


18.Self-attention
简介
Self-attention,即自注意机制。简单概括一下,它的输入是一排向量,输出也是一排向量。经过self-attention处理后的向量集更能联系全局,因为它考虑一个向量与其余所有向量的依赖关系。就像在NLP中,Self Attention在计算过程中会直接将句子中任意两个单词的联系通过一个计算步骤直接联系起来。
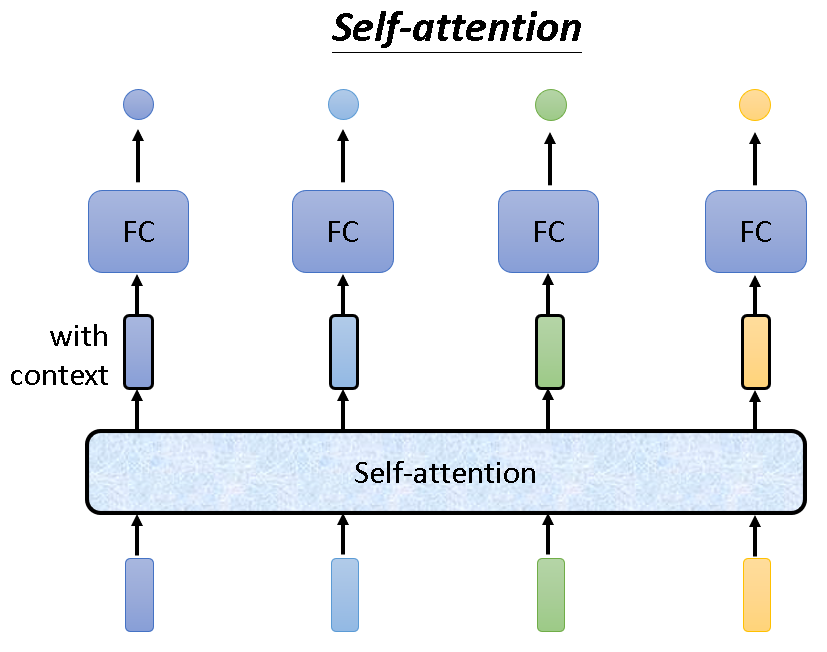
当然这个self-attention是可以叠加的,多次使用,结构如下:
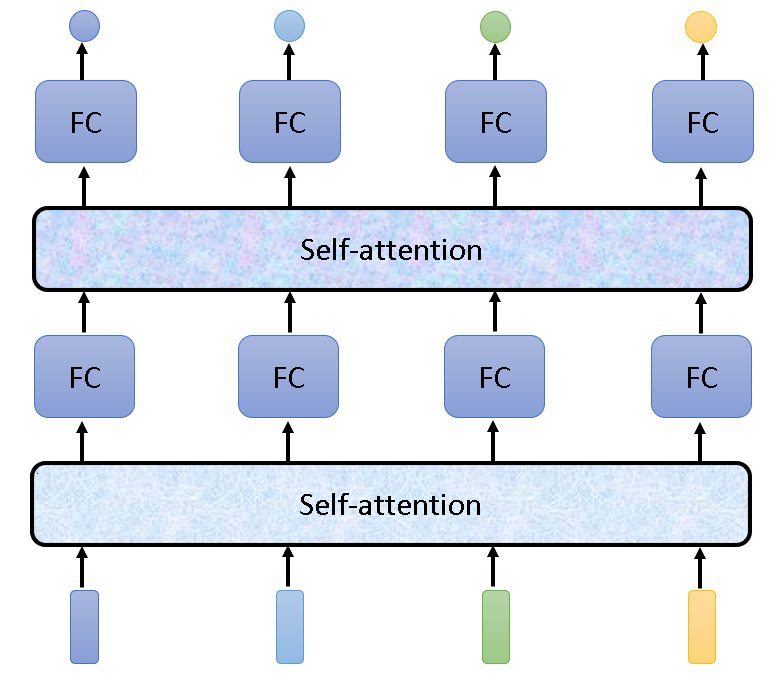
工作原理
下图中a1经过self-attention处理后,变成b1。这个过程中,a1必然会寻找其与输入序列中其他向量的关系,这个怎么做的呢?
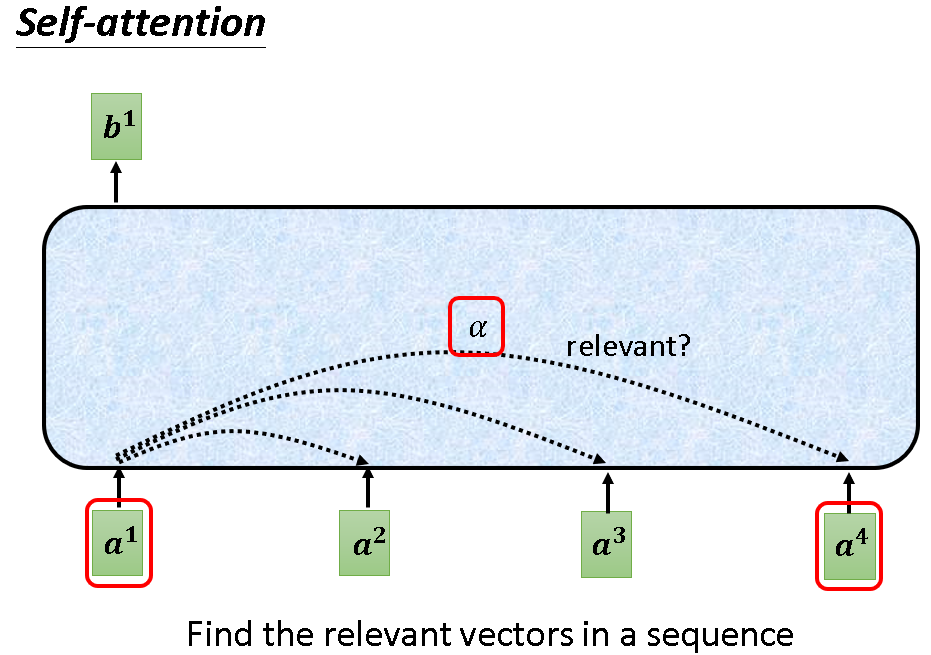
首先,我们为每个向量引入这三样东西:query,key,value。它们都是通过向量乘以一个参数产生。
-
query:某向量在查询自身与序列中其他向量的联系时使用,简称q。
-
key:某向量被查询联系时使用,简称k。
-
value:代表某向量所包含的信息,简称v。
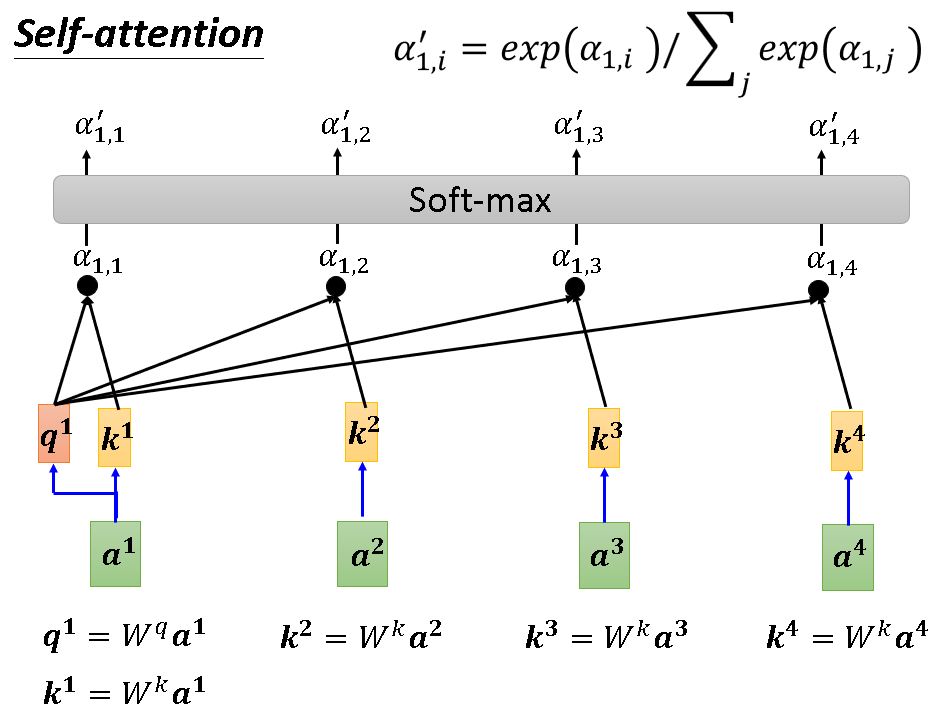
以a1产生b1为例,首先a1会用它的query去查询其与所有向量的联系,这个过程一般是用自己的query与其他向量的key做内积。然后得到α1,1....α1,4。这个α就代表了自身与其他向量相关的分数,分数越高越相关。为了能更好的使用α,self-attention会用soft-max把α归一化为α‘(各个α’和为1)。
有了归一后的相关分数α’,就能得到b1了。一个简单的加权求和,分别用α‘与对应的v相乘再加一起即可。这个过程,说白了就是“我和谁的联系大我就多取一点它的信息加到自己头上”。
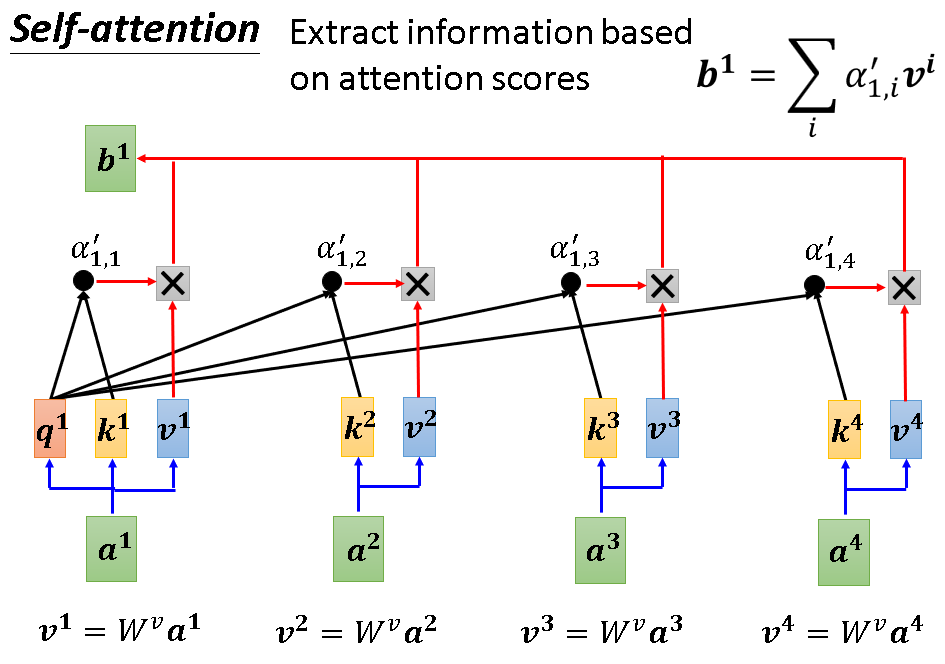
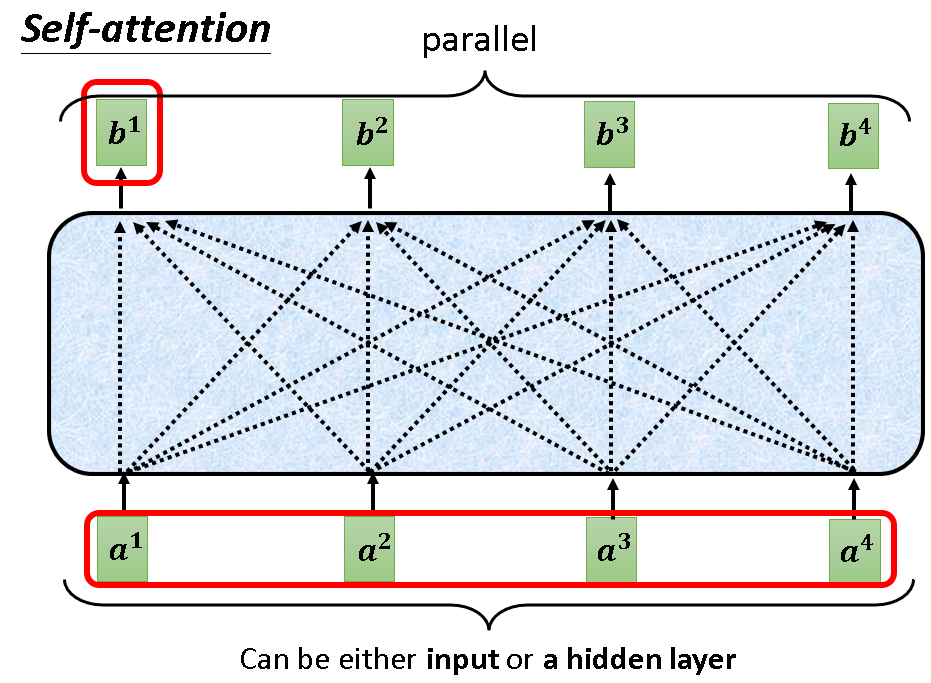
之后的b2,b3,b4也是如此得到的,值得注意的是这个过程是平行的,它不分先后。
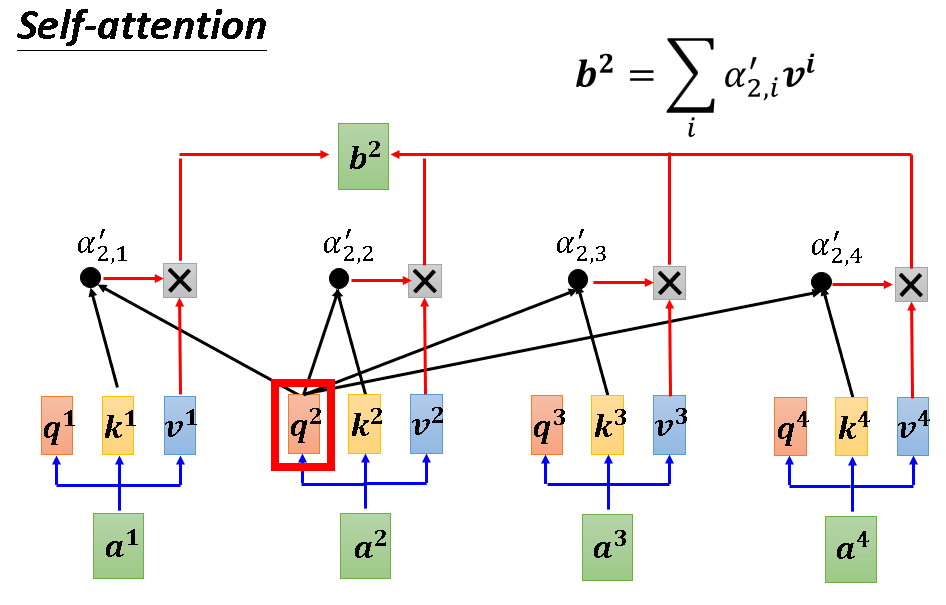
接下来我们再看一遍b2的生成过程,加深一下理解。
因为各个向量的计算不分先后,而且一模一样。所以深究一下,此算法内部其实是在做矩阵运算,接下来的几张图将详细阐述这一过程:
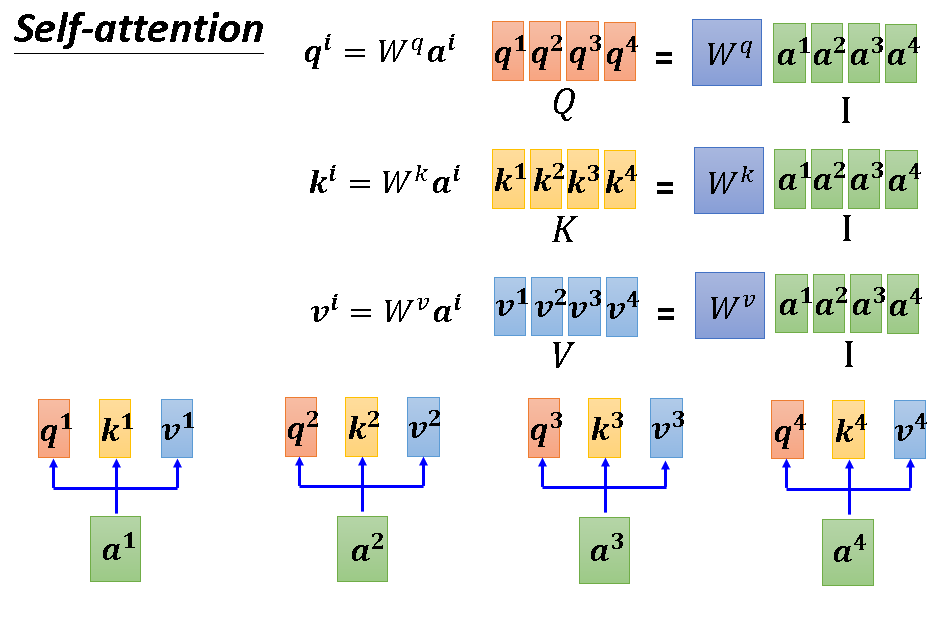
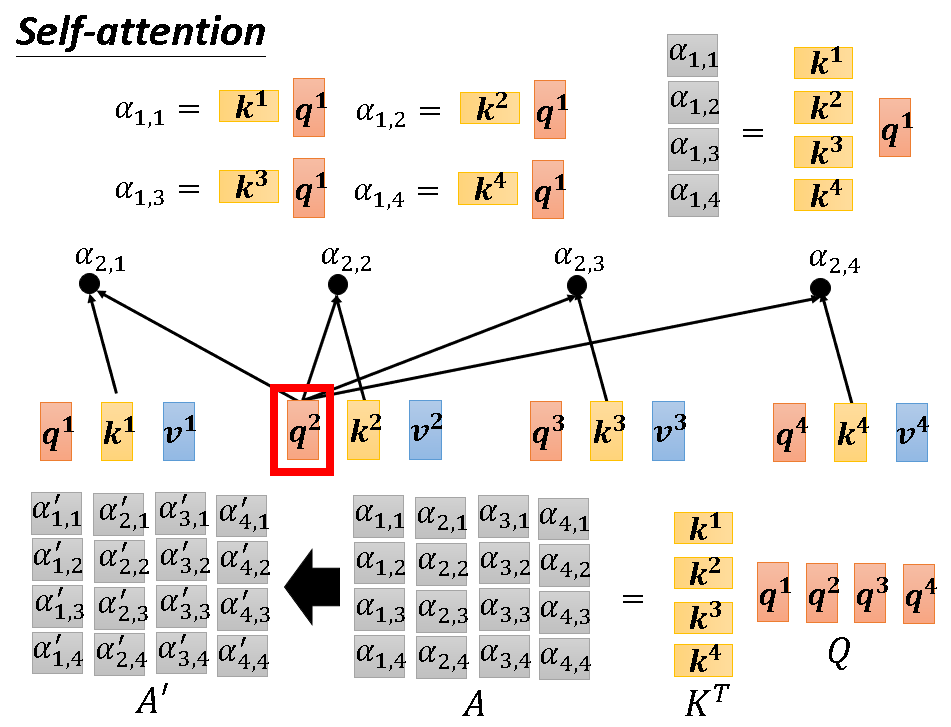
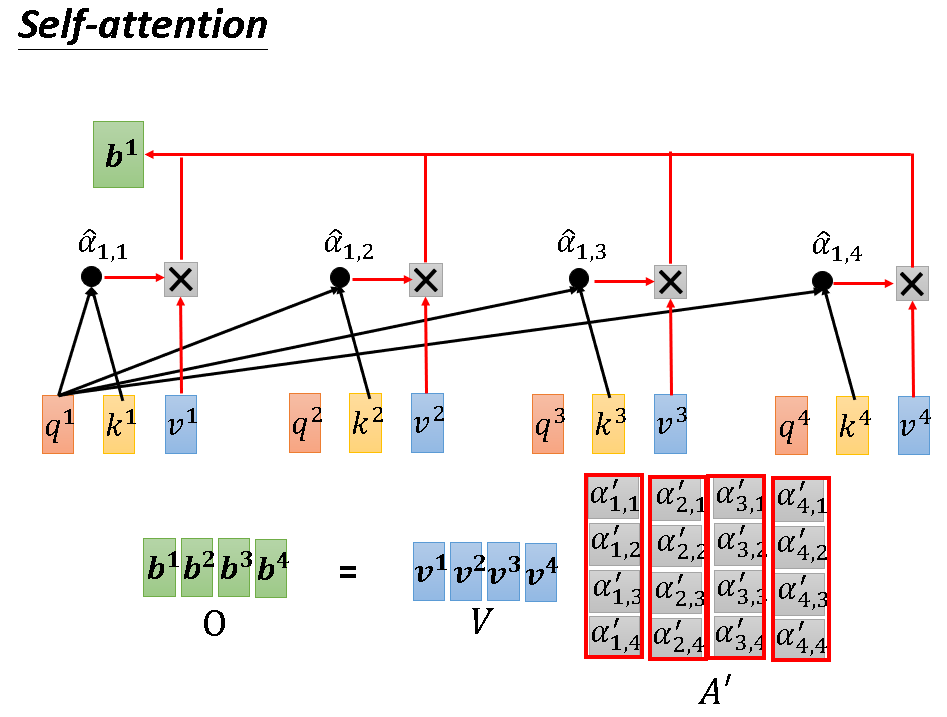
上述流程更精简的版本如下图:
到这里我们可以清晰的发现,整个self-attention要学习的参数只有产生q,k,v的系数。

变形
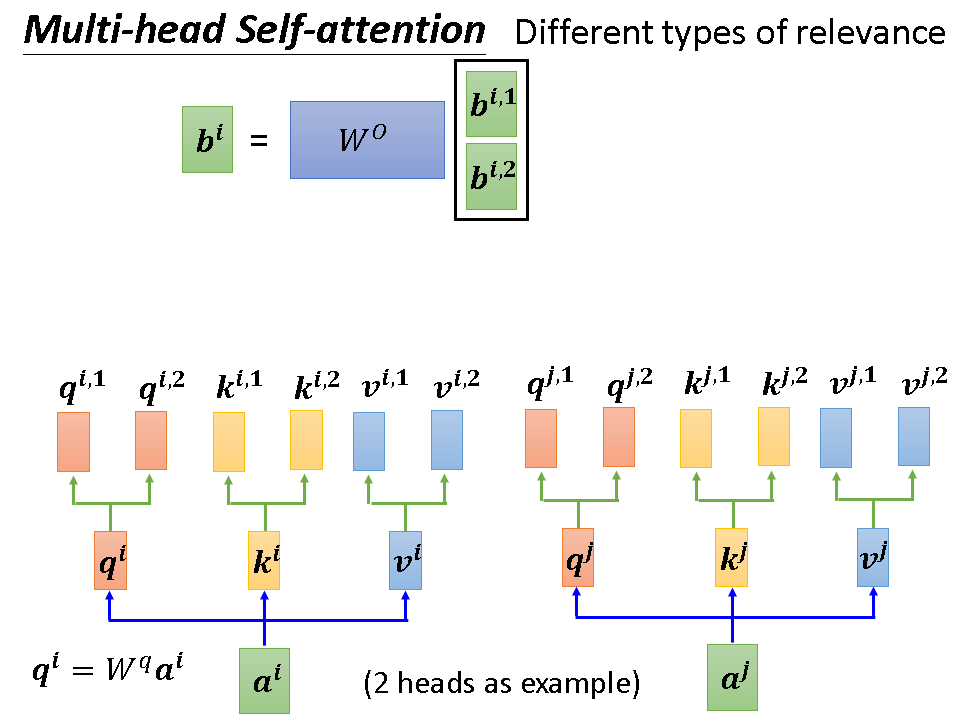
如果我们要考虑不只一种联系的话,我们可以使用Multi-head Self-attention,即多头自注意机制。一句话概括它就是有两套q,k,v,分别对它们进行计算,最后对产生的多个b加权求和即可,其中的权重也是要学习的参数。下面几张图详细阐述次流程:
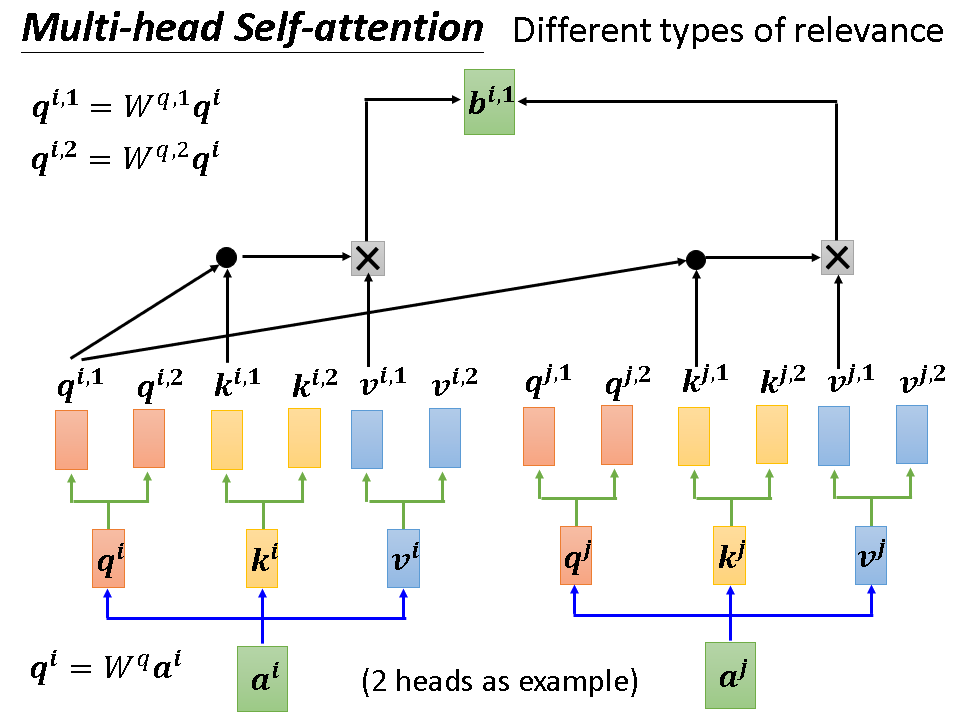
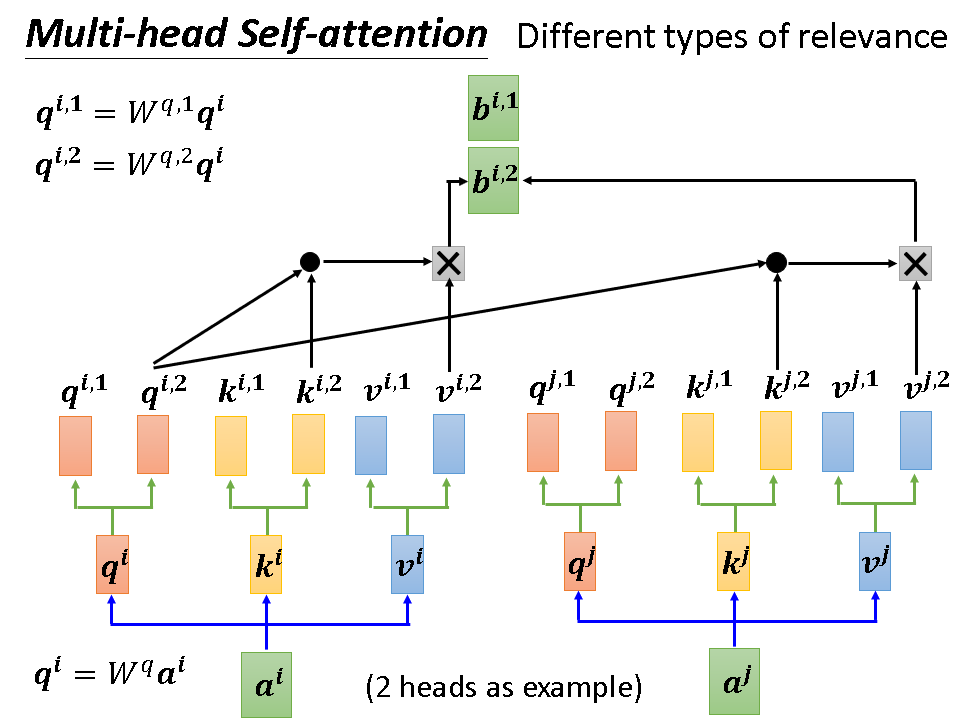
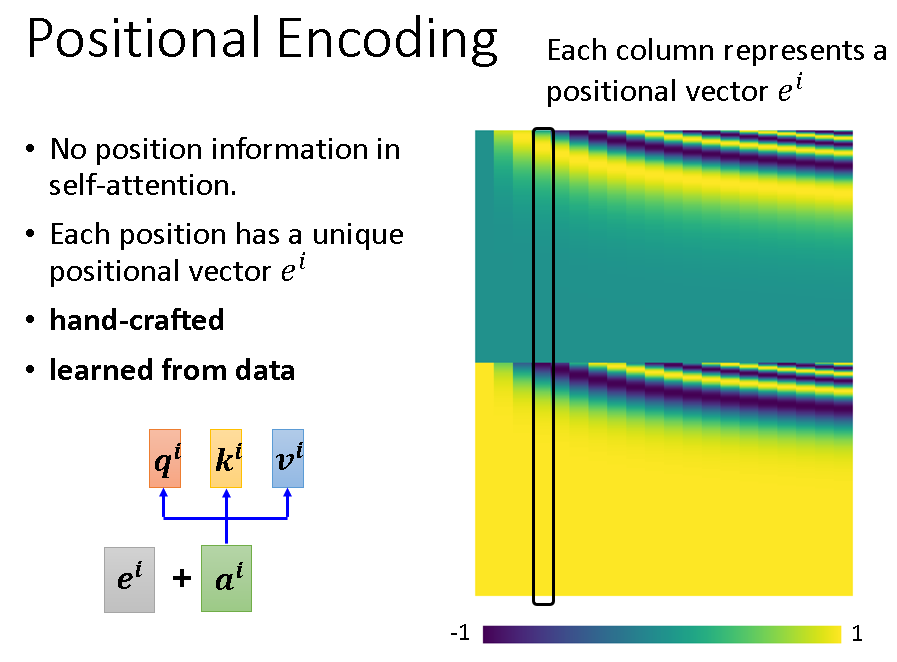
另外还需注意的是,原本的self-attention已经抛弃了位置这一信息。如果位置的关系真的很重要的话,可以人为加上标识位置信息的向量e,就加在输入部分。
应用
Self-attention的应用非常广泛,著名的Transformer和BERT这两个模型的核心部分就使用了self-attention,关于这两个模型我会在以后的博客中进行讲解。

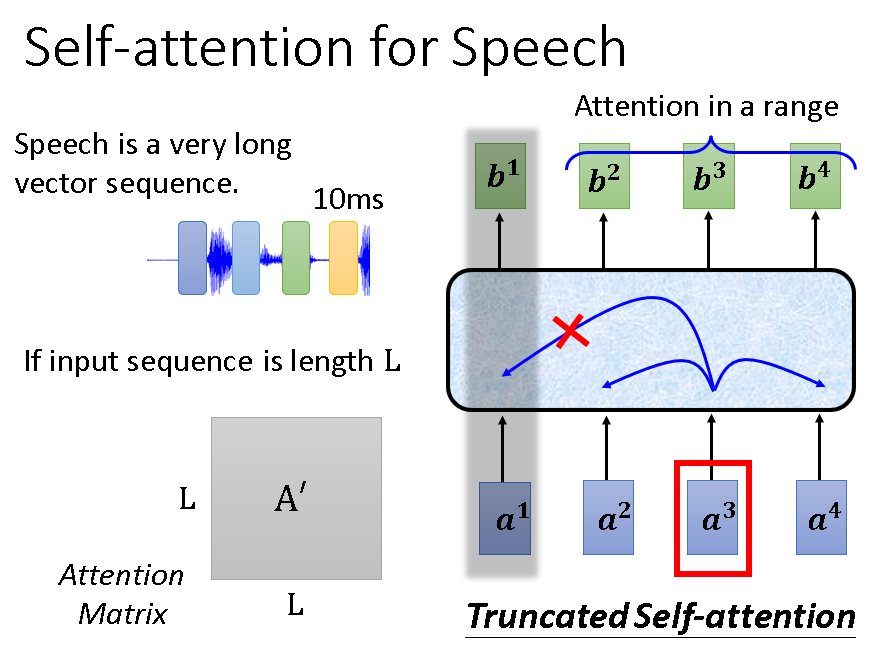
在语音识别中的应用如下图:
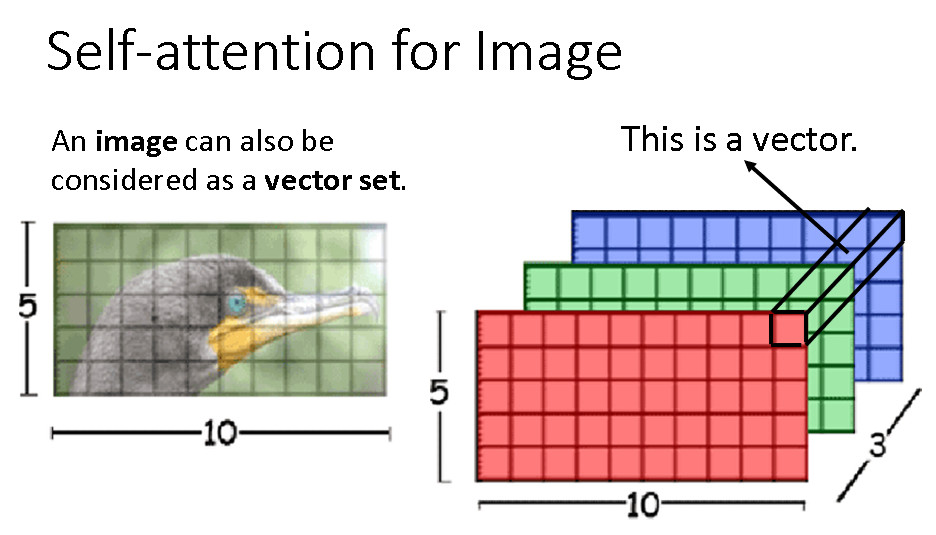
在图像识别中的应用如下图:
相关的其他应用:
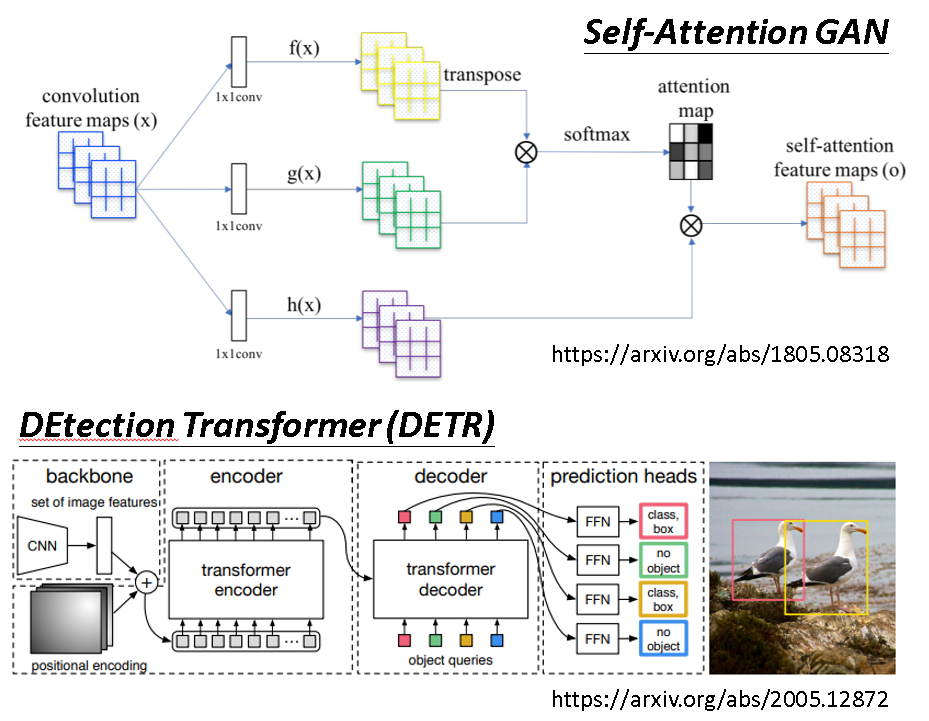
思考
到这里我们已经对Self-attention有了一个大致的了解。
那么我们回想一下卷积神经网络CNN,它做的是卷积操作,提取局部特征,注重的是某个点其周围的点之间的联系。而Self-attention考虑了某个点与所有点之间的联系。
所以,CNN是不是可以看成是一种特殊的Self-attention,只是有联系的点刚好在周围。
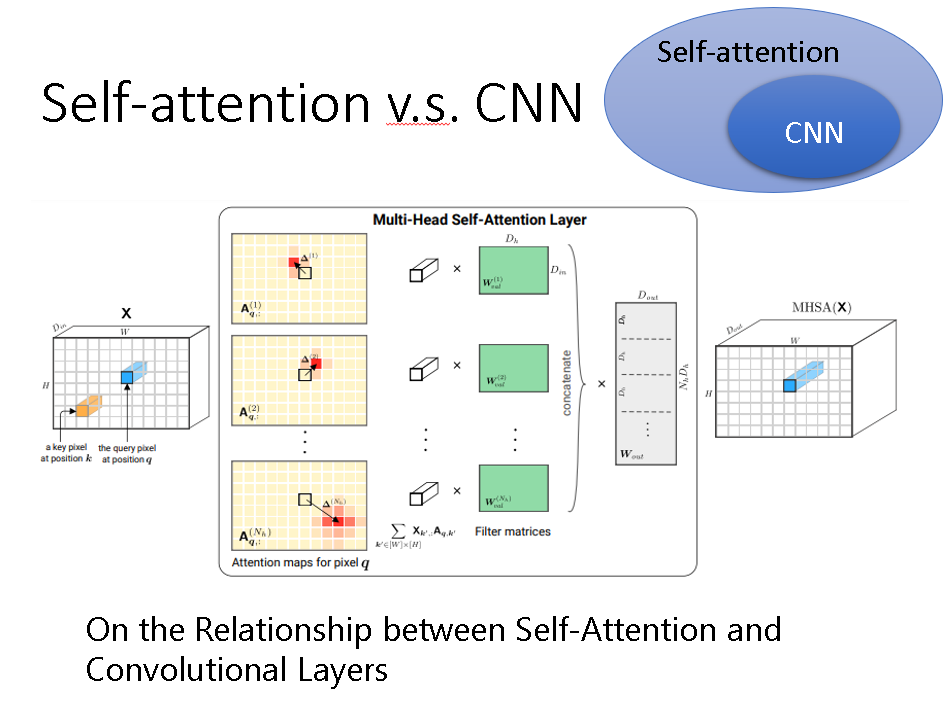
为了验证上一猜想,有人用Self-attention去处理CNN的问题。
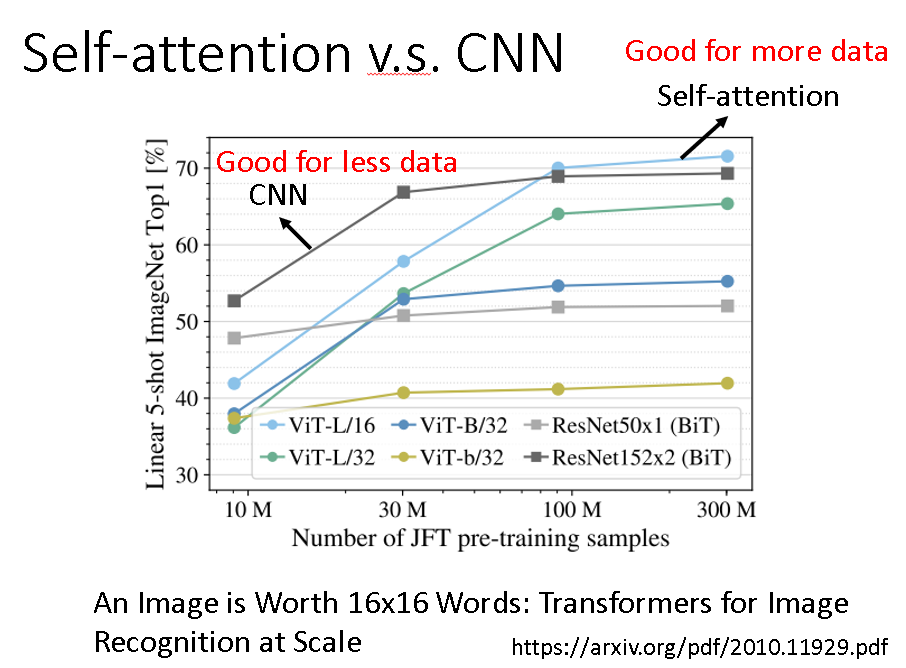
最后发现确实是这样的,Self-attention可以被当做CNN来用,而且在数据量充足的情况下效果还比CNN的效果要好。
但是在数据量较少时还是CNN效果好一些,这也是肯定的,这大概是因为self-attention中参数过多,数据量太少train不好。
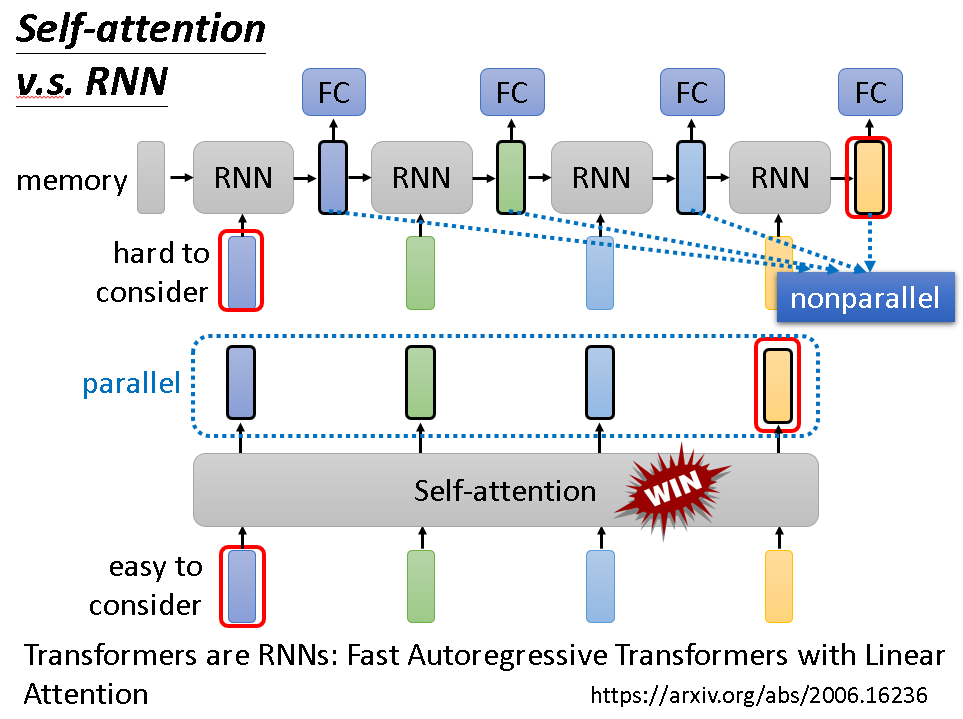
与RNN相比,self-attention是一个加强版的RNN,已经完全取代RNN了。这是因为RNN有自身的缺陷,它前一部分的结果需要存储在记忆单元供后续使用,这就导致它不是一个平行的过程,后一部分必须等前面结果出来才能训练,大大拖慢速度。而且前面向量对后面的影响会依次递减,相距过远的向量之间的联系根本建立不了。
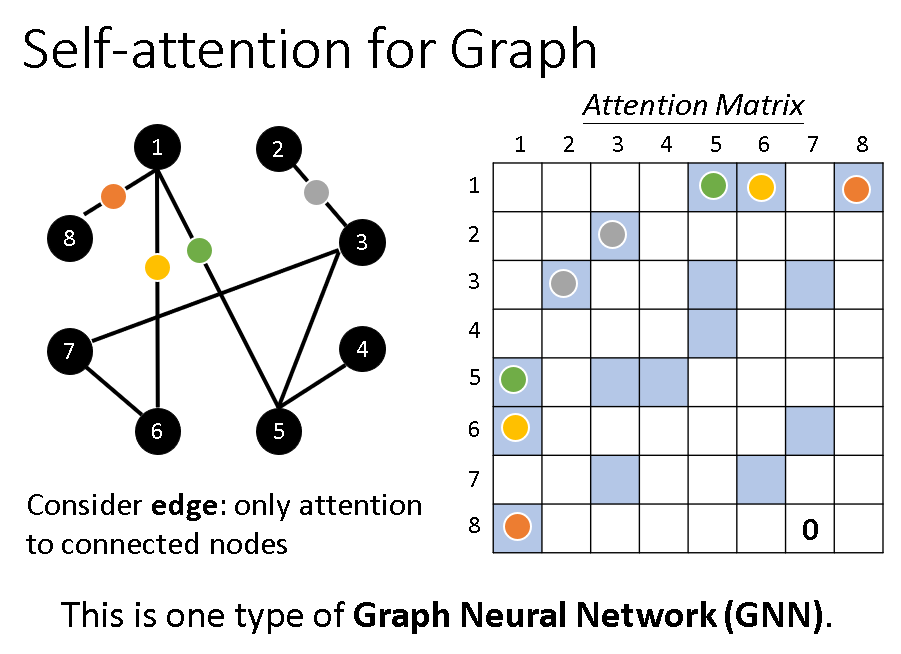
另外图也是可以使用self-attention的,只要把图转化为矩阵即可,只不过这时候一个节点只需要注意和它相连的节点。
Comments NOTHING