


21.Auto-encoder
Basic Idea
其实在BERT和GPT之前,就有一个不需要带标签数据就能训练的模型,它就是Auto-encoder。
所以它也是一种self-supervised的模型,虽然它出现的时候还没有这个说法。
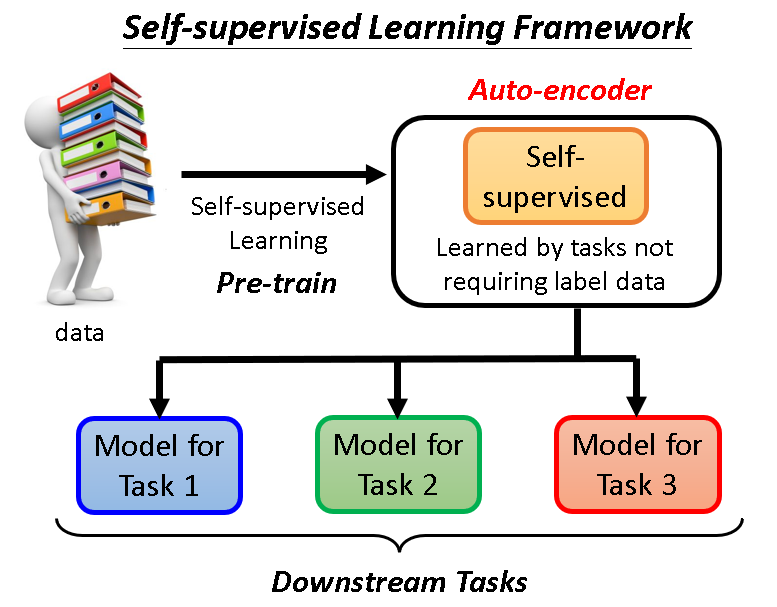
Auto-encoder是怎么训练的?
整个训练过程有一个Encoder和一个Decoder,Encoder负责把图片等输入转化为向量,Decoder负责把向量再变回去,这个恢复回去的输出和原输入越接近越好。
Auto-encoder做了什么?
Auto-encoder主要是对输入数据进行了表示,这种表示可以帮助降低维度。这样做的目的是为了化繁为简,一些表面复杂的东西可能可以简单被处理,更好地为下游任务服务。

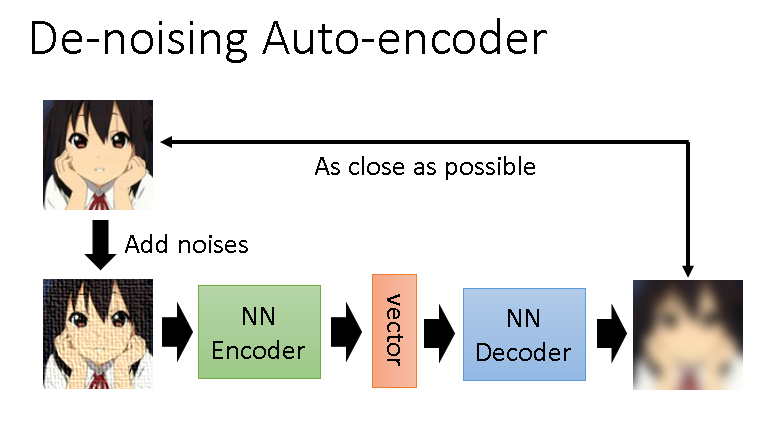
此外有这样一种能够去噪声的Auto-encoder,其中Encoder读进去的是带噪声的输入,然后Decoder要还原为不带噪声的输入数据。这就需要Encoder和Decoder联手把噪声去除。其实仔细想一想BERT是不是就是一种De-noising Auto-encoder,它能填补句子的空缺部分。
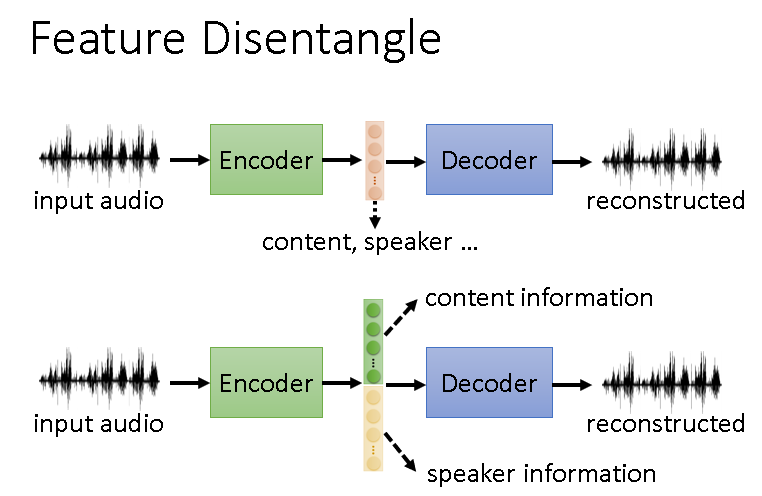
Feature Disentangle
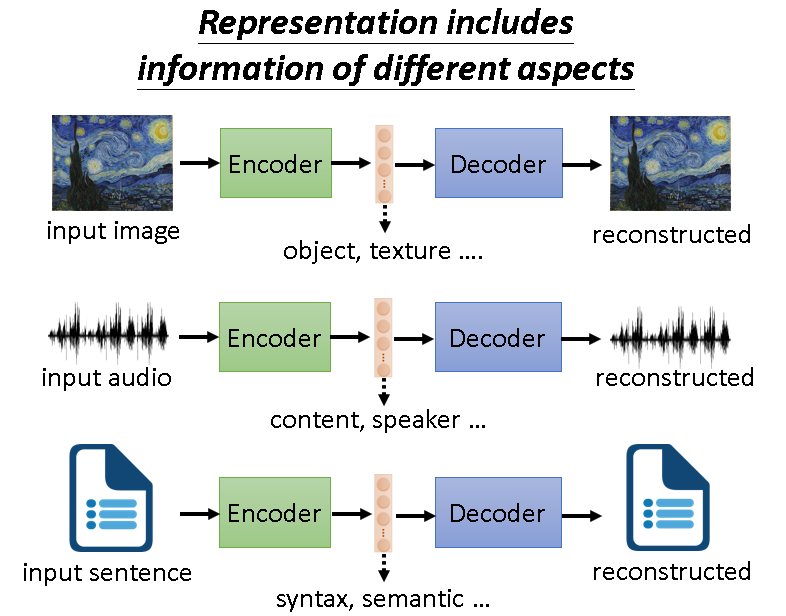
原输入数据经过Encoder之后生成的向量Vector中必然包含很多信息,因为它能被Decoder还原回去证明了这一点。
那么此Vector中包含的信息能不能进行区分,以方便后续使用?
当然是可以的,这也是Auto-encoder最主要的用途之一。
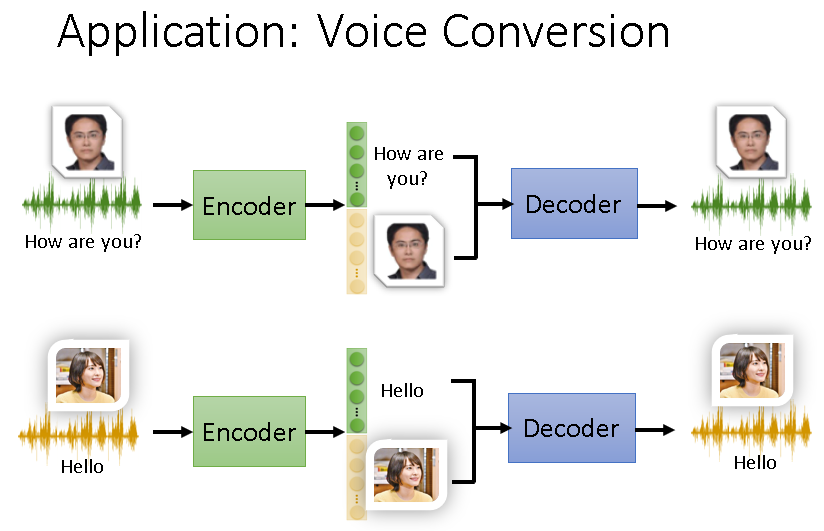
比如对语音做Auto-encoder,生成的Vector就包含内容和说话人说话的特征。如果我们能把这些区分开,就能帮助完成很多任务。
就像下面这样,可以让用新垣结衣说出我们想让她说的话。

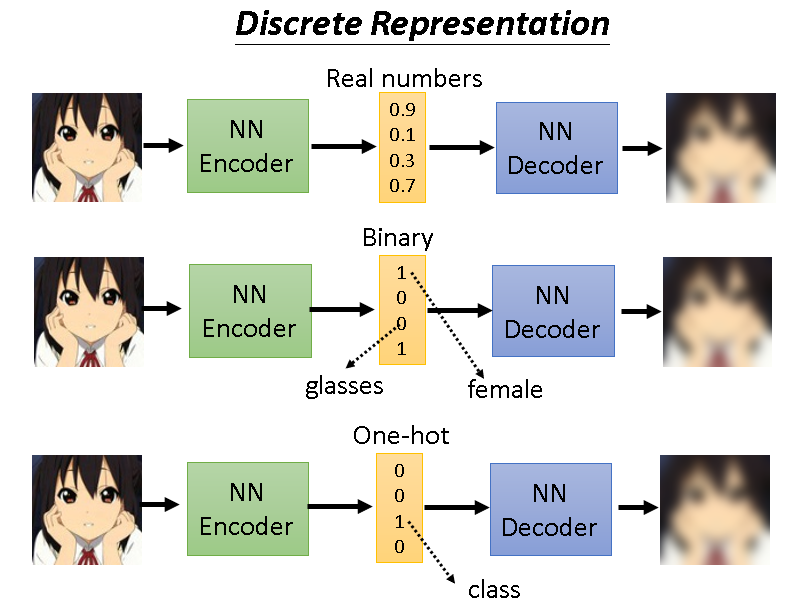
Discrete Representation
离散化表示强调的是,我们想让中间的嵌入向量不是连续的那种,因为连续的可能就会有无限种可能,在某些特定的任务中我们不想让它是任意的。
比如有些时候我们想让它是二分的,有些时候我们想让它是独热编码那种。
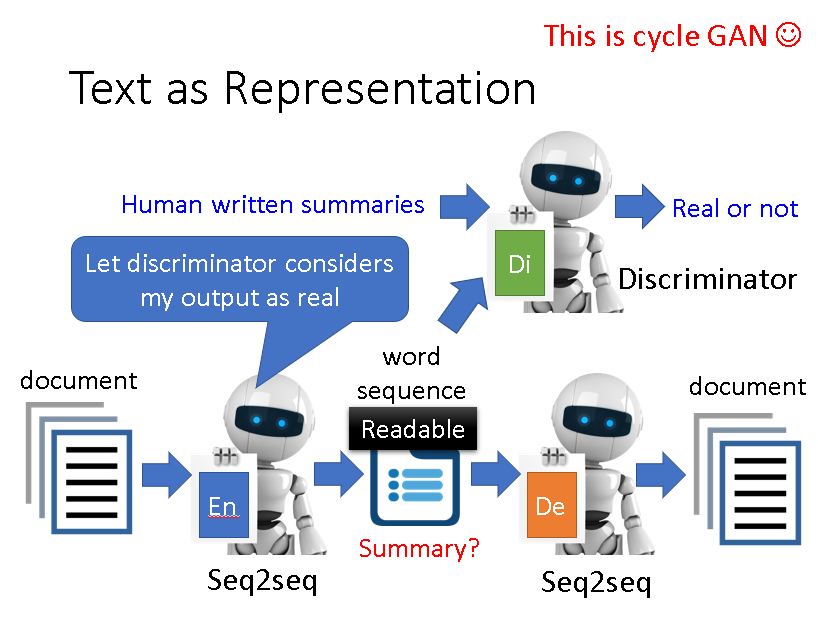
Other
Auto-encoder还可以用来做文章的摘要,但是会有一个问题,它经过Encoder生成的内容可能人类根本看不懂。
这时候就可以用GAN的思想去改进它,强行让其生成人类可以看的懂的内容,然后我们就能得到文章的摘要了。
这个模型其实和cycle GAN是一样的。
Comments NOTHING