


RNN
Brief Introduction of RNN
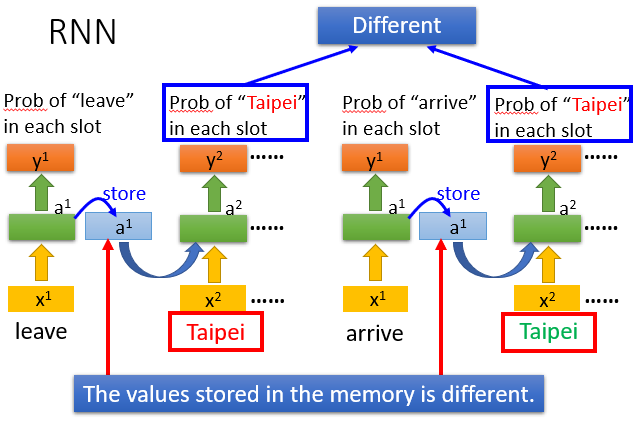
RNN,即Recurrent Neural Network,是具有记忆的神经网络.
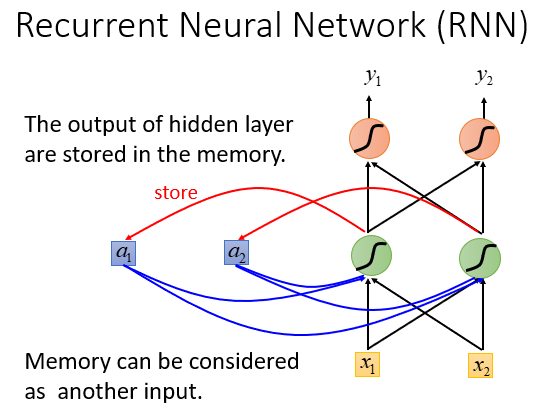
可以理解为是先输入的数据对后来的有影响,这就是RNN具有记忆的体现。
简单的演示如下:
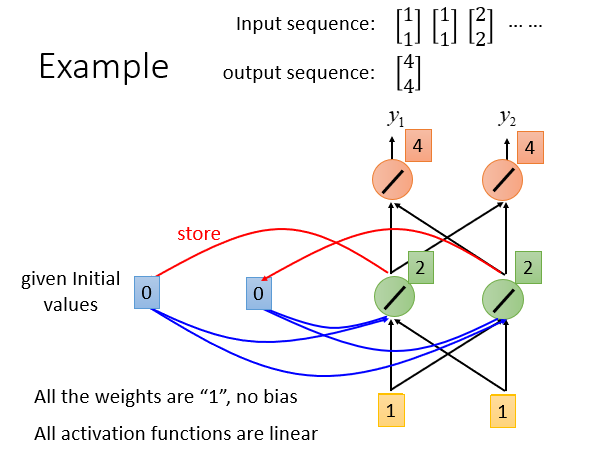

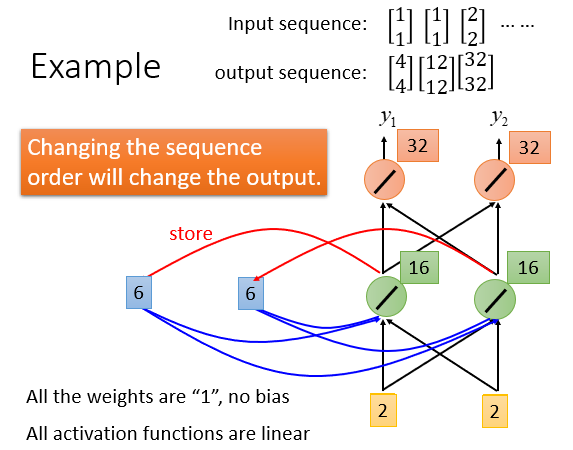
同一个神经网络被多次利用(大量的输入数据),但是由于其具有记忆力,所以即使先后使用同一组输入数据也可能导致结果不相同。
RNN也可以有很多层。
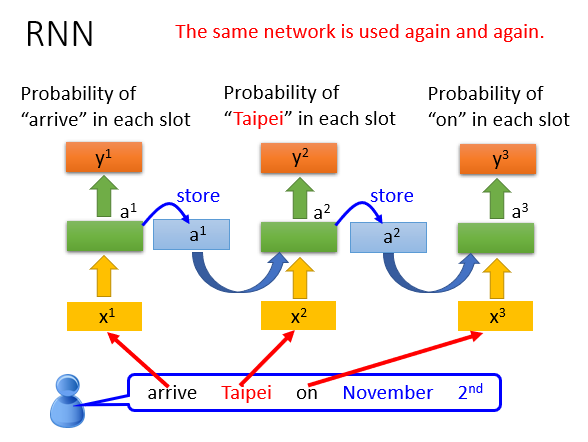
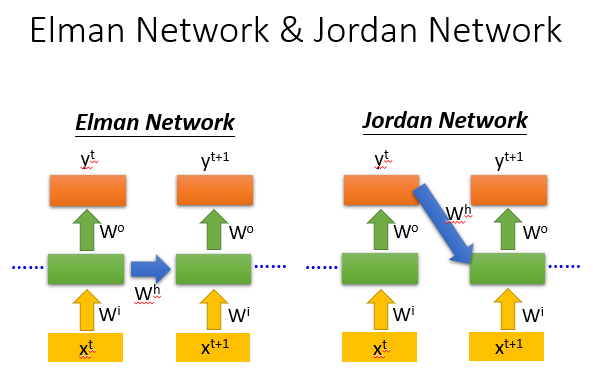
RNN有很多种,一般RNN中使用的多为Elman network,另外还有Jordan network等.
Elman network其实就是简单循环网络(simple recurrent networks,简称SRN),是由Jeff Elman在1990年提出来的。Elman在Jordan network(1986)的基础上进行了创新,并且简化了它的结构,最终提出了Elman network。
-
Elman network的一个recurrent层的输出经过时延后作为下一时刻这一层的输入的一部分,然后recurrent层的输出同时送到网络后续的层,比如最终的输入层。
-
Jordan network则直接把整个网络最终的输出经过时延后反馈回网络的输入层。
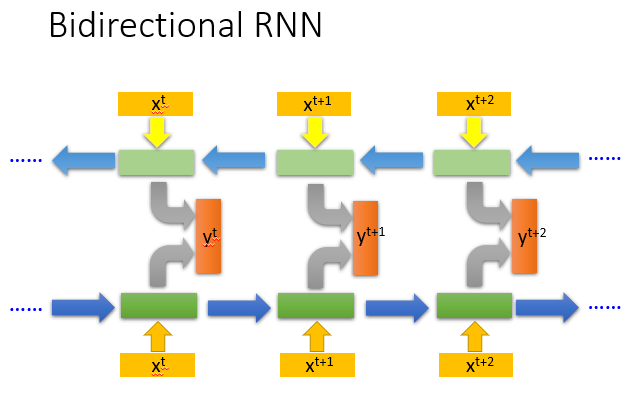
此外还有Bidirectional RNN,即双向循环网络,它不仅仅拥有基本循环网络的
forward components,增加了反向的backward components。
LSTM
LSTM,即Long Short-term Memory,是Elman network的一种,常用的RNN。
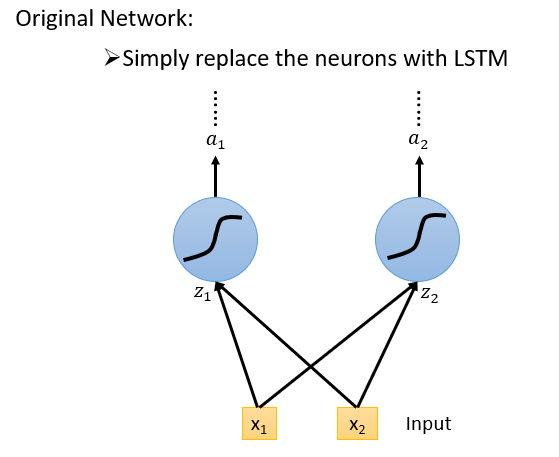
每一个下述结构就是一个神经元,它拥有四个输入部分,如图所示。
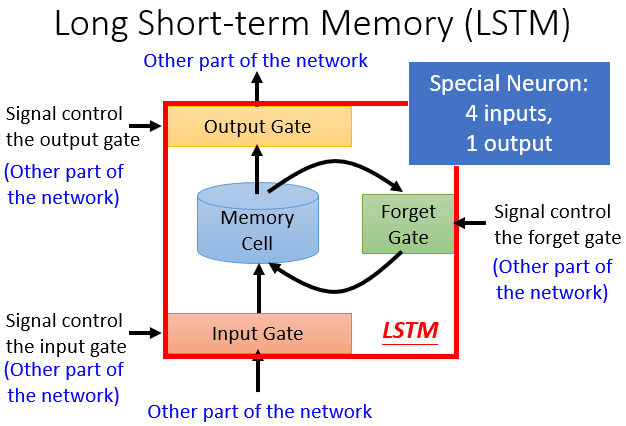
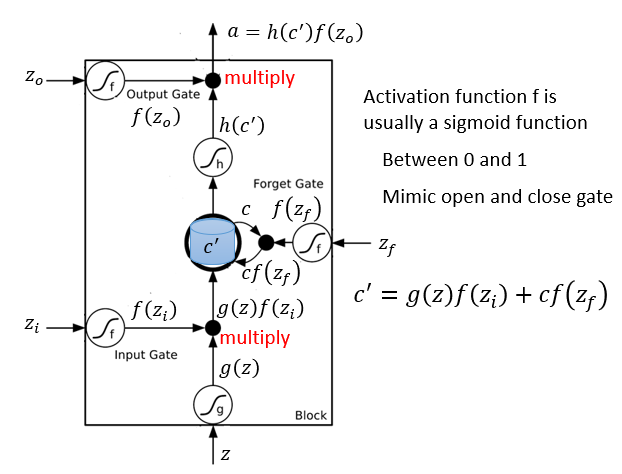
它的运行方式如下图所示。
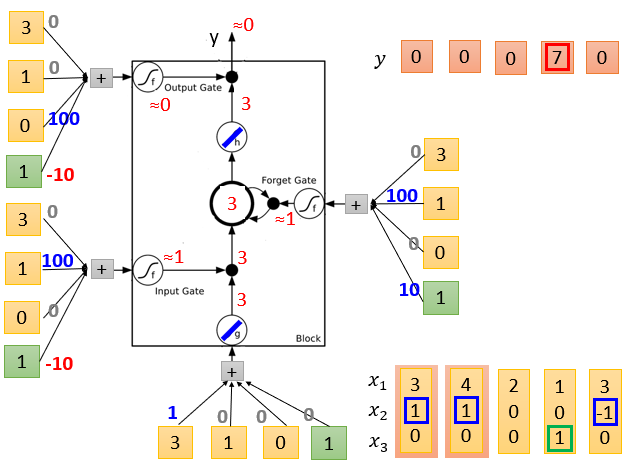
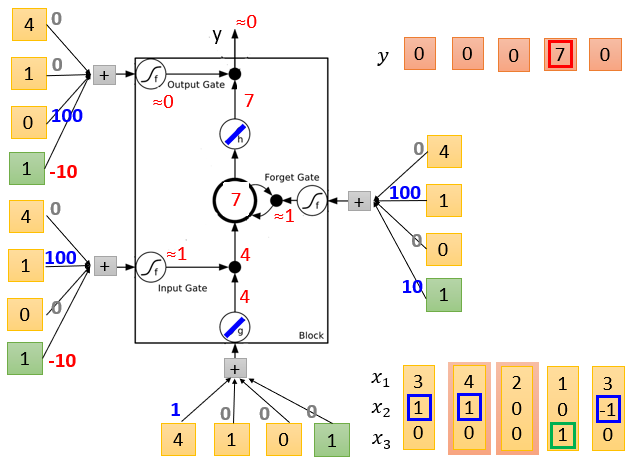
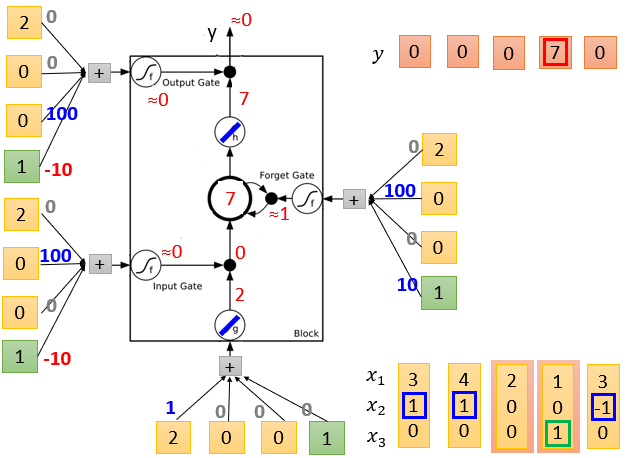
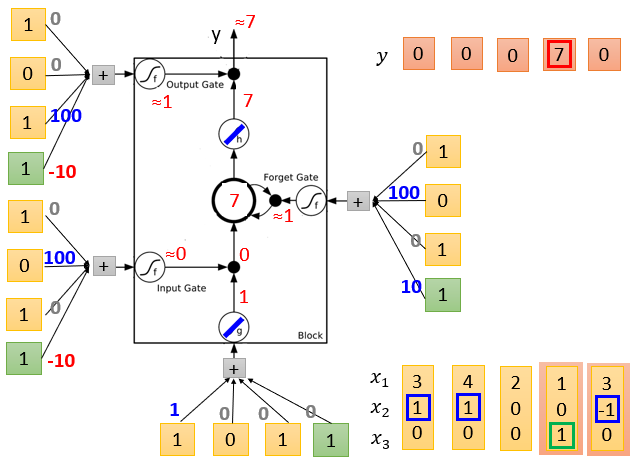
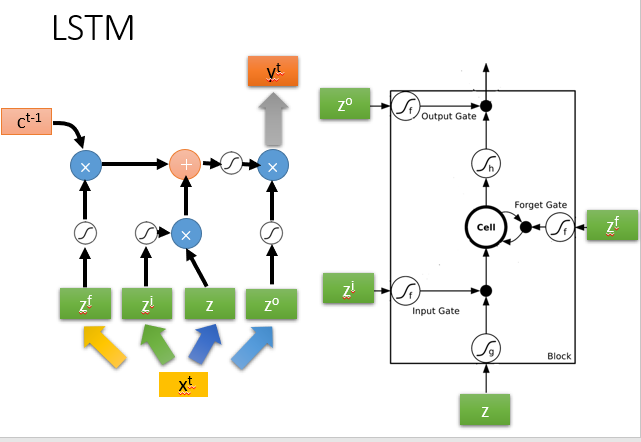
LSTM的简单实例如下,它的输出结果由多个输入共同影响。
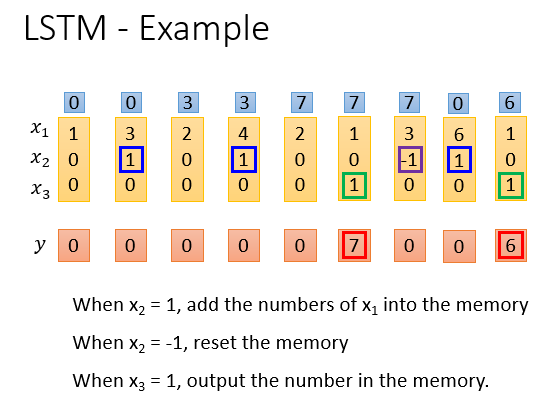
实例中输入数据为三维,分别用x1,x2,x3表示。
当x2=1时,就让神经元记住x1的值,放在记忆单元中。
当x2=-1时,就重置这个记住的值。
但只有当x3=1时,才会输出这个记住的值。
各输入数据的weight是假设的,实际应用中通过训练获得。
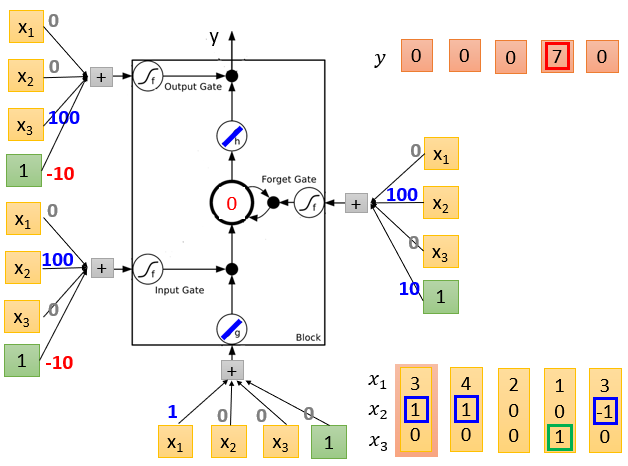

相较于之前的神经网络来说,像LSTM这种RNN就要训练四倍的参数。
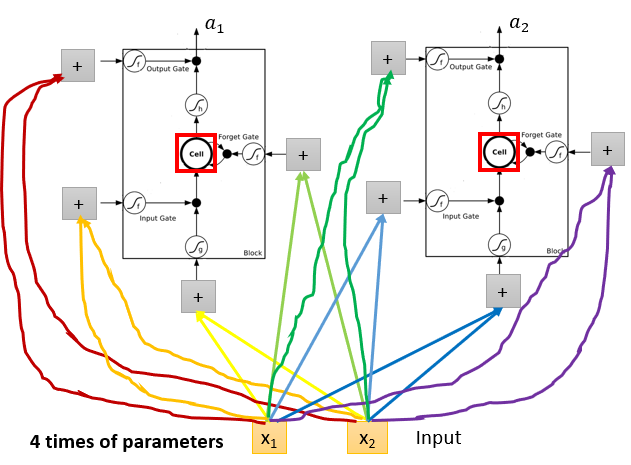
基本的LSTM运行结构如下第一张图,但是实际应用中,它可能会更复杂,前一组数据不同阶段的输出可能会参与到下一组数据的计算中,如下第二张图。
How to learn?
我们一般使用BPTT这种方法去训练一个RNN的参数。
BPTT(back-propagation through time)算法是常用的训练RNN的方法,其实本质还是BP算法,只不过RNN处理时间序列数据,所以要基于时间反向传播,故叫随时间反向传播。BPTT的中心思想和BP算法相同,沿着需要优化的参数的负梯度方向不断寻找更优的点直至收敛。
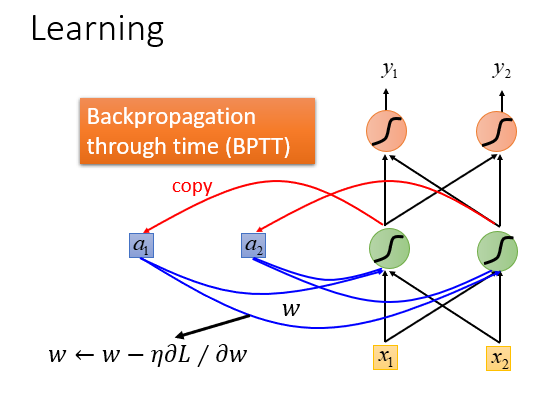
但是用梯度下降算法来求参一般都不是很容易。
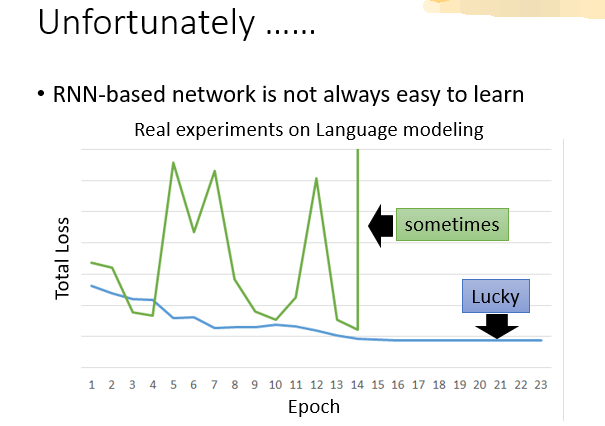
RNN的error surface要么很平坦,要么很陡峭。
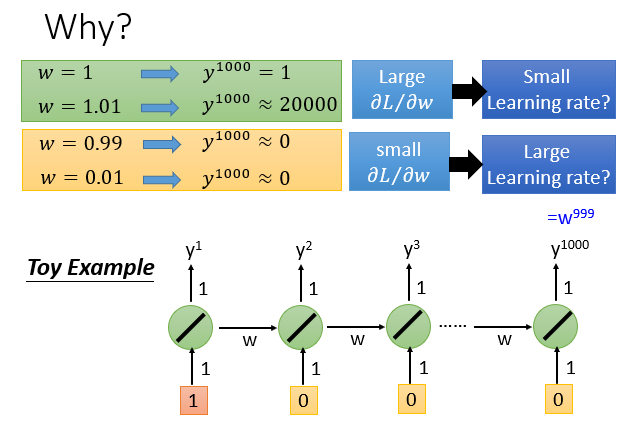
在计算时就会出现gradient vanishing和gradient explosion这两个问题。
-
出现gradient explosion的原因是在普通的RNN中每个时刻neuron的output都会被放到memory中去,所以在每个时刻memory中的值都会被洗掉,导致参数很难改变,很难被训练。
-
出现gradient explosion的原因是参数在训练时对应的Loss值波动太大,因为RNN是一种有记忆的NN,它会参考之前所有的输入数据来处理当前数据,一个微小的参数变化可能就会引发Loss值的剧变,类似于蝴蝶效应。

下图简单说明了这种"蝴蝶效应"。
当然,我们可以借用一些技术去使参数训练变得容易。
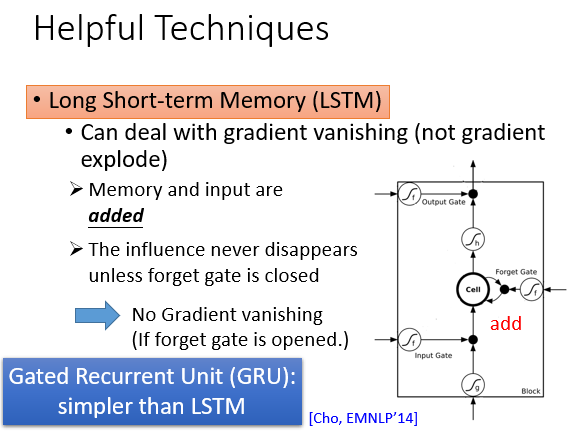
我们可以借助LSTM解决gradient vanishing的问题,即把平坦的部分拿掉。
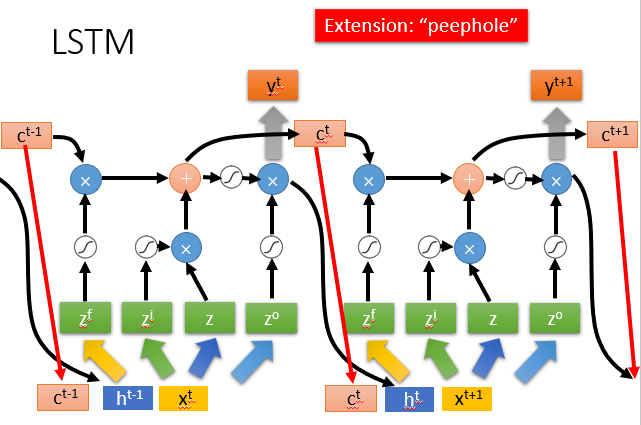
LSTM中前面的数据,参数影响了memory中的值,那么这个影响会永远都存在(除非forget gate决定洗掉memory,有说法认为要给forget gate很大的bias以使其多数情况下开启),而不像SimpleRNN中memory的值在每个时刻都会被洗掉。
但是LSTM还是没有解决gradient explosion的问题,因为RNN处理的是time sequence, 同样的weight在不同时刻被多次使用,即使是LSTM,究其本质还是一种RNN,通病还是去不掉。
若使用LSTM出现了过拟合,可考虑改用GRU。GRU的精神是“旧的不去,新的不来”,它将input gate与forget gate联动起来:若input gate 开,则forget gate 关。
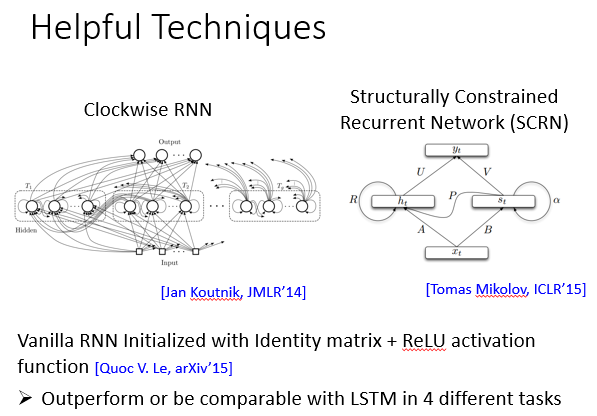
其它处理gradient descent的技巧还有clockwise RNN, SCRN……
如果random初始化一般RNN的weight,那么用ReLU的效果要比用sigmoid的效果差。
但[Quoc V. Le, arXiv’15]提出,如果用单位矩阵初始化一般RNN的weight,那么用ReLU的效果要比用LSTM的效果好。
Applications
RNN的应用有很多,具体如下:
1.输入是一组东西,输出的却是一个,例如下面对电影评论进行归类。

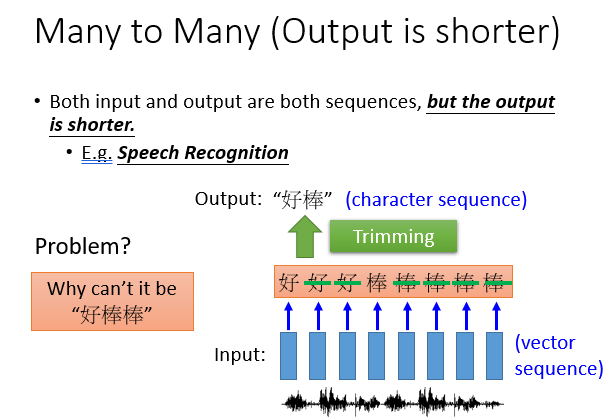
2.输入和输出分别都是多个元素,一组对一组,但是输出相对较短。
例如语音识别,可能输入的是一段音频序列,经过处理得到多个元素,一个字可能对应好多个元素且长度也不等,我们不仅要进行识别,还要想办法处理叠词部分,把它们去掉。
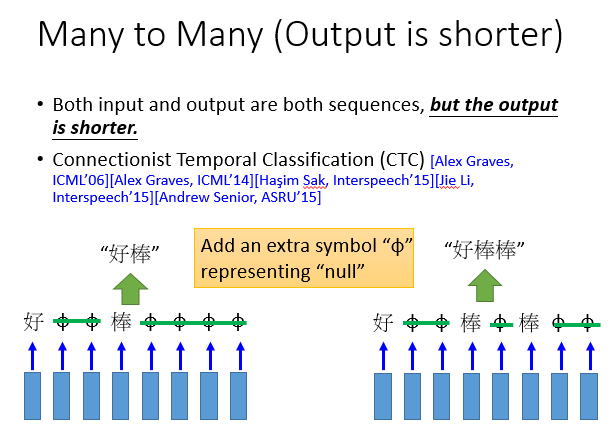
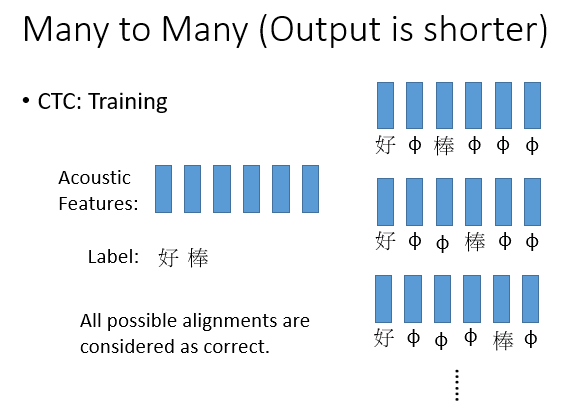
就有这么一种方法,它叫做CTC,这里不做详细说明,大致原理如下:
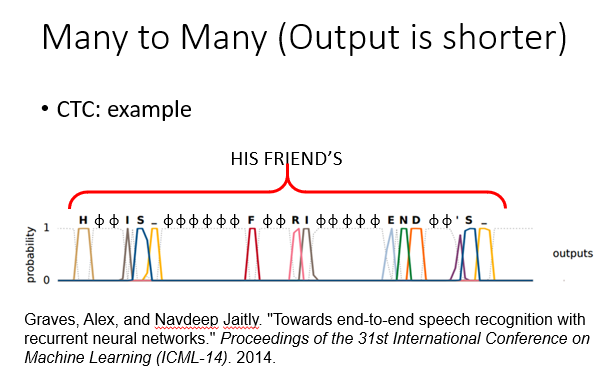
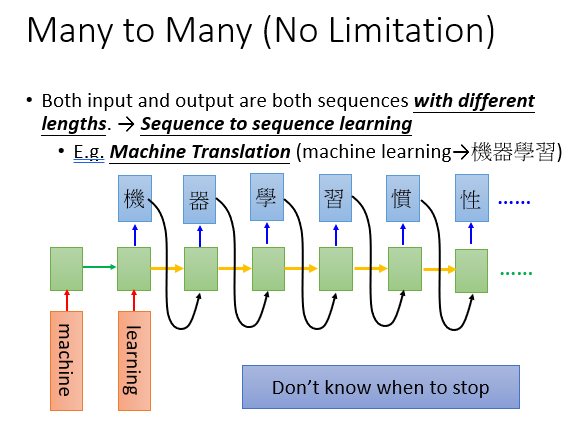
3.输入输出都是一组东西,但是谁长谁短没有限制。
例如文本翻译,这里的难点主要在于让机器何时停下来,如下图,它可能在翻译到习之后还会顺出来"惯"...
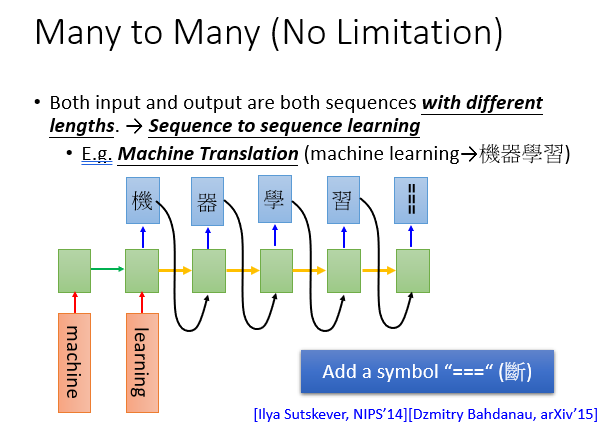

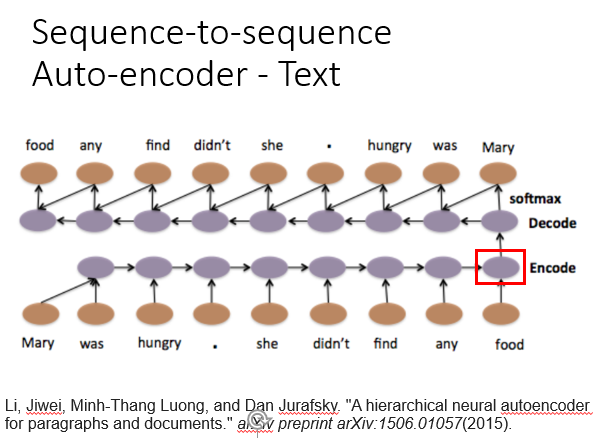
4.文本的编码与解码
之前我们在DNN用backword处理文本时可能会忽略文本语序的问题,例如下图中两个句子单词相同,但是顺序不一致会导致含义截然相反,为避免这种问题,我们就可以用RNN进行文本的编码与解码。

编码(encode)由一个编码器将输入词序列转化成一个固定维度的稠密向量,解码(decode)阶段将这个激活状态生成目标译文。
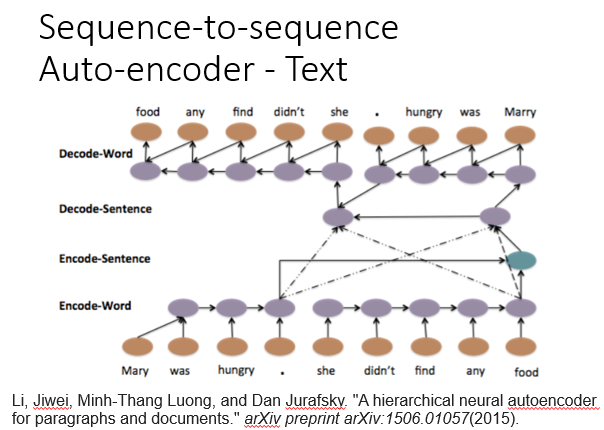
5.语音的编码与解码
语音也是一样,RNN会按自己的一套东西把语音编码为一组数据。听到一组声音,它会对它进行处理并与库中进行比较,凭相似度给出结果,这就是语音识别。
具体在这里不深究,大致原理如下:
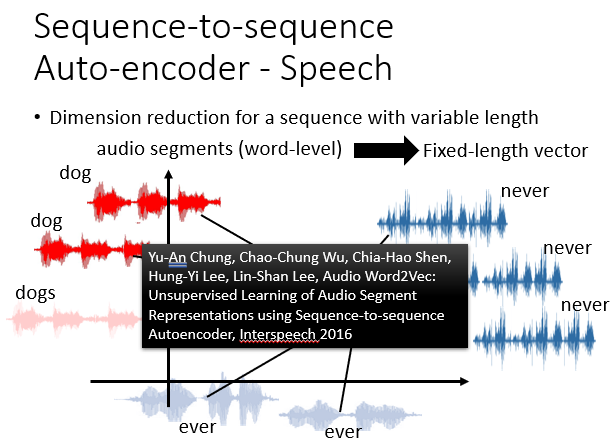
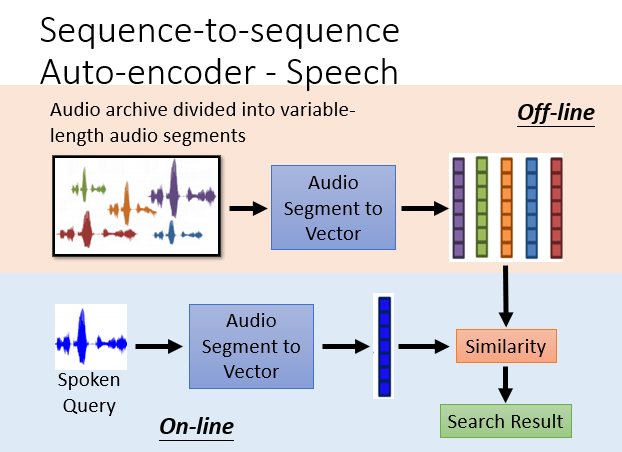

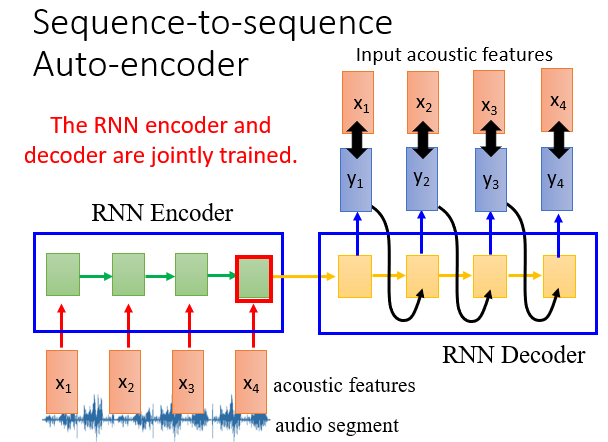

6.其他热门应用
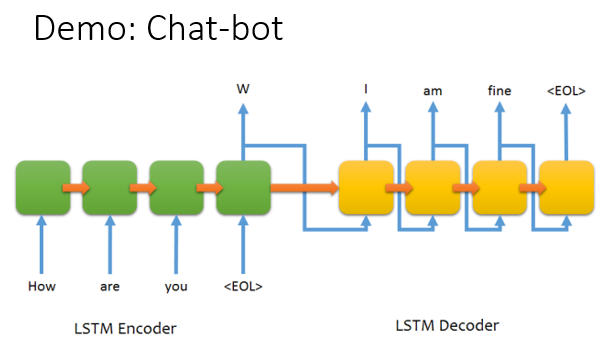
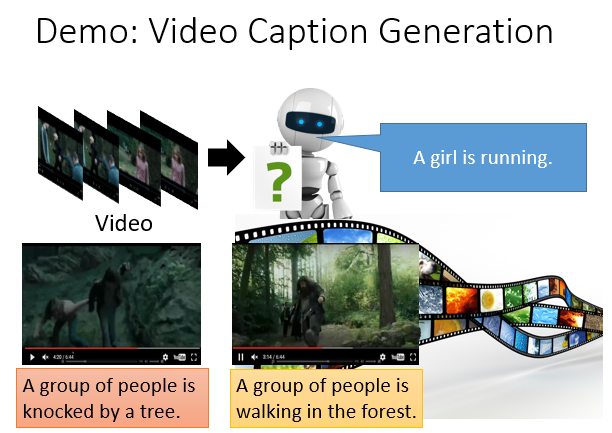
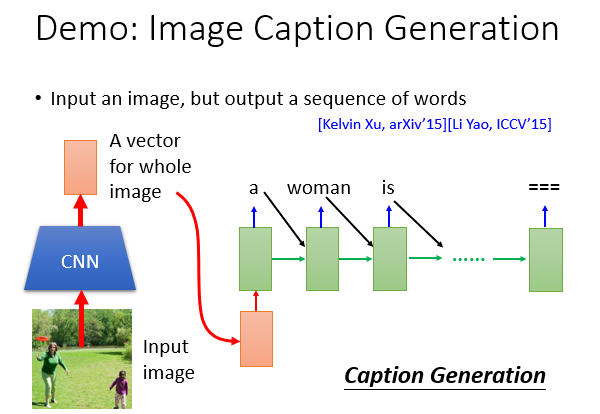
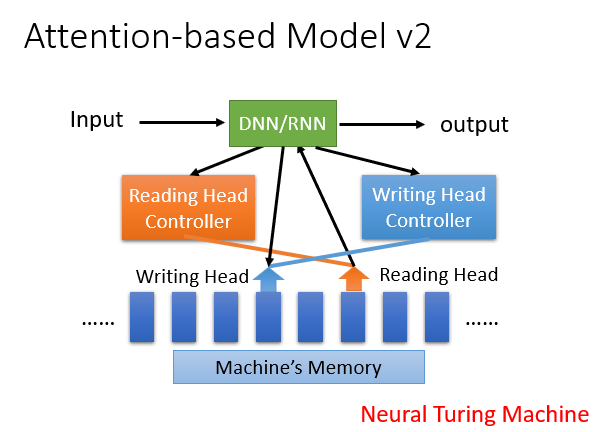
7.Attention-based Model
它模仿了人类可以长期储存记忆并调用的特性。
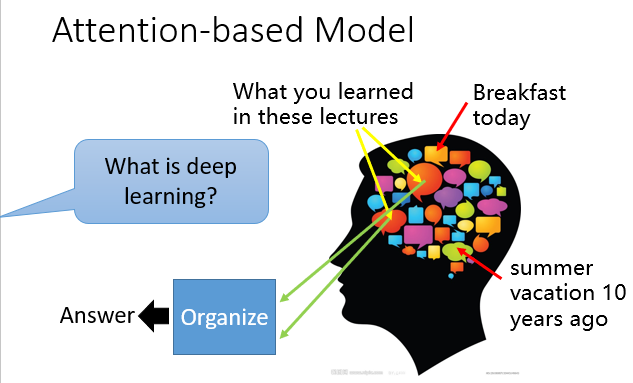
在得到输入后,它会根据输入在记忆中拿取一部分相关数据加入学习中。

进阶版还可以将处理的数据写入到记忆中供日后调用,其实模仿的就是人类。
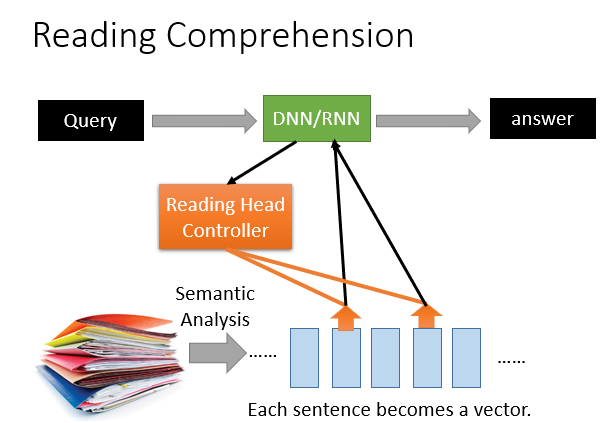
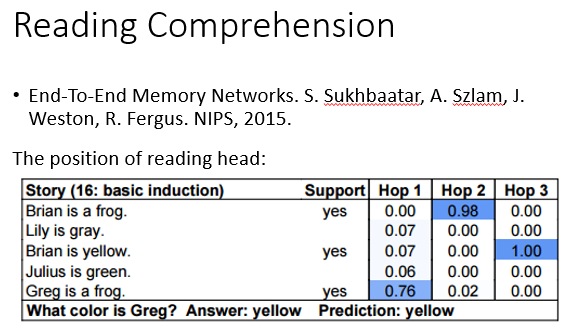
最典型的应用就是做阅读理解,根据问题在原文中找到与之相关的片段加入学习,最终得出答案。
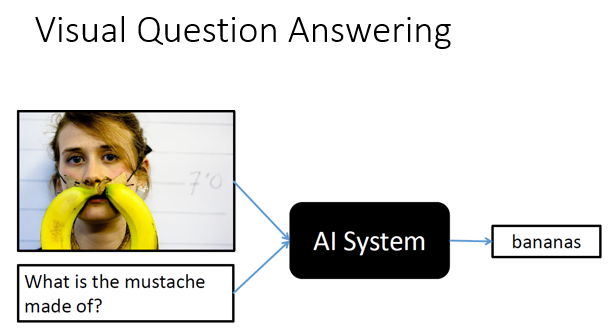
甚至还能处理带有图片的问题,因为图片也被转化为数据,它读完问题后也能拿取有线索的图片进行分析。
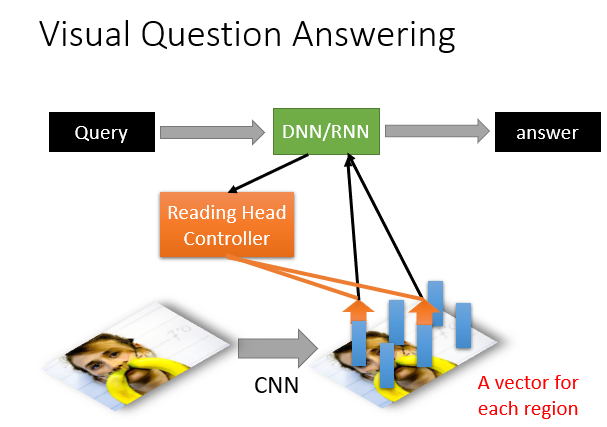
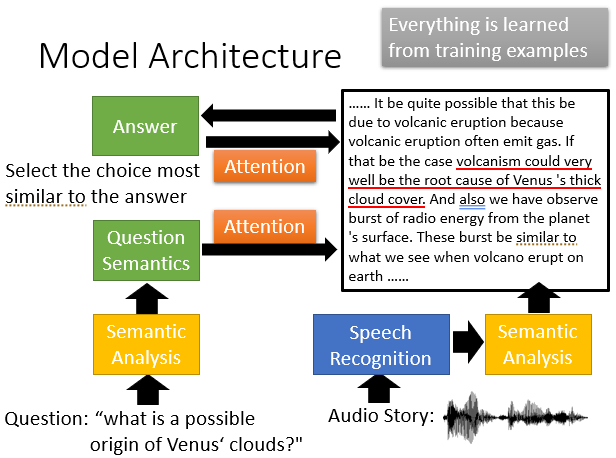
当然,做点英语听力也不是问题。

Comments NOTHING