


Brief Introduction of Deep Learning
Deep Learning的现状和发展历程
时至今日,各行各业基本都涉及到了深度学习。如下图,2012年到2016年,深度学习技术的应用呈指数增长,现在肯定更加疯狂。
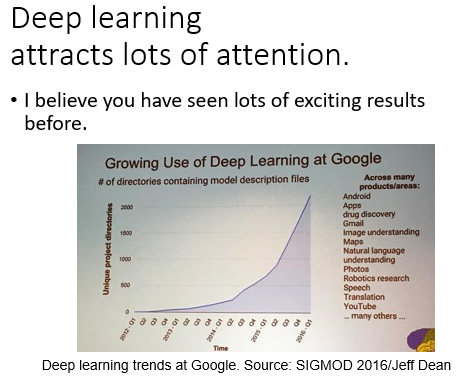
发展历程:

Deep Learning
我们可以采用之前的方法来做一个Deep Learning,先不要想得太过复杂。就是三步走:
- set a Model
- goodness of function
- pick the best function
Step 1: set a Neural Network
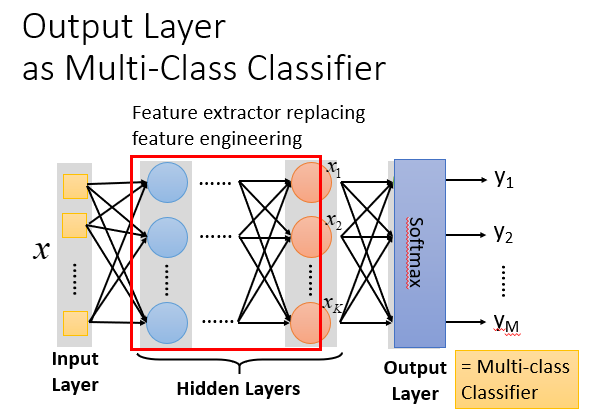
这第一步就是和之前差别最大的地方,Deep Learning会在这一步套很多层的function.这些function都有自己的参数w(weight),b(bias);这些function作为一个个"Neuron"(神经元)组成一张巨大的神经网络。
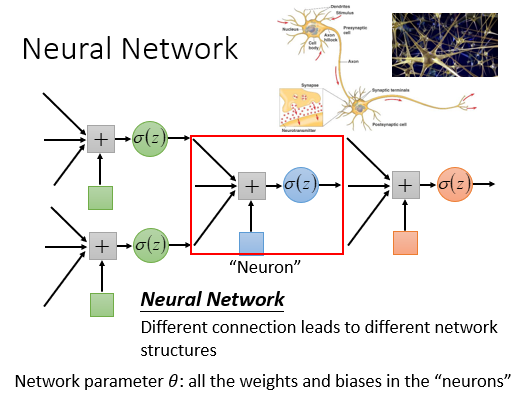
例如全连接前馈网络:
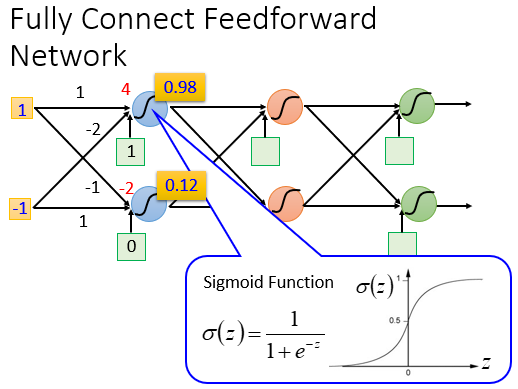
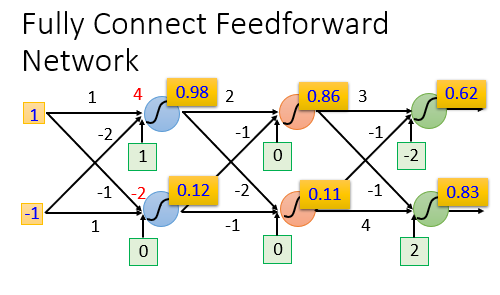
我们可以这样理解:整个神经网络是一个大型的function,我们输入一个Vector,它会输出一个Vector,达成我们想让它完成的工作。
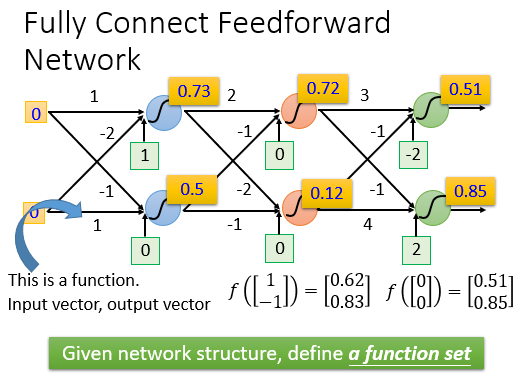
除去输入层和输出层中间的这些神经元层的层数就是一个Deep Learning的深度。

谁也不知道究竟多少层才能叫做深度学习,这个技术在不断深化。
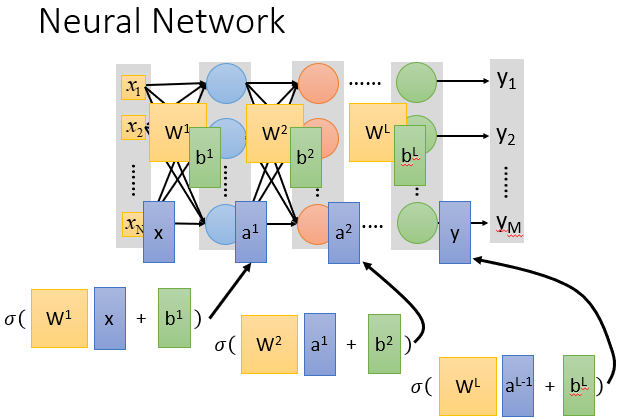
我们观察一个神经元对它的输入数据的处理,其实就是在做一个Matrix Operation(矩阵运算).

这一层做完矩阵运算的结果又会被当成下一层的输入数据,不断进行下去。
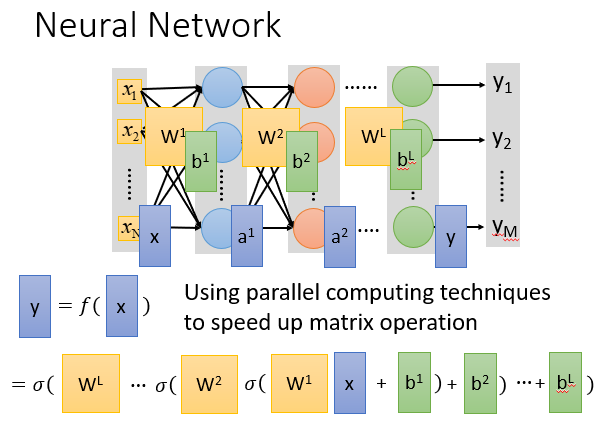
我们可以把这个套娃式的矩阵运算用一个f表示出来,所以说整个神经网络就相当于一个复杂的function,现如今计算机能使用GPU来加速这样的一个矩阵运算。所以我们即使设计很复杂的Neural Network也能在有限的时间内得出结果。
对于一个多元分类,更有必要使用Deep Learning来代替手动的feature engineering。
最后的输出层可能会设置一个Softmax来强化相似度。
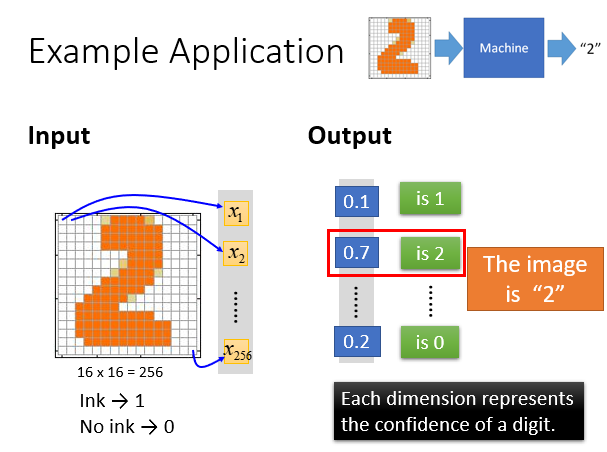
例如手写数字的辨识。
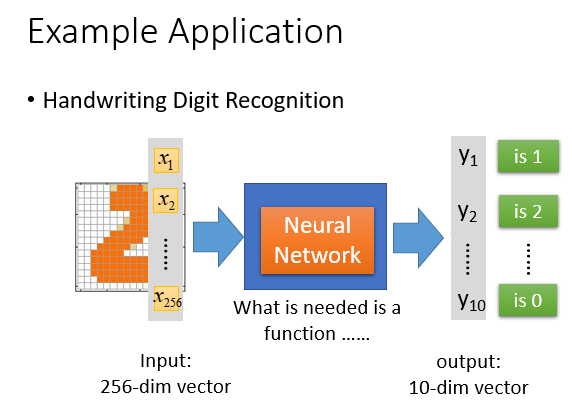
输入的是它的像素块占有情况的一个Vector,输出的是一个和各个数字相似度组成的Vector。
所以更直白得看出我们仅仅需要找一个Neural Network或者说是一个function.
你需要去设计一个Neural Network使这个function的效果最好。
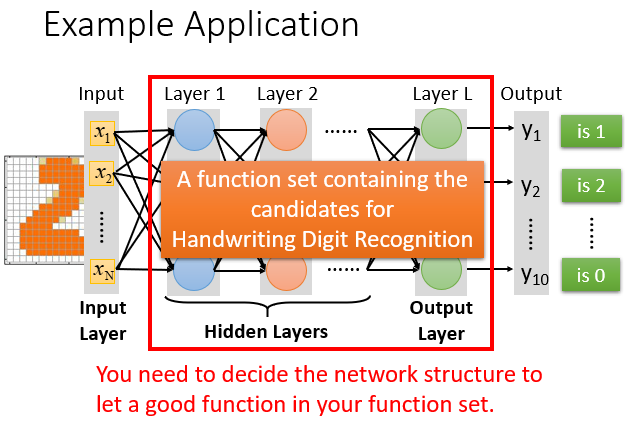
当然这并不简单,需要大量的实验和尝试,也需要你长期形成的一种直觉。
Step 2 :Goodness of function
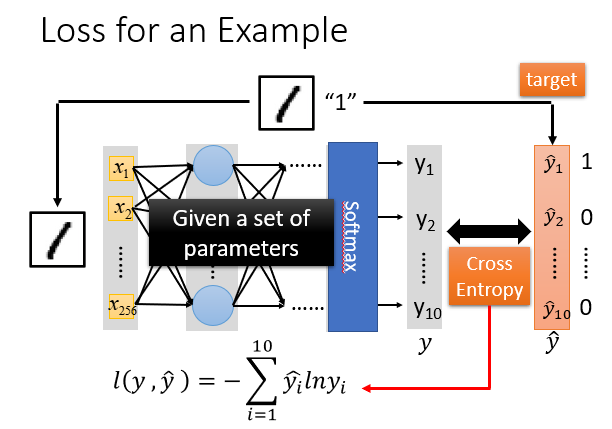
损失函数就定义为你得到的结果与目标结果的一个交叉熵。
以手写数字辨识为例:
你输入的是1,得到的是一个十维数组,里面装的是和各个数字的相似度;你的目标Vector肯定是一个1,9个0.交叉熵越小,这两个Vector就越接近,你就离目标越近。
当然一个手写数字是不够的,你需要一组手写数字,然后分别求他们的交叉熵,然后加在一起用总的交叉熵来当这个实验的损失函数。
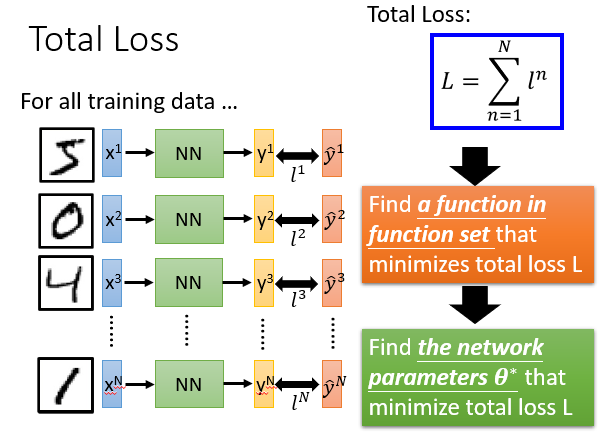
Step 3:求参,pick the best function
方法仍旧是我们学习过的Gradient Descent。
把前面神经网络中所有的参数列成一个大集合,然后逐一求偏微分优化。
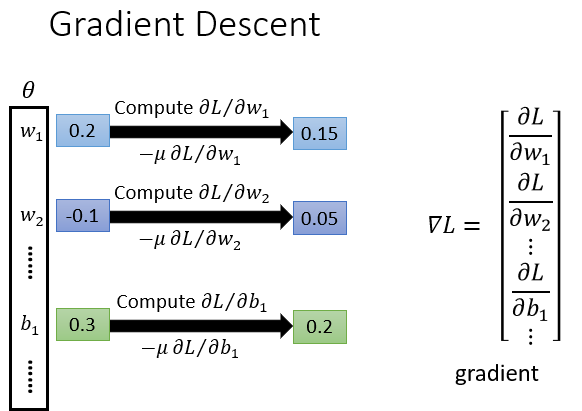

不要听到Deep Learning还是用Gradient Descent解出来的,就感到失落。
其实Alpha go这种也是用这种方法实现的。

在进行Deep Learning时,我们可能要进行大量的微分运算,其实现在有很多软件可以代劳,说不定一些DL大佬还真不会算微分。

Comments NOTHING