


tcpdump收集流量
import urllib.request
import subprocess
import os
import time
# 网站列表
websites = ['https://www.qq.com', 'https://www.baidu.com', 'https://www.bilibili.com']
output_dir = 'pcap'
if not os.path.exists(output_dir):
os.makedirs(output_dir)
# 访问每个网站
for website in websites:
# 创建用于存储pcap文件的文件夹
folder_name = website.split('//')[1]
new_folder_name = os.path.join(output_dir,folder_name)
os.makedirs(new_folder_name, exist_ok=True)
# 访问网站5次,每次持续10秒
for i in range(5):
# 设置请求的URL、请求头信息和请求体数据
url = website
headers = {"User-Agent": "Mozilla/5.0"}
data = None
# 运行tcpdump命令并将结果保存为pcap文件
filename = os.path.join(new_folder_name, f'{i}.pcap')
tcpdump_command = ['tcpdump', '-i', 'eth0', '-w', filename]
tcpdump_process = subprocess.Popen(tcpdump_command, stdout=subprocess.PIPE)
# 发送HTTP请求并接收响应
response = urllib.request.urlopen(urllib.request.Request(url, headers=headers, data=data))
# 持续请求5秒钟
for j in range(10):
print(f'正在收集 {website} 的第 {i+1} 次请求的流量,已持续 {j+1} 秒')
time.sleep(1)
# 关闭HTTP连接和tcpdump进程以完成流量收集
response.close()
tcpdump_process.terminate()提取流量特征
import os
import dpkt
def process_pcap_file(pcap_file_path, output_folder):
# 读取pcap文件
with open(pcap_file_path, 'rb') as f:
pcap_data = dpkt.pcap.Reader(f)
packets = list(pcap_data)
# 获取输出文件名
file_name = os.path.basename(pcap_file_path)
output_file_name = os.path.splitext(file_name)[0] + '.txt'
output_file_path = os.path.join(output_folder, output_file_name)
# 处理每个包
with open(output_file_path, 'w') as output_file:
time_base = None
for ts, buf in packets:
# 解析数据包
eth = dpkt.ethernet.Ethernet(buf)
ip = eth.data
tcp = ip.data
# 仅处理TCP数据包
if isinstance(tcp, dpkt.tcp.TCP):
# 获取时间、方向和长度
timestamp = ts
if time_base is None:
time_base = timestamp
time = timestamp - time_base
length = len(tcp)
if tcp.flags & dpkt.tcp.TH_SYN:
direction = 1
elif tcp.flags & (dpkt.tcp.TH_FIN | dpkt.tcp.TH_RST):
direction = -1
else:
direction = 0
if direction != 0:
# 写入输出文件
output_file.write(f'{time}\t{direction * length}\n')
def process_pcap_folder(folder_path, output_folder):
# 遍历文件夹中的文件和子文件夹
for item in os.listdir(folder_path):
item_path = os.path.join(folder_path, item)
if os.path.isfile(item_path) and item.endswith('.pcap'):
# 处理pcap文件
process_pcap_file(item_path, output_folder)
elif os.path.isdir(item_path):
# 递归处理子文件夹
sub_output_folder_path = os.path.join(output_folder, item)
os.makedirs(sub_output_folder_path, exist_ok=True)
process_pcap_folder(item_path, sub_output_folder_path)
# 指定输入和输出文件夹
input_folder = 'pcap'
output_folder = 'feature'
# 处理pcap文件夹
process_pcap_folder(input_folder, output_folder)结果

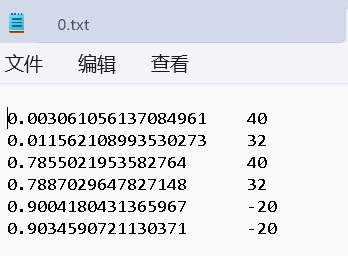
Comments NOTHING