


Basic Concept
1.Where does the error come from?
了解error的来源,可以帮助我们提高function的效果.
Error(误差)来源自Bias(偏差,和均值相关)和Variance(变化幅度,和方差相关)

我们得到的f*只是真实f的一个估计,所以它一定会存在一个误差Error.
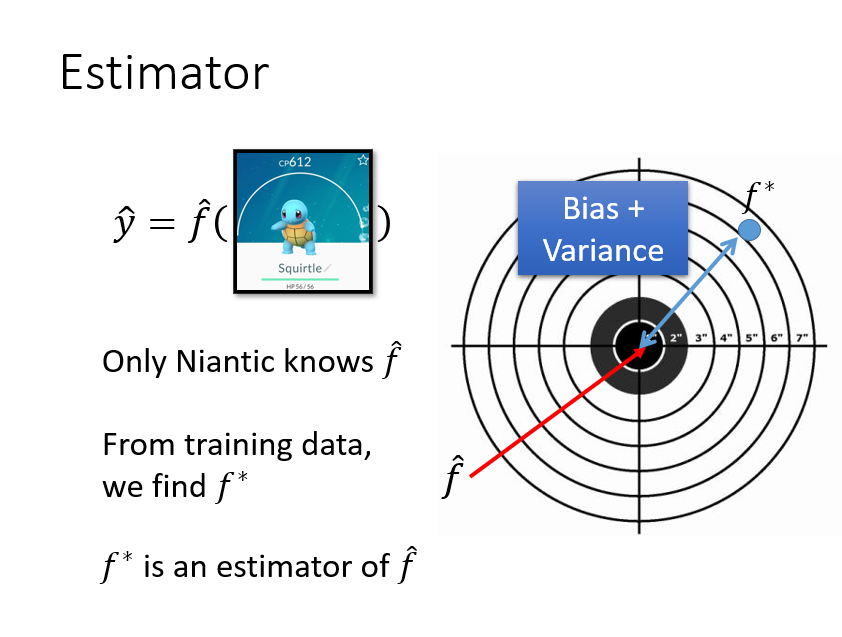
先回忆一下概率论中均值和方差的估计
均值(它是一个无偏估计)


方差的估计(它是一个有偏估计)

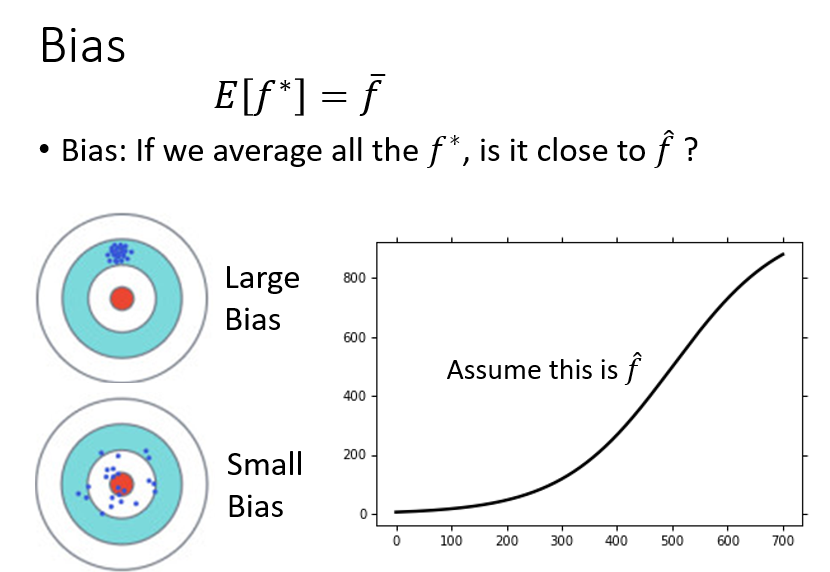
观察一下四种Bias和Variance不同情况下点的分布情况

我们的目标便有了,追求Bias和Variance都尽量小,让model的性能更好
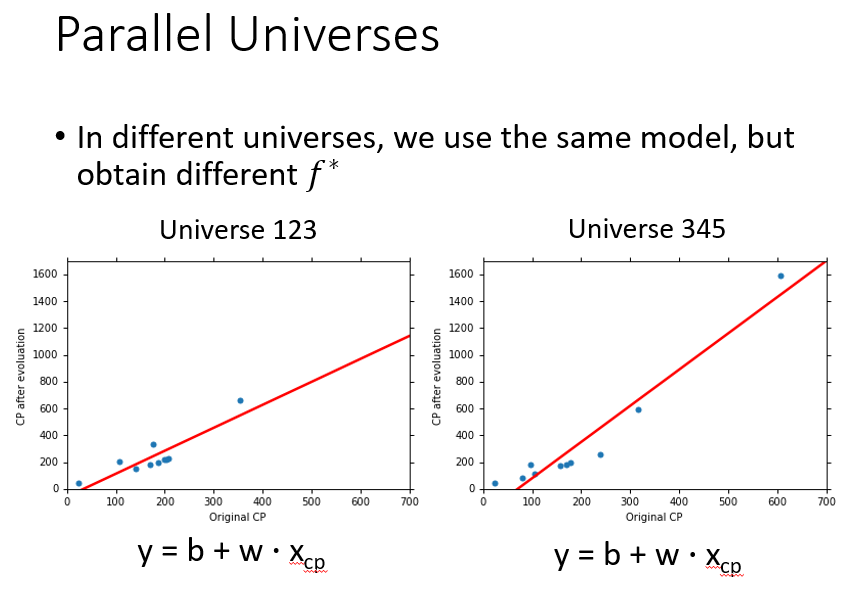
接下来我们设想我们用同一个model,不同的数据得出了不同的f*

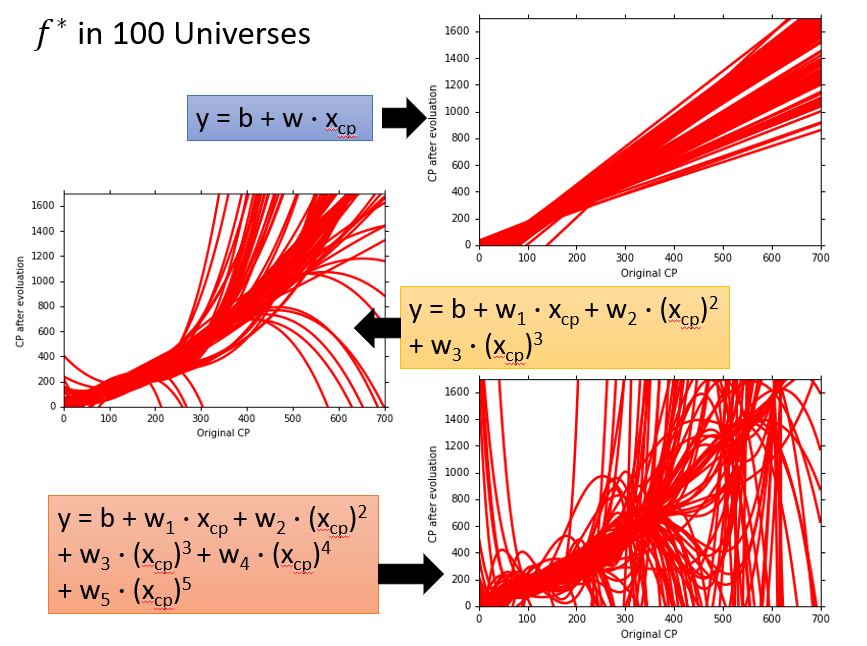
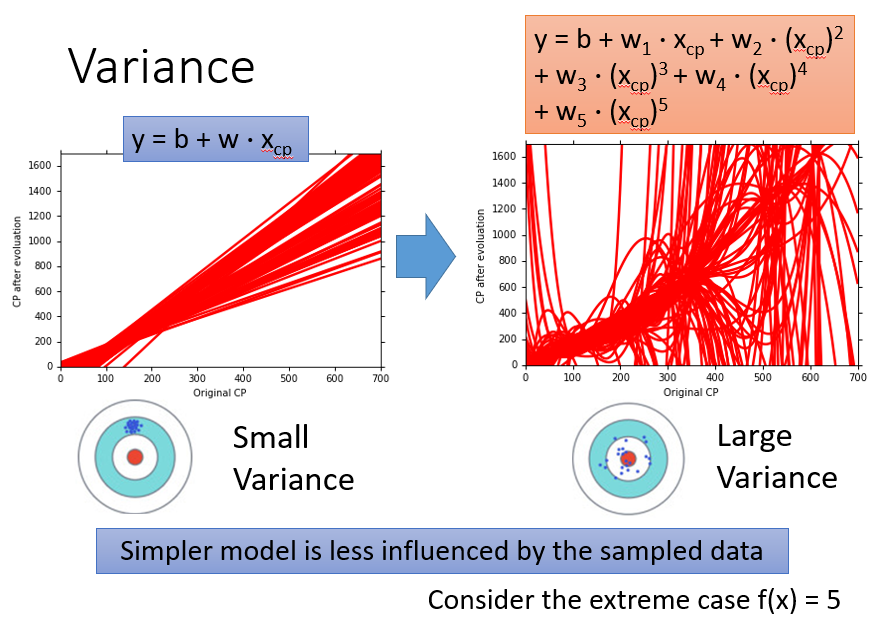
*我们不难看出,在一幅图中,使用同一个model,训练出来的f之间差别越大,Variance越大,而且我们可以得知越复杂的model(例如5次式),它的Variance就越大,也就是稳定性越差**
对于Bias
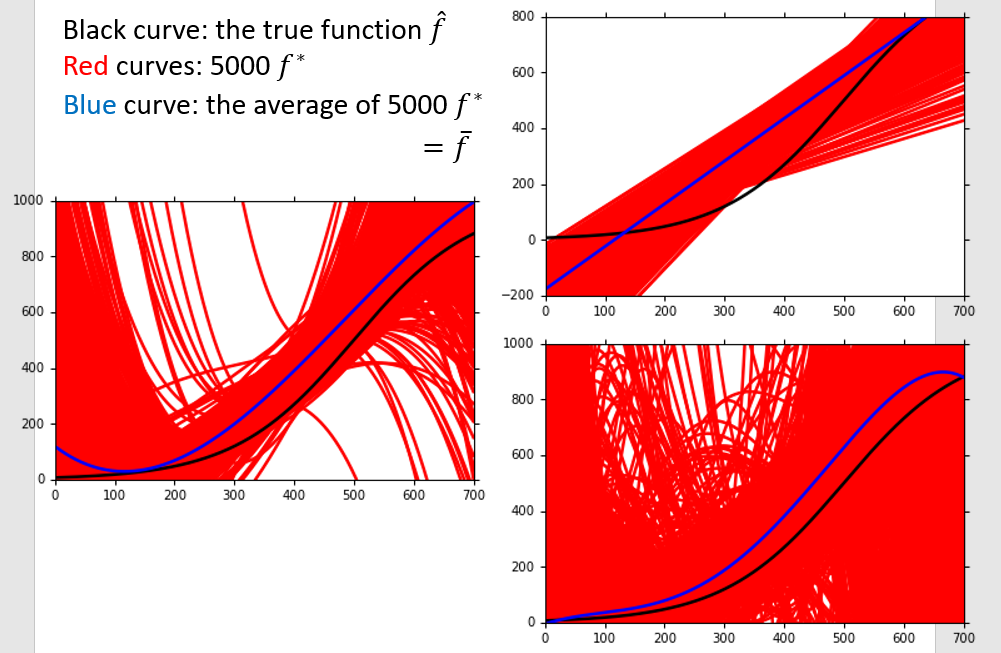
我们可以看出越复杂的式子它的Bias越小,也就是偏差越小
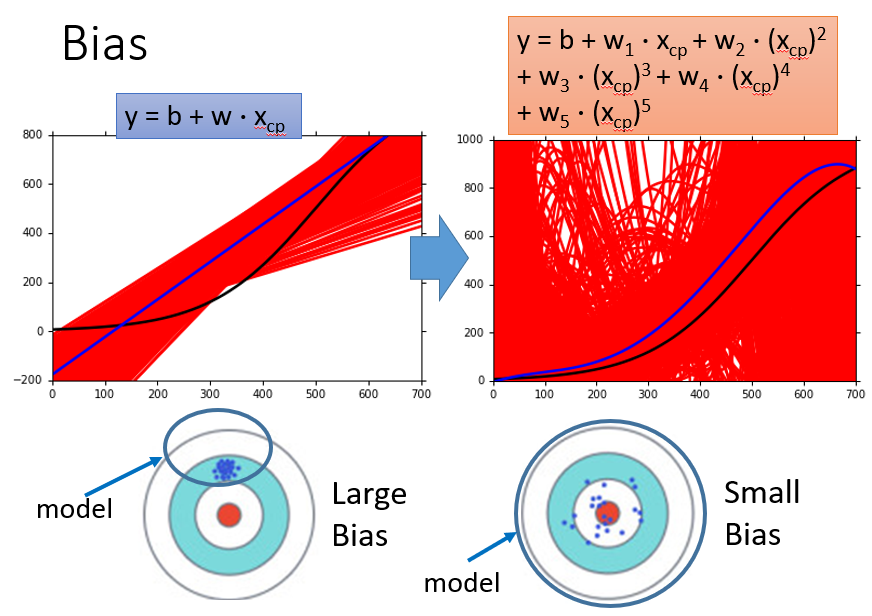
综上我们可以得出:
- model越复杂,Variance越大,Bias越小
- model越简单,Variance越小,Bias越大
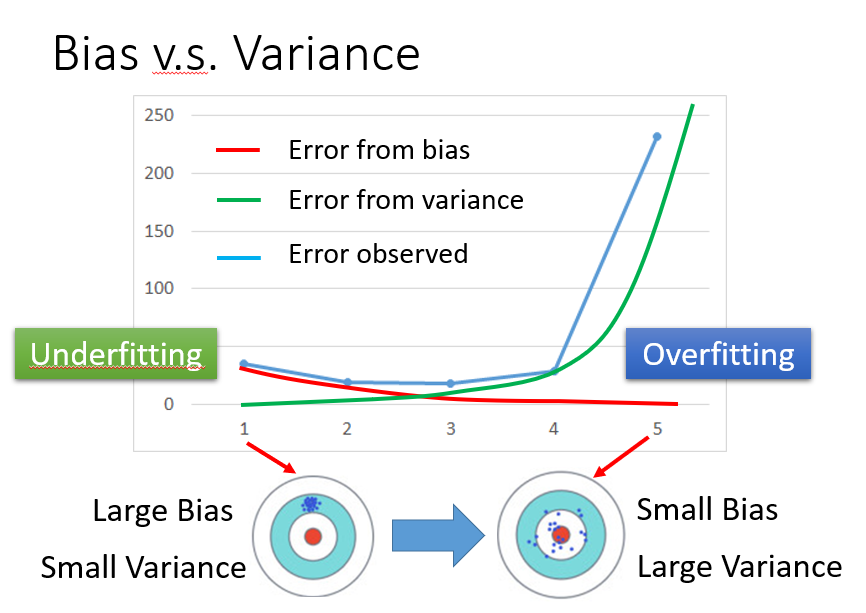
所以根据我们要求的方差和偏差都要小,我们要折中进行选择我们的model
如何处理Bias和Variance过大的问题
首先我们要明确两个概念:
-
过拟合,Overfitting,你的Error是由Variance过大导致的。
-
欠拟合,Underfitting,你的Error是由Bias过大导致的。
什么时候会发生过拟合和欠拟合:
当你的模型能够适应训练数据,但是在测试数据上的偏差过大时,这时候就出现了过拟合,具有大的Variance。
当你的模型不能适应训练数据时,这时候就出现了欠拟合,具有大的Bias。
怎么解决:
发生过拟合,即拥有较大的Variance时:
- More Data:这样虽然有效但并不是十分实用,因为数据的获取往往比较困难。
- Regularization:即正则化,增加一些额外的参数,使曲线变得更加平滑。
发生欠拟合,即具有较大的Bias时:
- Redesign your model(add more features as input或者a more complex model)
以上这么多都是为了选择更好的model
一般都是择中进行选择.

一般我们的model可能在我们手中的Testing Data 上有不错的效果,但是在面向所有可能的Testing Data时,Error Rate就会有所上升
虽然想说这是很正常的,但是确实有方法可以适当解决这个问题
交叉验证
如下可以将Training Data分成两份,一份用来训练model,一份用来选择我们训练的model,选择Error最低的之后,再拿整体的Training Data来训练一次这个model。
这个时候会有不错的效果,但是在Testing Data时,Error会大于我们训练出来的,此时不推荐从头重选model,因为我们大可不必在意我们选出来的model在我们拥有的Testing Data上的Error Rate,因为我们最终面向的并不只是我们手中的数据。或许这里面也具有一定的运气问题,相信自己挑出来的就是最好的model!
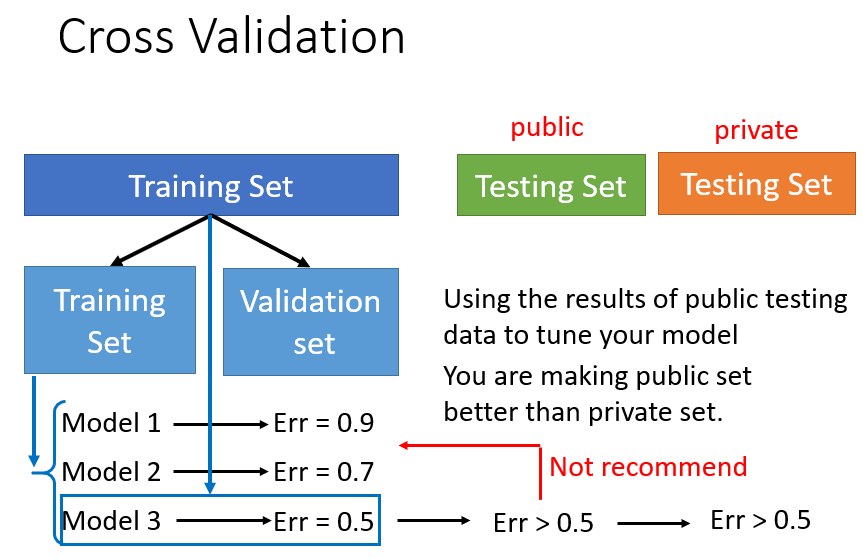
n 重交叉验证
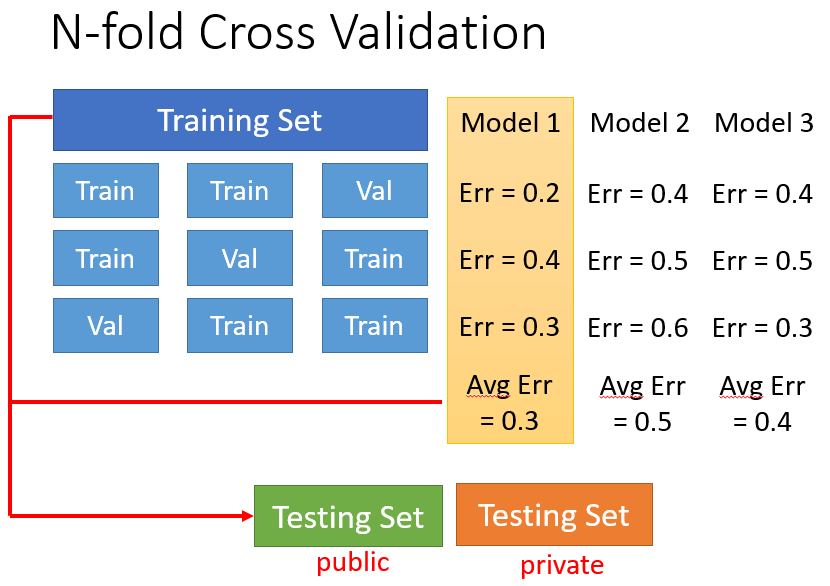
就是分成三份,每次拿其中两份作为训练数据,最后一份作为选择数据,一共有三种情况。
三种情况下不同model的Error再取均值,选出Error最小的。
最后再拿整体的训练数据训练一下这个model。
Comments NOTHING