


Tips for Deep Learning
我们前面说过,进行一个Deep Learning也是分三步走。
如果在Training Data不能取得一个好结果,那们我们必须要回头了。
如果在Training Data上可行,但是在Testing Data上并不能取得一个好结果,它就是过拟合的,我们也不得不回头进行调整。
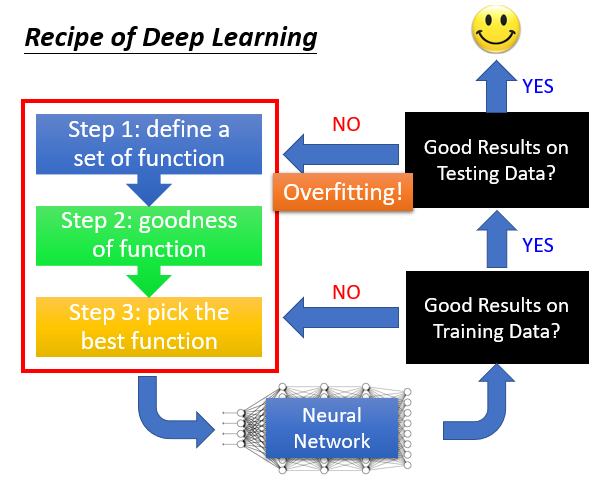
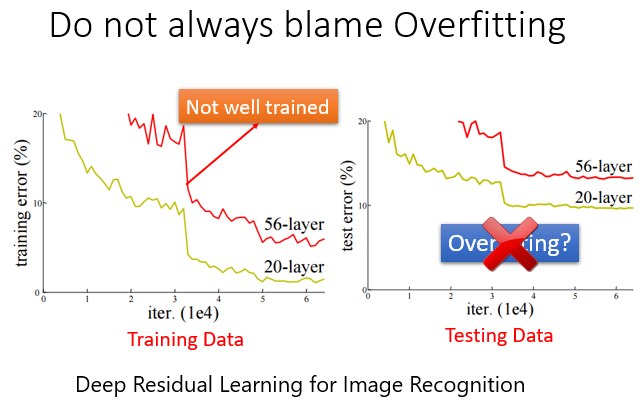
在深度学习中,选用更多的参数然后Testing时效果变差,并不一定是过拟合导致的,也有可能他在Training Data上的效果就不太好,也就是没有被训练好。
所以我们要弄清楚问题,针对不同问题用不同的方法去解决。
比如DropOut方法就能在Testing Data上面有更好的效果。
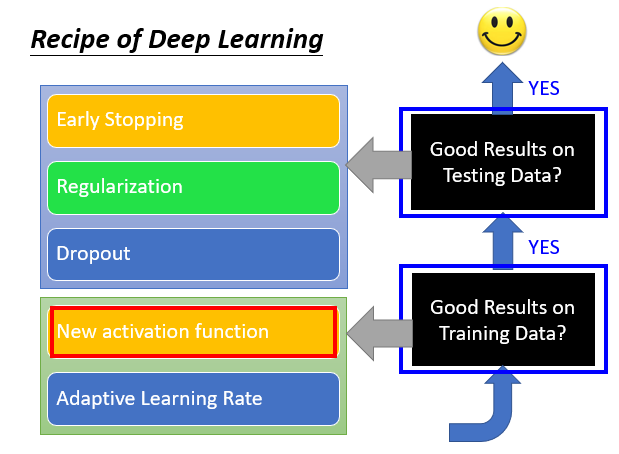
优化方法
1.New activation function(Training Data)
例子:在手写辨识中,并不是我们NN的层数越深Training Data效果就越好,这是为什么呢?
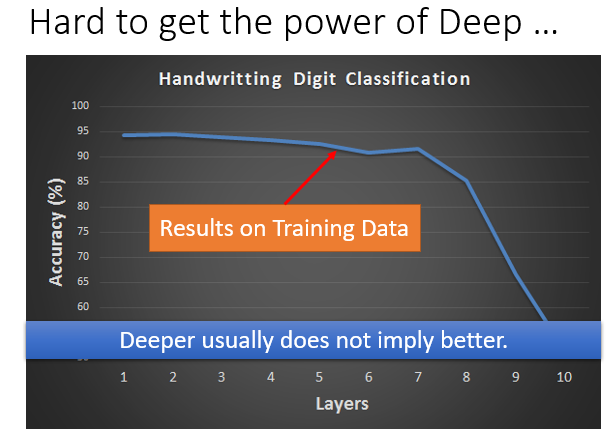
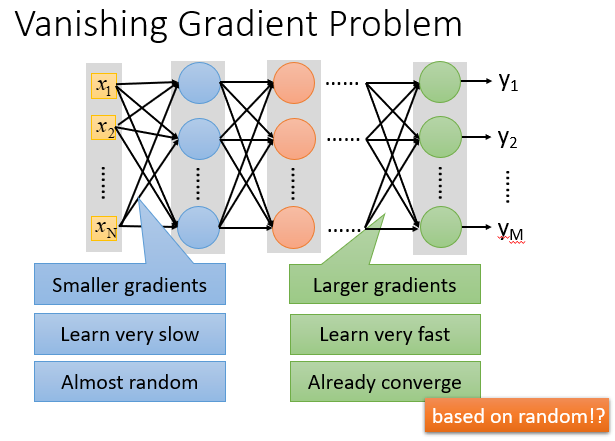
因为在我们计算损失函数对参数的导数时,靠近前面的层里面的参数对结果影响较小,几乎就不怎么动,到最后就可能是一个随机的值。
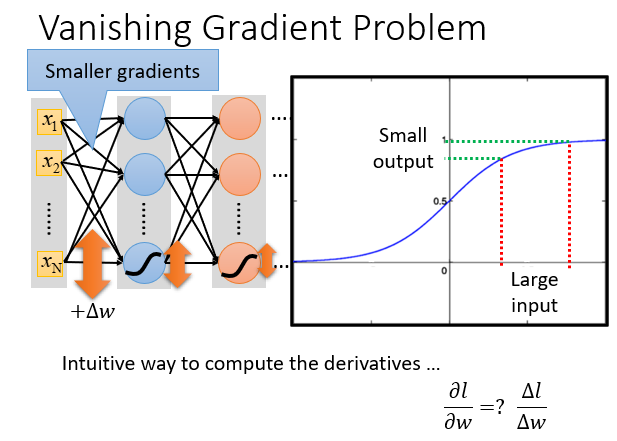
因为一个是σ函数的输出是0-1,前面层输出的结果会经历很多的σ函数,它们对结果的影响逐渐缩小,到最后就可以忽略不计。
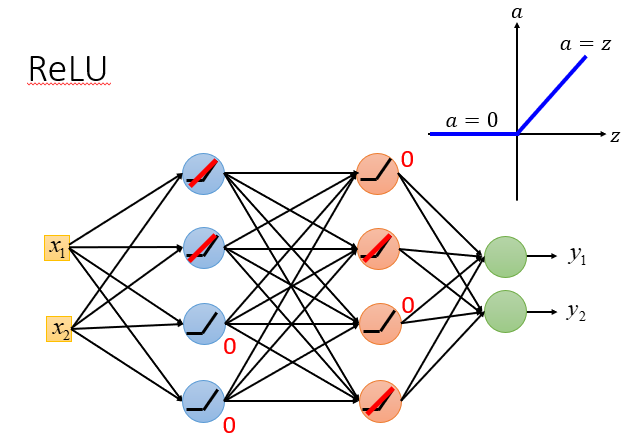
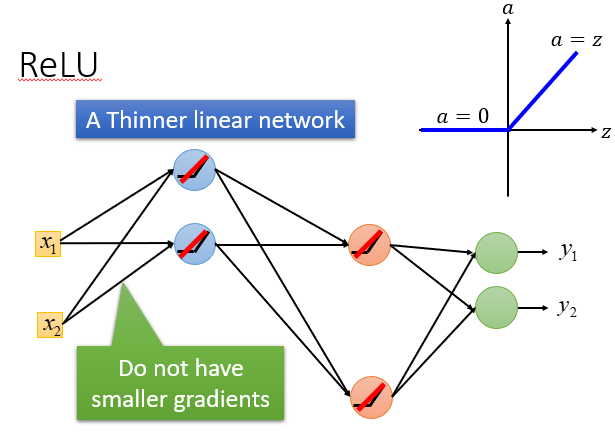
可以选用修正线性单元ReLU,它是一种激活函数。
使用它的好处有很多,例如方便计算之类的,但是它最重要的是能解决我们上面提到的问题。

它可以"舍弃"一部分输出小于0神经元,也可以解决靠前层次影响被缩小的问题,它的输出会和输入成正比,而不会进行压缩。
为了使一些输入小于0的神经元上的参数也能得到调整,我们可以使用带参数的Relu,使其在小于0上也能有一个很小的值。

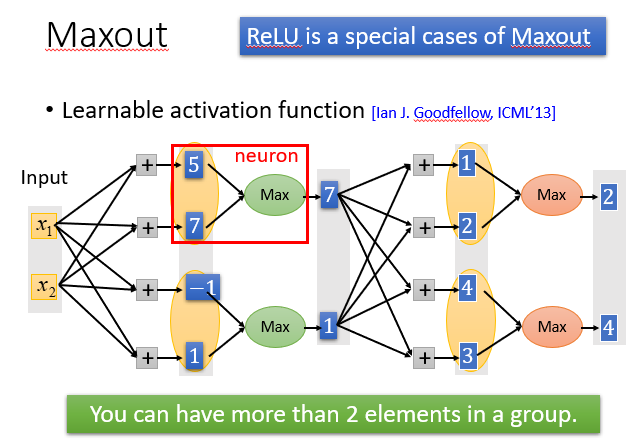
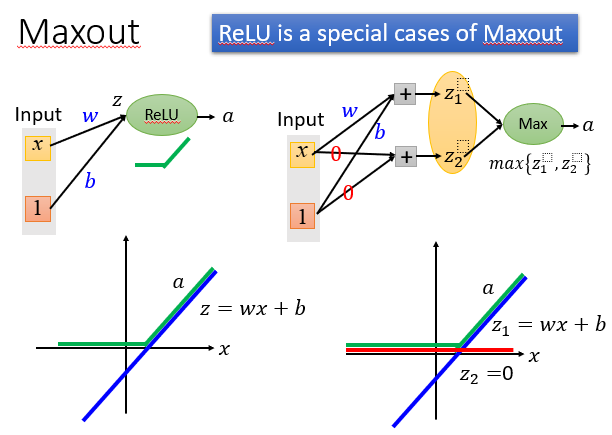
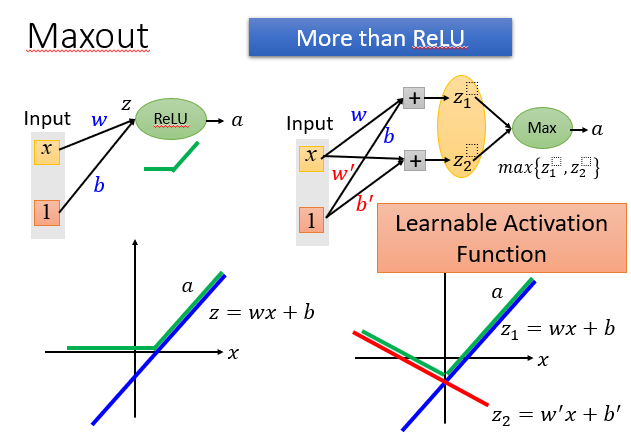
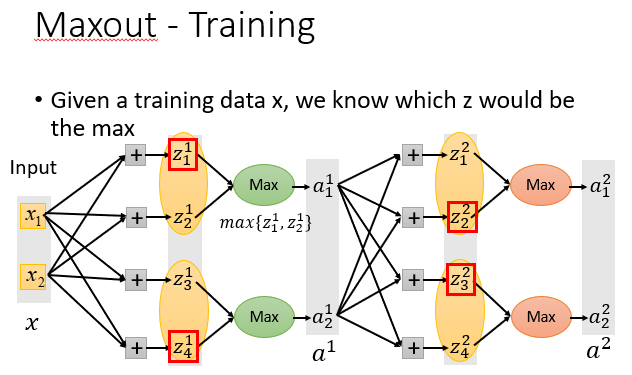
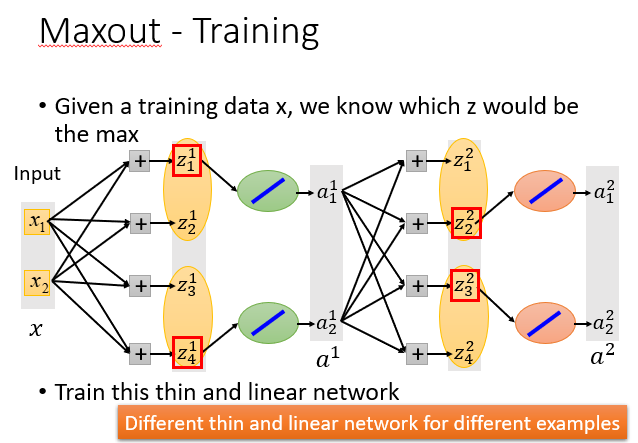
可以使用Maxout激活函数,它比ReLU功能更强大,可以说ReLU是一种特殊的Maxout。
它可以有输入两个或以上输入,然后选择最大的输出。
正如上面提到的,它可以做到和ReLU一样的效果。
它还能进行各种其他的输出,你可以控制它为你想要的线性输出,取决于你塞进去输入的数量。

虽然一次只会训练输入MAX的对应的参数,但是你并不是只有一个训练数据,所以所有的参数都能被训练到,这是不用担心的。
2. Adaptive Learning Rate(Training Data)
我们先回忆一下前面的Adagrad方法,就是下面含有均方根的参数变化式。
它让参数的变化在对整个实验影响小时,它有更大的变化速率。
对实验影响小时,它就会有更慢的变化速率。
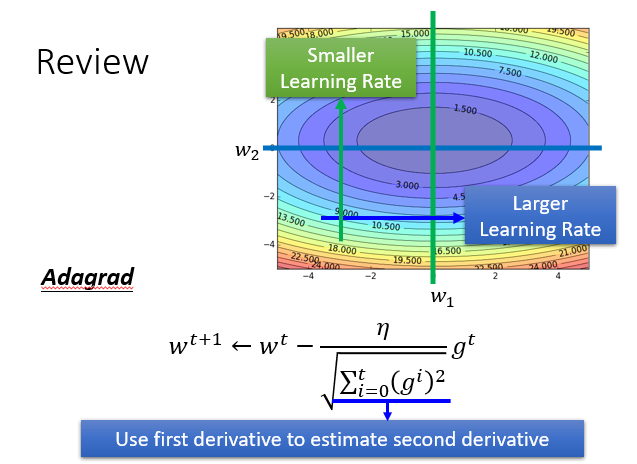
但是我们的Adagrad存在一个问题,在深度学习中,一般都会面临大型的NN,参数众多,他的损失函数也会很复杂,你可能需要频繁改变你的学习速率,Adagrad并不一定能办到。
我们提出RMSProp方法
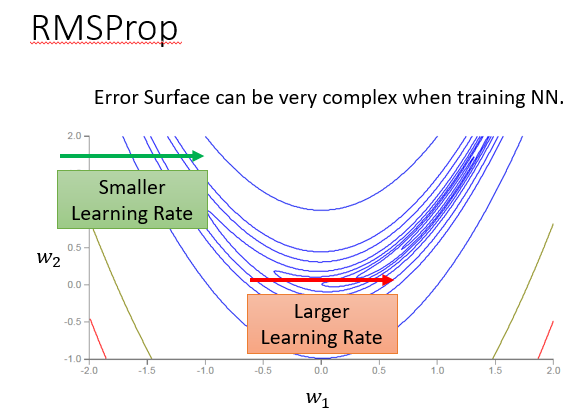
不再采用均方根,而是下面这种,它会对之前的微分进行一个权值衰减。

除此之外,我们还会遇到之前说过Local minima的问题,它甚至会停在一个连local minima 都不是的地方。
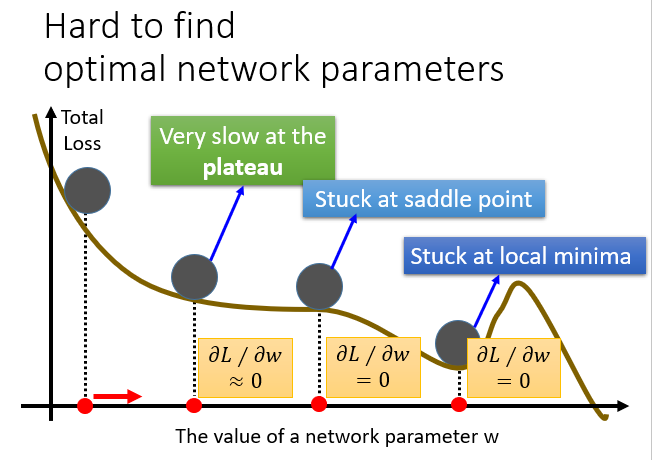
为了解决这个问题,我们引入物理中的惯性思想。
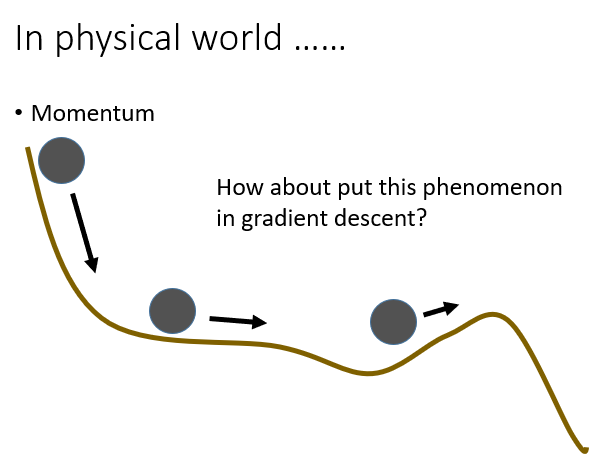
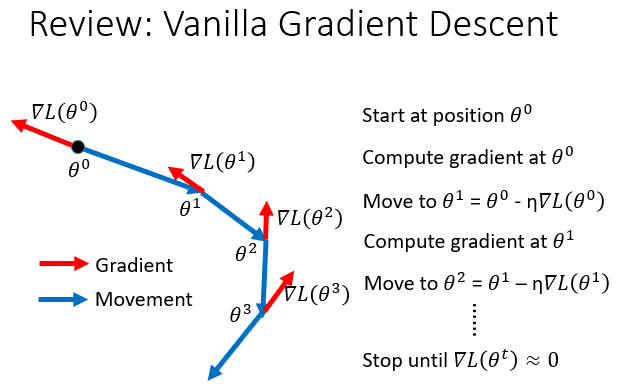
所以在某一点的前进方向同时受到当前的梯度和上一次前进方向的影响。
就是进行一个向量的和。
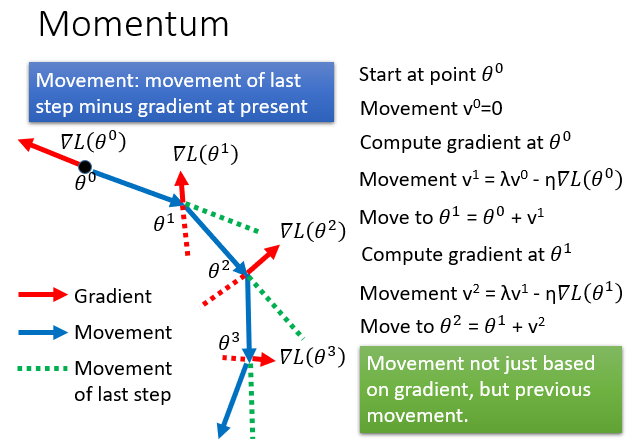

所以它不容易在一个微分值为0的点卡住,更有希望找到Local minima甚至是global minima。
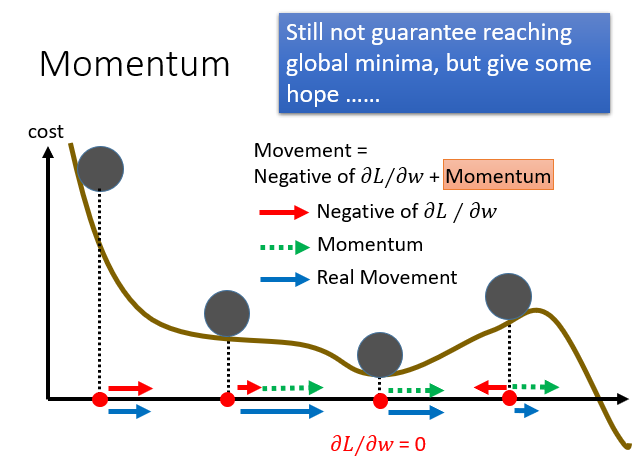
其实,把RMSProp和Momentum混合一下就是Adam,先了解一下。

3. Early Stopping(Testing Data)
可以让我们的Training早一点停下来,停在Testing效果最好的地方,但是我们不知道Testing Data 什么时候效果最好,只要拿出一些伪Testing Data来验证就行,可以是直接从Training Data 分出来的一部分。

4. Regularization(Testing Data)
前面提到,在损失函数后面加上额外带参项进行正则化,降低参数的影响,为了让这个损失函数更平滑。
可以选择加一个平方项,也可以加一个绝对值项。
区别:
- 平方项求完导,会形成一个百分比衰减,大的时候减少的很多,接近0时可以减少的很少。
- 绝对值项求完导,会进行一个值衰减(可以增加,因为绝对值求完导会出现1或-1)。
两种在不同时候有不同作用。

这里面有一个权值衰减的思想,前面的微分值相当于每一次都减少一定百分比,最后影响越变越小。


我们的人脑的神经元也会做一个权值衰减,当你长期不用的某个神经元,它就会退化。

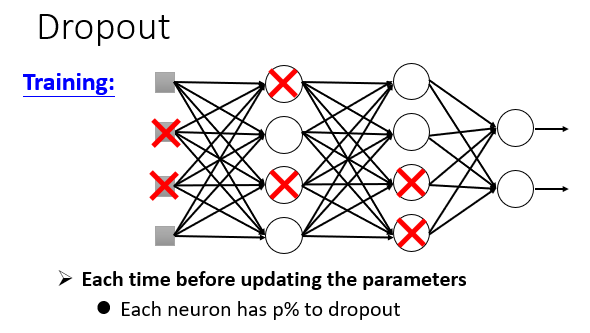
5. Dropout(Testing Data)
每次Train时,以一定概率p舍弃神经元,但因为训练数据很多,就相当于分批次训练。
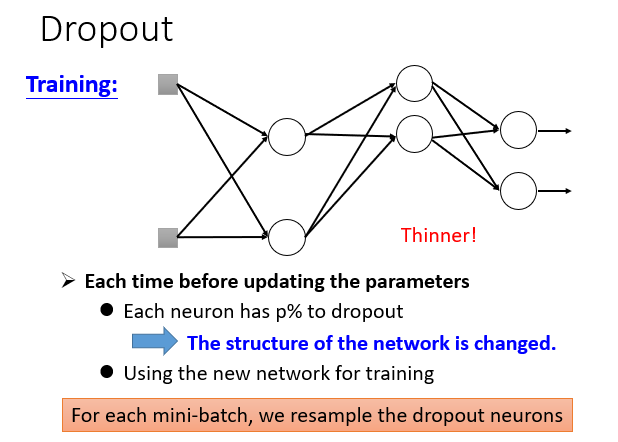
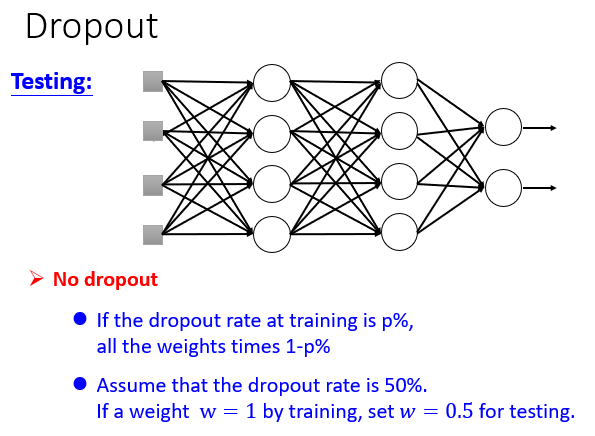
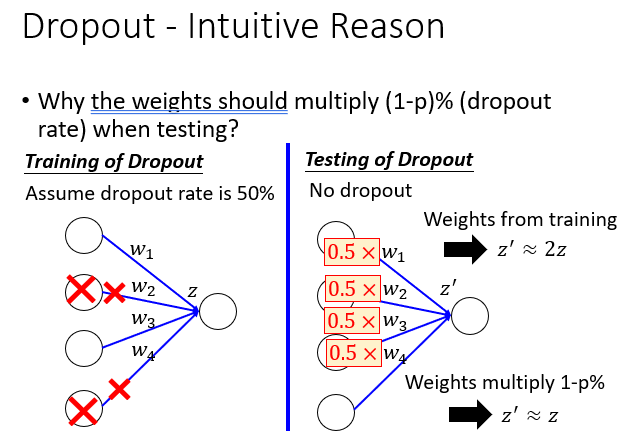
然后在用在Testing Data上,每个神经元乘以1-p。
问题1:为什么要Dropout?举两个简单的例子
带着重物训练,然后拿掉重物就会很强;在NN中也是这样,每次使用不完整的NN进行训练,最后使用完整的在Testing Data 上面就会更好。

一个小组的人都想单独完成某项作业carry队友,最后放在一起只会更强。
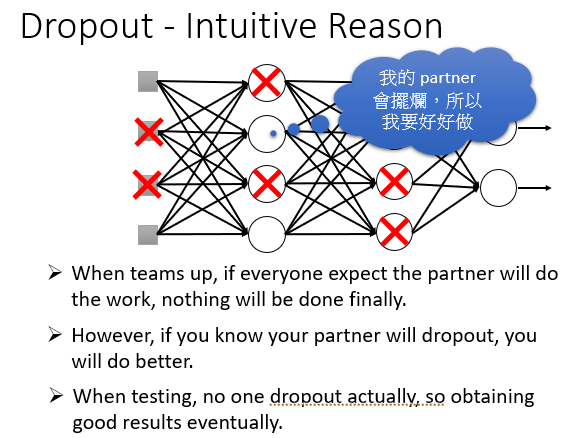
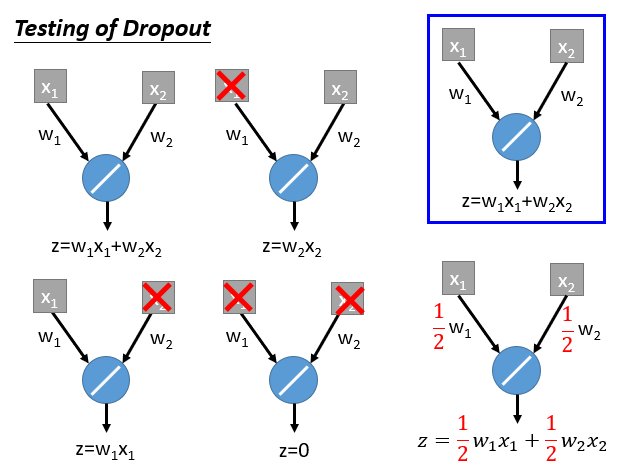
问题2:那么为什么最后用在Testing Data上面要乘以个1-p?
直接想,就是为了和一半时输入的值保持一致,让其从2z变为z。
其实对于上述两个问题,有专业的解释。
Dropput其实是一种复合效果。
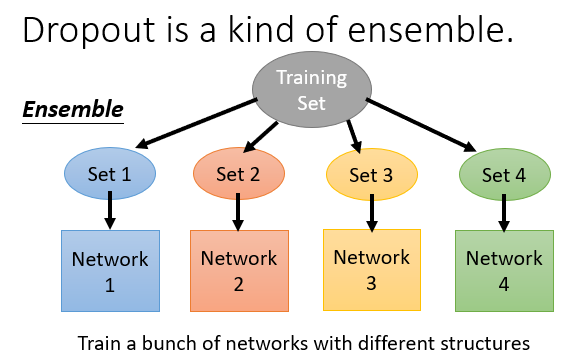
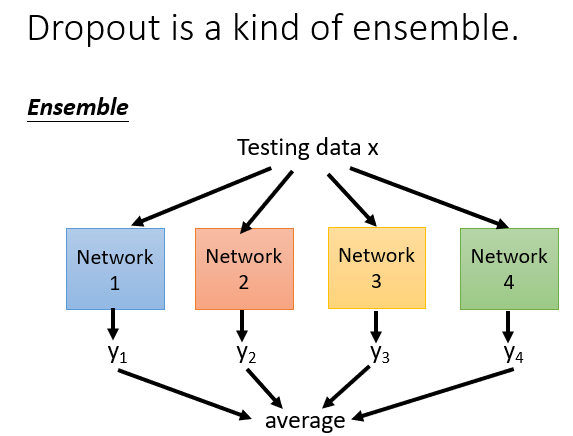
在训练时,每一个神经元有被选中和被丢弃两种状态,M个神经元就相当于是2的M次方个神经网络,效果可想而知。

而且在Testing Data的神经元的weights乘以1-p,会刚好约等于前面训练这么多次的一个平均效果。
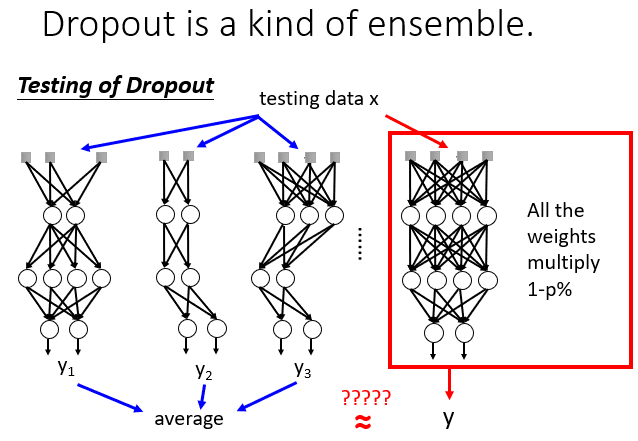
就像下面这个具体的例子。
Comments NOTHING