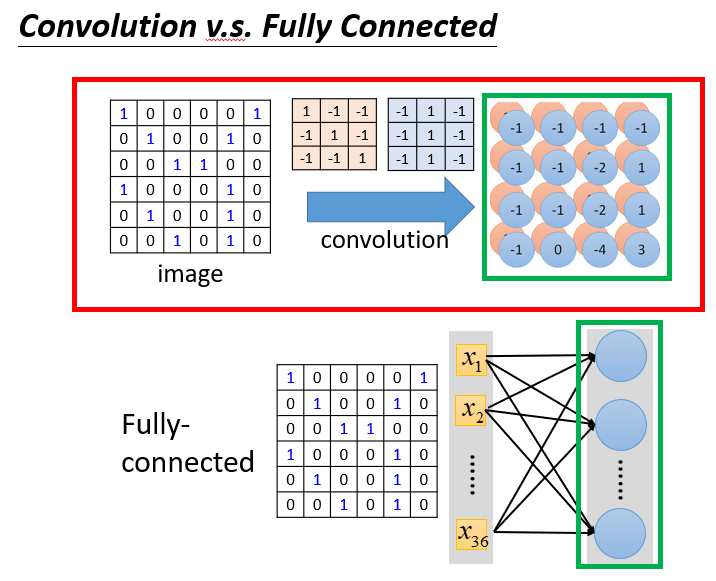
但是如果你把原数据的矩阵进行拉直,展开,把结果也拉直写在右边。会发现它是一个不完全连接的神经网络,过滤器作为所有神经元共用的权值。
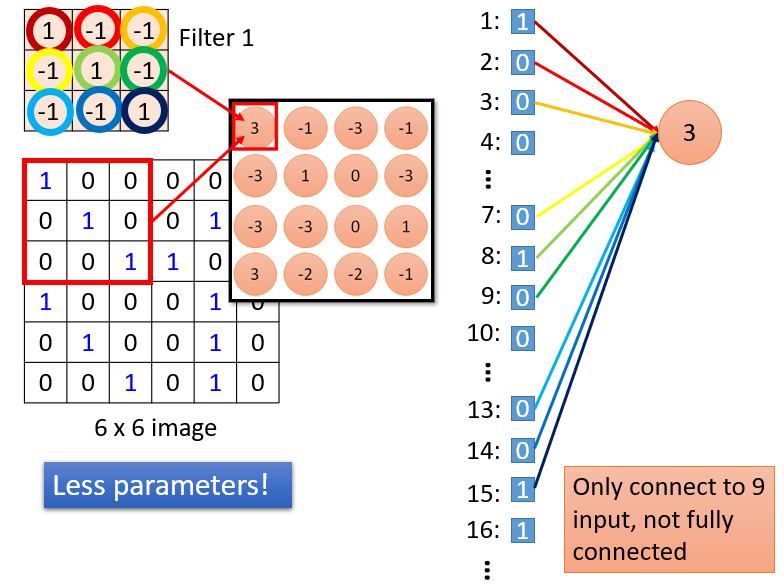
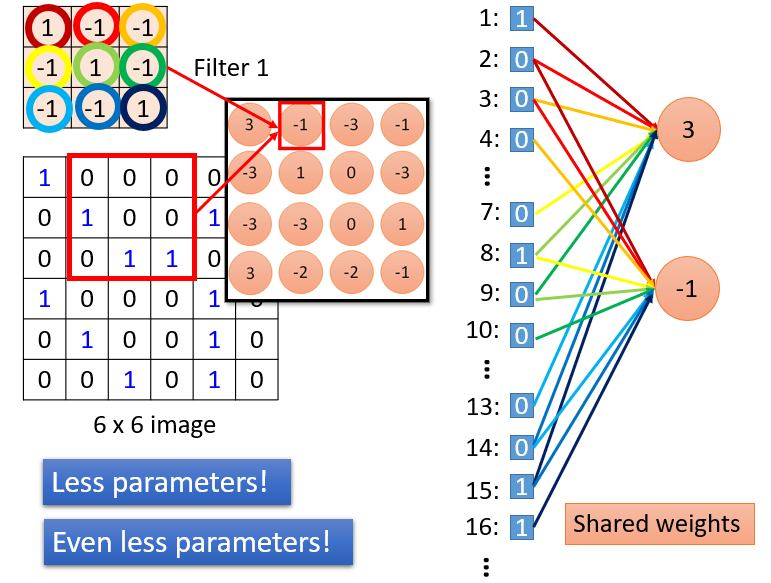
前面学习过全连接的网络,参数过多,这里不仅没有全连接以减少参数,最重要的是所以神经元共用一组参数,妙哉!
5.Max Pooling
所谓的Max Pooling,即在得到的结果中只选择值最大的(最相似的)进行保留,以减少参数,与上面的③对应。
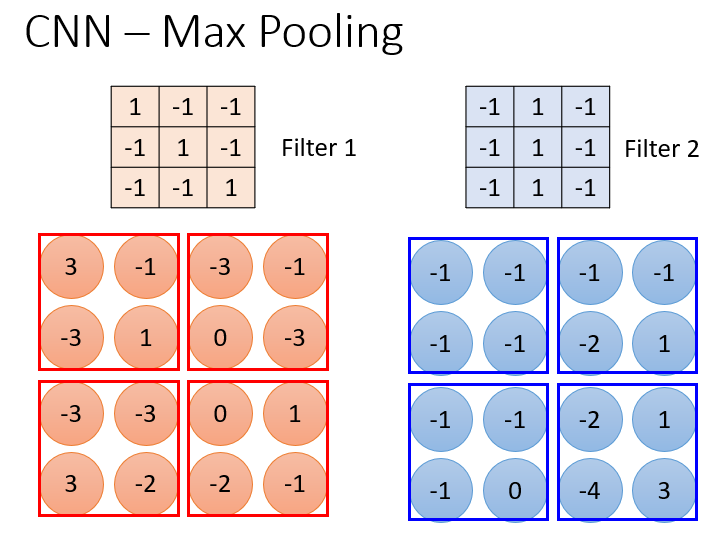
最终可以使问题简化。
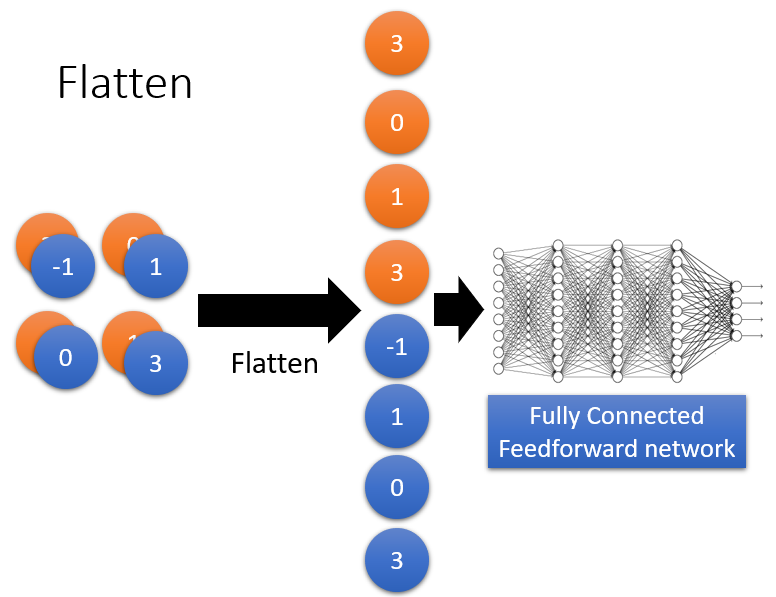
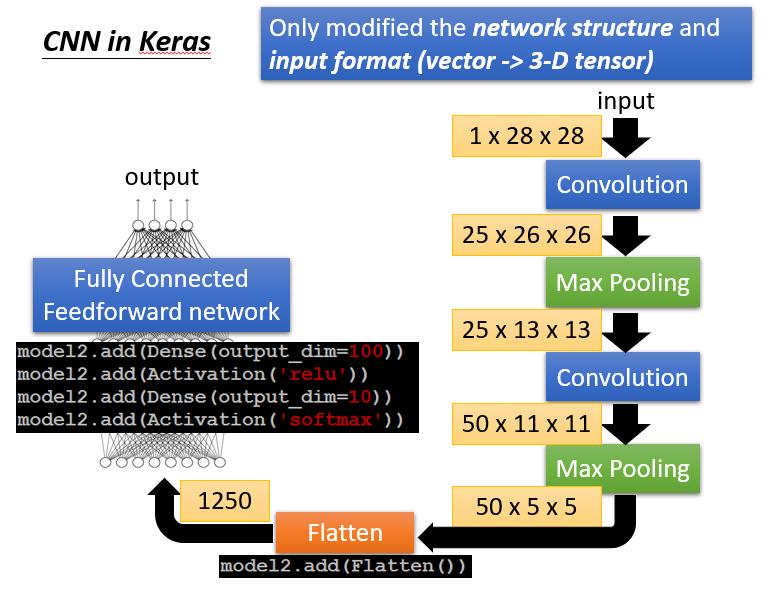
6.Flatten
在进行完上述操作,就可以把处理完的数据塞到一个NN里进行训练了。
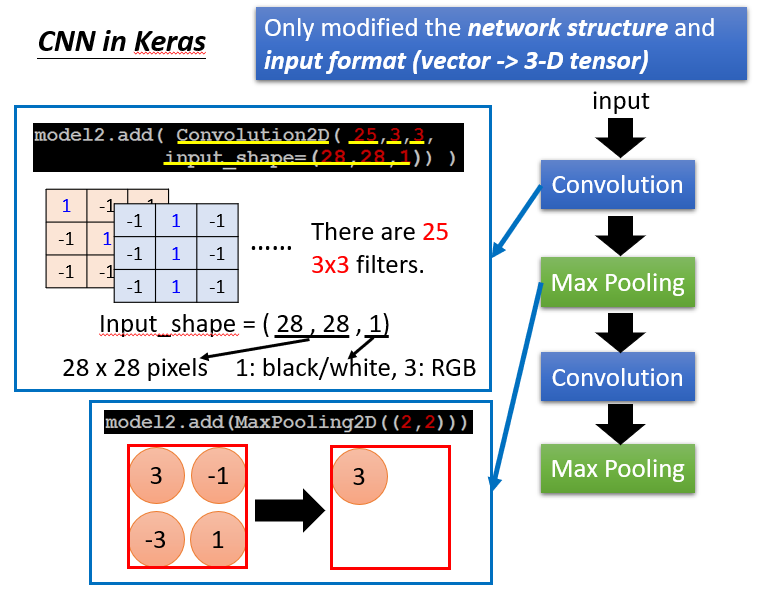
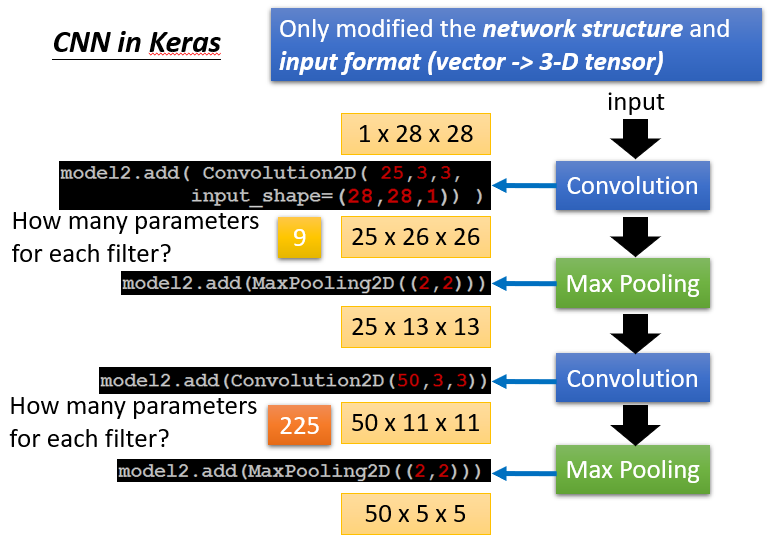
补充:在Keras中进行CNN的具体实现
Thinking About CNN
1.What does CNN learn?
*假设经过特征过滤后输出的是一个1111的矩阵,定义这个特征的活化度为其中所有值的和,现在我们要找一个输入数据(图片),来使下面这个活化度最大.**
这个图片用Gradient ascent算法来找,即梯度上升算法。找最大用梯度上升,最小用梯度下降。
与前面学习算法相比,该梯度算法是固定特征(NN中的参数),去寻找最佳输入数据;而之前学的是对应固定的输入数据,去寻找最佳的参数。
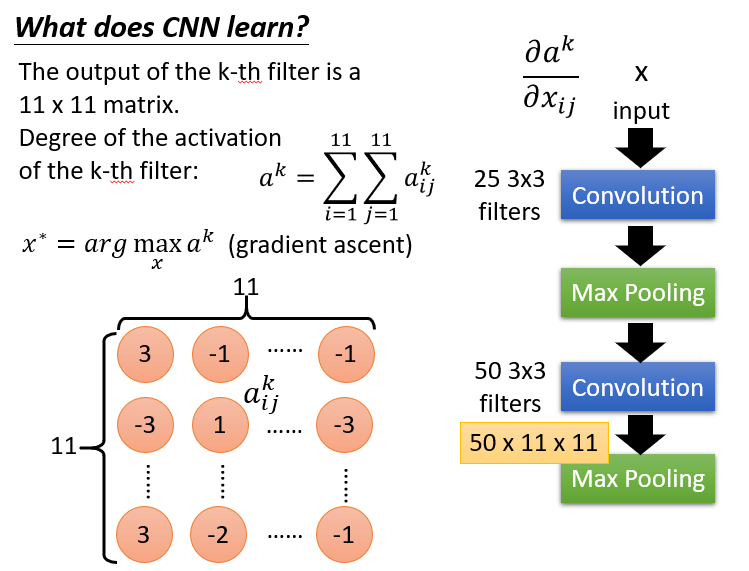
假设有50个Feature,我们就能找到50个最佳图片,我们发现对应不同特征它们纹路很有自己的特点
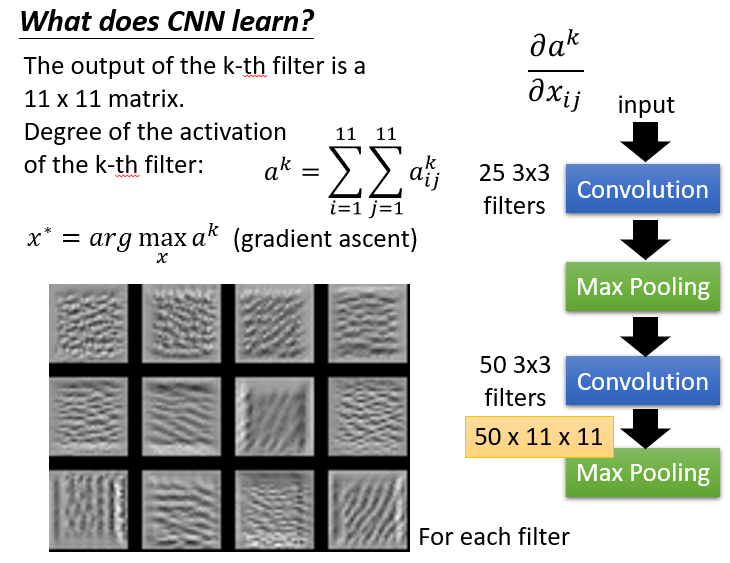
当加上最后的NN之后,在中间层,再次用梯度上升算法寻找最佳图片,我们会发现纹路和刚才很不一样。
这是因为加上后面一部分,用最后NN的输出来train的话,对应的就不是某个具体的特征了,它看的是一整张图。

最后,我们直接来到输出层(最终分类层),进行整体寻找最佳图片。它可能得到的就是下面的东西了,看起来很乱,和它识别出来的东西(猫狗之类的)差别很大。
所以没有关系,CNN有自己的一套东西,和人类所学的完全不一样。
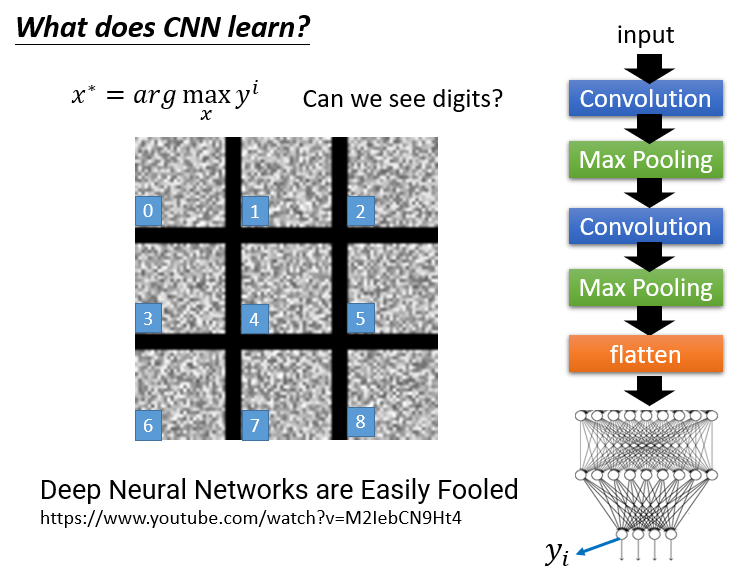
我们可以做一些优化,限制。比如手写数字辨识,有像素的点可能只集中在某些区域;但有一些明显不是数字,满屏像素的图还能让y很大,这种情况就要去除。直接在后面减一个像素点的数量就可以解决了。

2.Deep Dream

给定一张图,CNN会夸大它所看到的东西。就像上面的图片来说,经过处理后,它可能会看到新的东西,如下图:

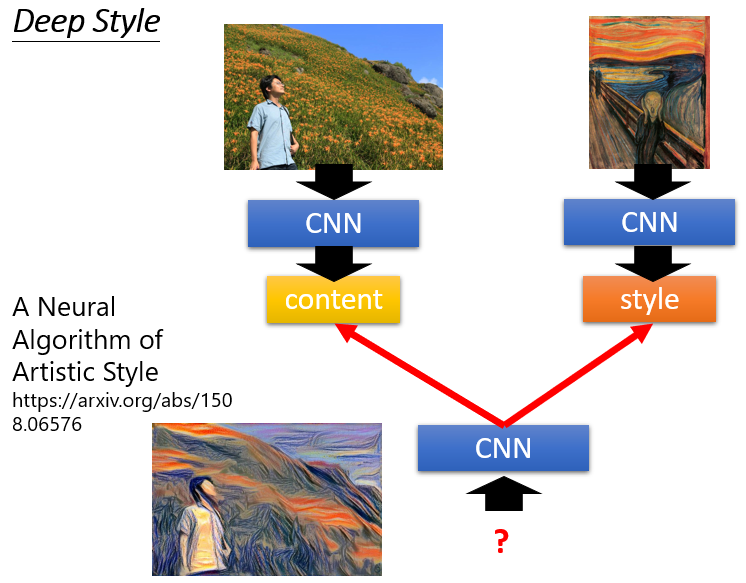
Deep Style
CNN可以帮助改变一个图片的风格。


它可以得到一张图片,其中的内容与风格来自不同的图片。
More Application
1.Playing Go
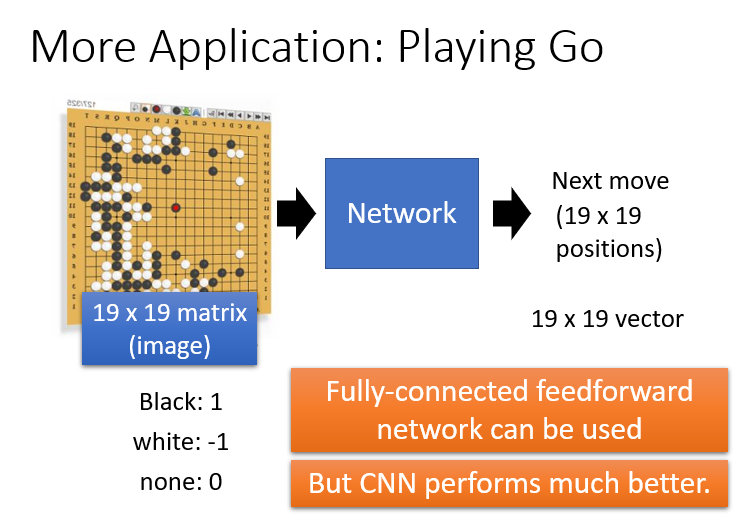
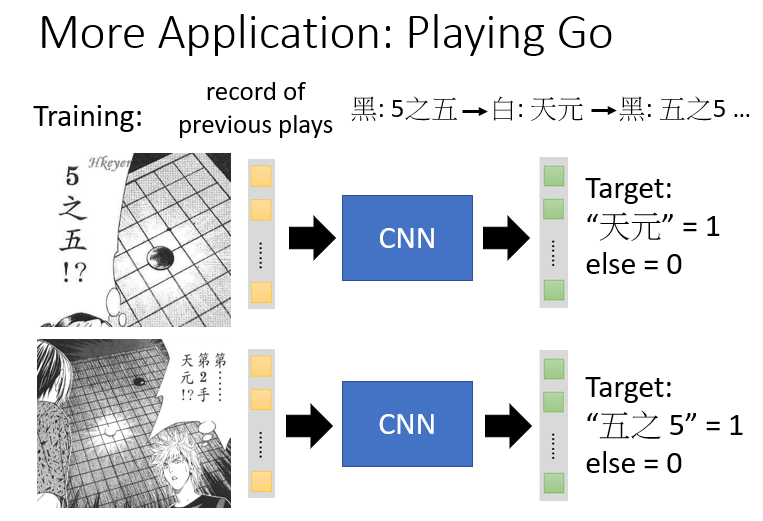
虽然围棋和图片一样具有局部特征性,和特征相似性,满足①和②。但是它好像并不能满足③抽掉一部分棋子还能保证稳定。

其实翻看α狗的开发记录,并没有发现它进行一个maxpooling操作,即它依然是一个基于CNN的项目,只进行了①和②而已。

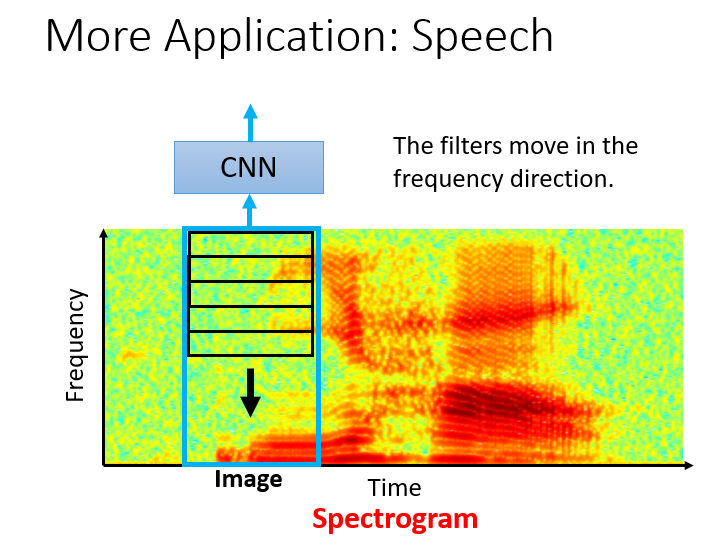
2.语音识别
下图为“你好”的频率-时间图,可以借助CNN对其进行分析。
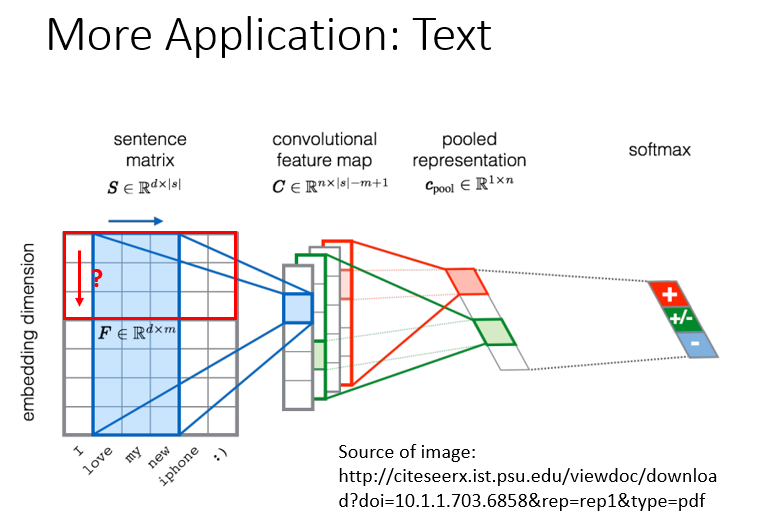
3.文字识别
CNN在文字识别方面也具有很多的应用。
Comments NOTHING