


4.3讽刺数据集训练
这里就是综合前面的词条化,序列化以及嵌入来训练讽刺数据集。
训练
import json
import tensorflow as tf
import numpy as np
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequencesvocab_size = 10000
embedding_dim = 16
max_length = 100
trunc_type='post'
padding_type='post'
oov_tok = "<OOV>"
training_size = 20000
with open("../../tensorflow_datasets/sarcasm.json", 'r') as f:
datastore = json.load(f)
sentences = []
labels = []
for item in datastore:
sentences.append(item['headline'])
labels.append(item['is_sarcastic'])training_sentences = sentences[0:training_size]
testing_sentences = sentences[training_size:]
training_labels = labels[0:training_size]
testing_labels = labels[training_size:]tokenizer = Tokenizer(num_words=vocab_size, oov_token=oov_tok)
tokenizer.fit_on_texts(training_sentences)
word_index = tokenizer.word_index
training_sequences = tokenizer.texts_to_sequences(training_sentences)
training_padded = pad_sequences(training_sequences, maxlen=max_length, padding=padding_type, truncating=trunc_type)
testing_sequences = tokenizer.texts_to_sequences(testing_sentences)
testing_padded = pad_sequences(testing_sequences, maxlen=max_length, padding=padding_type, truncating=trunc_type)model = tf.keras.Sequential([
tf.keras.layers.Embedding(vocab_size, embedding_dim, input_length=max_length),
tf.keras.layers.GlobalAveragePooling1D(),
tf.keras.layers.Dense(24, activation='relu'),
tf.keras.layers.Dense(1, activation='sigmoid')
])
model.compile(loss='binary_crossentropy',optimizer='adam',metrics=['accuracy'])model.summary()Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding (Embedding) (None, 100, 16) 160000
_________________________________________________________________
global_average_pooling1d (Gl (None, 16) 0
_________________________________________________________________
dense (Dense) (None, 24) 408
_________________________________________________________________
dense_1 (Dense) (None, 1) 25
=================================================================
Total params: 160,433
Trainable params: 160,433
Non-trainable params: 0
_________________________________________________________________num_epochs = 30
training_padded = np.array(training_padded)
training_labels = np.array(training_labels)
testing_padded = np.array(testing_padded)
testing_labels = np.array(testing_labels)
history = model.fit(training_padded, training_labels, epochs=num_epochs, validation_data=(testing_padded, testing_labels), verbose=2)Epoch 1/30
625/625 - 2s - loss: 0.6660 - accuracy: 0.5862 - val_loss: 0.5845 - val_accuracy: 0.6742
Epoch 2/30
625/625 - 2s - loss: 0.4308 - accuracy: 0.8305 - val_loss: 0.3860 - val_accuracy: 0.8341
Epoch 3/30
625/625 - 2s - loss: 0.3100 - accuracy: 0.8759 - val_loss: 0.3549 - val_accuracy: 0.8484
Epoch 4/30
625/625 - 2s - loss: 0.2588 - accuracy: 0.8994 - val_loss: 0.3432 - val_accuracy: 0.8550
Epoch 5/30
625/625 - 2s - loss: 0.2231 - accuracy: 0.9130 - val_loss: 0.3431 - val_accuracy: 0.8551
Epoch 6/30
625/625 - 2s - loss: 0.1958 - accuracy: 0.9254 - val_loss: 0.3516 - val_accuracy: 0.8545
Epoch 7/30
625/625 - 2s - loss: 0.1732 - accuracy: 0.9354 - val_loss: 0.3642 - val_accuracy: 0.8544
Epoch 8/30
625/625 - 2s - loss: 0.1556 - accuracy: 0.9426 - val_loss: 0.3962 - val_accuracy: 0.8444
Epoch 9/30
625/625 - 2s - loss: 0.1392 - accuracy: 0.9499 - val_loss: 0.3973 - val_accuracy: 0.8515
Epoch 10/30
625/625 - 2s - loss: 0.1260 - accuracy: 0.9564 - val_loss: 0.4301 - val_accuracy: 0.8445
Epoch 11/30
625/625 - 2s - loss: 0.1135 - accuracy: 0.9619 - val_loss: 0.4554 - val_accuracy: 0.8427
Epoch 12/30
625/625 - 2s - loss: 0.1048 - accuracy: 0.9638 - val_loss: 0.4680 - val_accuracy: 0.8447
Epoch 13/30
625/625 - 2s - loss: 0.0963 - accuracy: 0.9683 - val_loss: 0.5138 - val_accuracy: 0.8359
Epoch 14/30
625/625 - 2s - loss: 0.0866 - accuracy: 0.9719 - val_loss: 0.5260 - val_accuracy: 0.8396
Epoch 15/30
625/625 - 2s - loss: 0.0802 - accuracy: 0.9729 - val_loss: 0.5526 - val_accuracy: 0.8395
Epoch 16/30
625/625 - 2s - loss: 0.0724 - accuracy: 0.9759 - val_loss: 0.6068 - val_accuracy: 0.8317
Epoch 17/30
625/625 - 2s - loss: 0.0663 - accuracy: 0.9793 - val_loss: 0.6216 - val_accuracy: 0.8335
Epoch 18/30
625/625 - 2s - loss: 0.0618 - accuracy: 0.9804 - val_loss: 0.6581 - val_accuracy: 0.8325
Epoch 19/30
625/625 - 2s - loss: 0.0573 - accuracy: 0.9821 - val_loss: 0.7030 - val_accuracy: 0.8235
Epoch 20/30
625/625 - 2s - loss: 0.0533 - accuracy: 0.9829 - val_loss: 0.8125 - val_accuracy: 0.8205
Epoch 21/30
625/625 - 2s - loss: 0.0502 - accuracy: 0.9830 - val_loss: 0.7624 - val_accuracy: 0.8269
Epoch 22/30
625/625 - 2s - loss: 0.0438 - accuracy: 0.9868 - val_loss: 0.7954 - val_accuracy: 0.8237
Epoch 23/30
625/625 - 2s - loss: 0.0417 - accuracy: 0.9869 - val_loss: 0.8923 - val_accuracy: 0.8188
Epoch 24/30
625/625 - 2s - loss: 0.0361 - accuracy: 0.9901 - val_loss: 0.9350 - val_accuracy: 0.8195
Epoch 25/30
625/625 - 2s - loss: 0.0342 - accuracy: 0.9901 - val_loss: 0.9126 - val_accuracy: 0.8190
Epoch 26/30
625/625 - 2s - loss: 0.0331 - accuracy: 0.9904 - val_loss: 0.9527 - val_accuracy: 0.8167
Epoch 27/30
625/625 - 2s - loss: 0.0308 - accuracy: 0.9920 - val_loss: 1.0029 - val_accuracy: 0.8164
Epoch 28/30
625/625 - 2s - loss: 0.0281 - accuracy: 0.9916 - val_loss: 1.0640 - val_accuracy: 0.8141
Epoch 29/30
625/625 - 2s - loss: 0.0238 - accuracy: 0.9933 - val_loss: 1.2568 - val_accuracy: 0.8070
Epoch 30/30
625/625 - 2s - loss: 0.0230 - accuracy: 0.9934 - val_loss: 1.1335 - val_accuracy: 0.8143分析训练过程
由图分析可知,此次训练效果一般。
import matplotlib.pyplot as plt
def plot_graphs(history, string):
plt.plot(history.history[string])
plt.plot(history.history['val_'+string])
plt.xlabel("Epochs")
plt.ylabel(string)
plt.legend([string, 'val_'+string])
plt.show()
plot_graphs(history, "accuracy")
plot_graphs(history, "loss")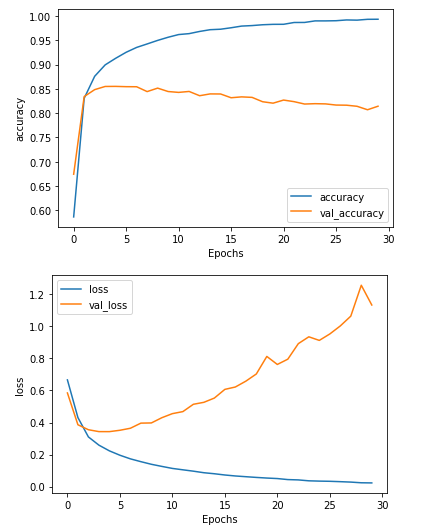
e = model.layers[0]
weights = e.get_weights()[0]
print(weights.shape) # shape: (vocab_size, embedding_dim)
## (10000, 16)可视化嵌入
import io
out_v = io.open('vecs.tsv', 'w', encoding='utf-8')
out_m = io.open('meta.tsv', 'w', encoding='utf-8')
for word_num in range(1, vocab_size):
word = reverse_word_index[word_num]
embeddings = weights[word_num]
out_m.write(word + "\n")
out_v.write('\t'.join([str(x) for x in embeddings]) + "\n")
out_v.close()
out_m.close()
进行预测
通过下述代码进行预测一个句子是否具有讽刺性。
sentence = ["granny starting to fear spiders in the garden might be real", "game of thrones season finale showing this sunday night"]
sequences = tokenizer.texts_to_sequences(sentence)
padded = pad_sequences(sequences, maxlen=max_length, padding=padding_type, truncating=trunc_type)
print(model.predict(padded))
## [[8.9797270e-01]
## [6.3391565e-07]]
Comments NOTHING