


20.BERT
Self-supervised Learning
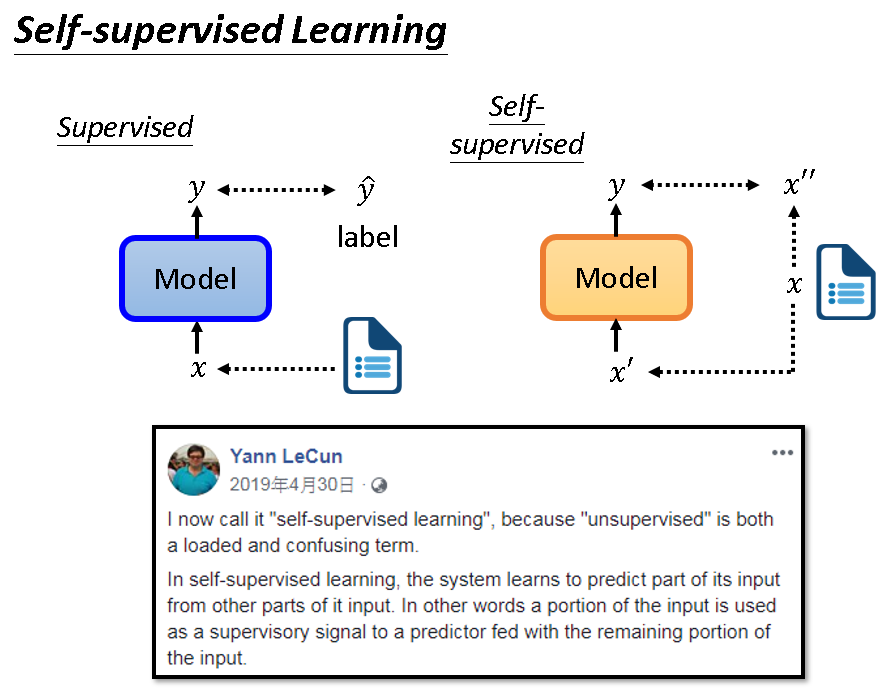
自监督学习,这个词汇是2019年被提出的,它是一种Unsupervised Learning。
它主要思想是让模型直接从无标签数据中自行学习,无需标注数据。如下图右侧,它把无标签数据分成两部分,一部分当模型输入,另一部分当标签。
BERT
首先,BERT就是Transformer的Encoder部分,一摸一样!
所以它的输入是一个序列,输出也还是一个序列。
怎么训练这个BERT呢?
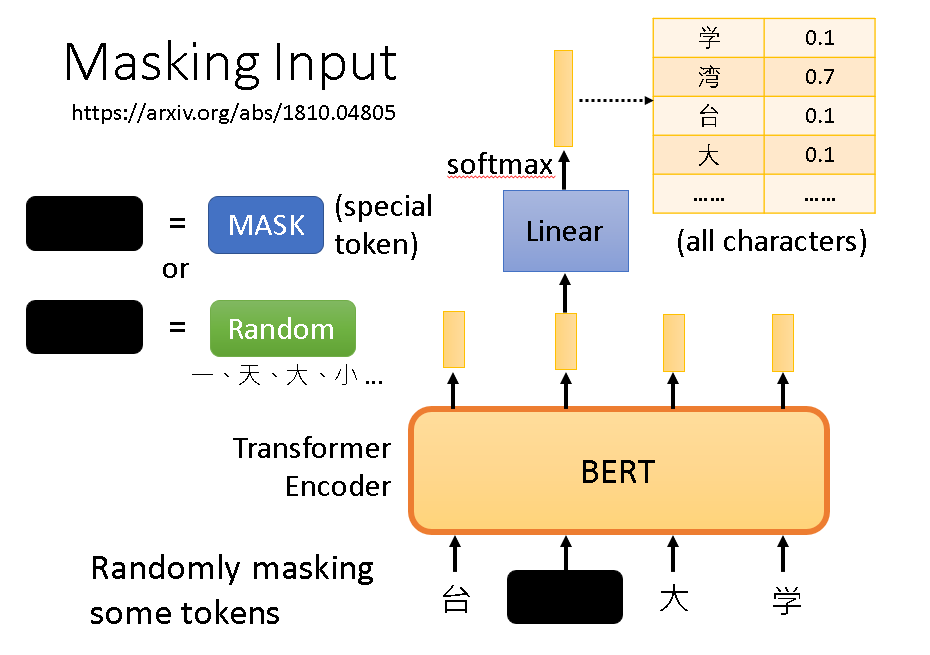
我们使用Masking Input这种方法,由于手上有很多无标签数据,我们将其输入网络进行训练。在输入时,主动遮掉输入数据的一部分,可以用特殊的token去代替也可以换成其他随机的元素。
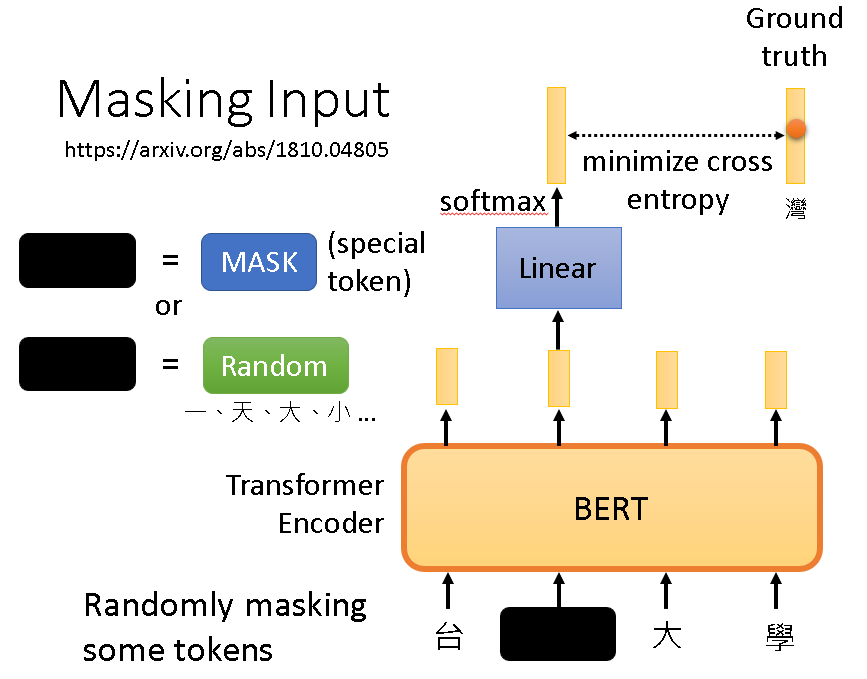
优化时我们利用的就是被遮掉的那部分的输出,因为我们知道它原本是什么,所以我们可以最小化这个交叉熵,以训练BERT。
Downstream Tasks
在学习过Transformer的Encoder之后,BERT好像变得非常简单。
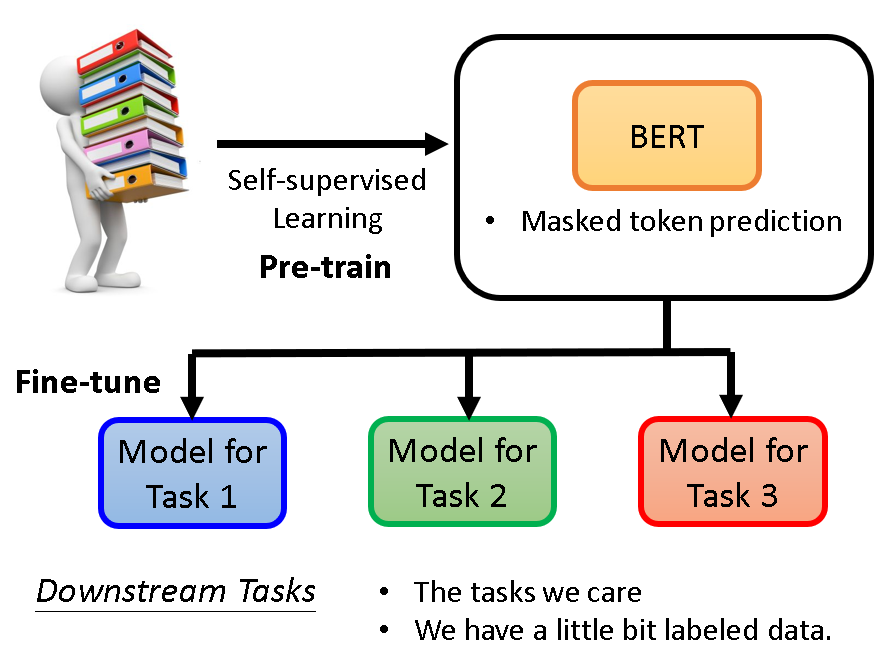
而且BERT的训练结果也很简单:BERT学会了做填空题。
那么我们不禁提问BERT能用来干啥?怎么用?
其实在拥有训练好的BERT之后,我们可以轻松应对各种下游任务,只额外需要少量的带标签数据。
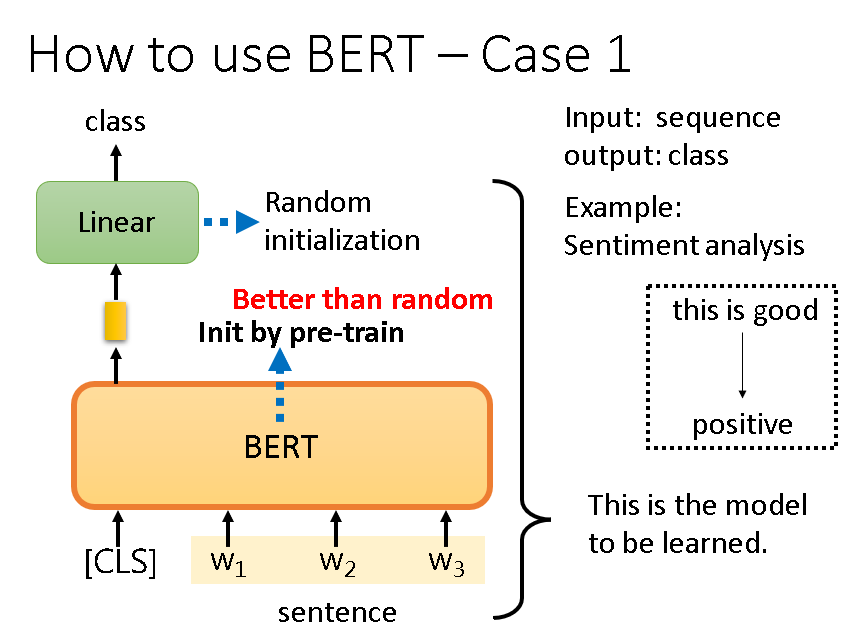
语句情感分析:
直接把用无标签训练好的BERT拿来用,相当于只用少量带标签的数据训练下游的Linear model和微调BERT。
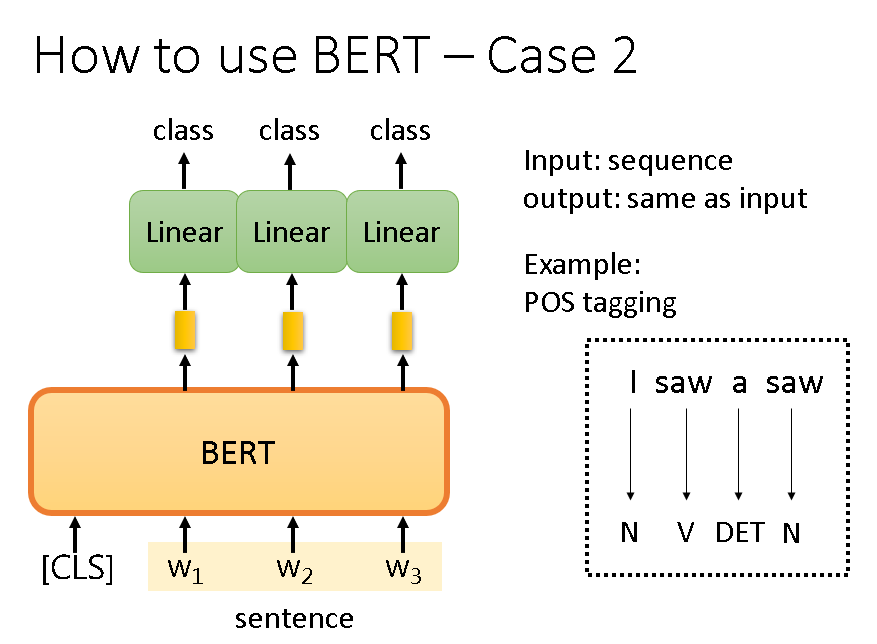
语句成分分析:
这个也是一样的。
除了上述例子,BERT能被广泛运用在各种下游任务中,一般seq2seq的问题都适用。
Comments NOTHING