


3.3 手写体识别
问题描述
识别0-25这26个数,数据是csv格式,即对应数字的像素分布。
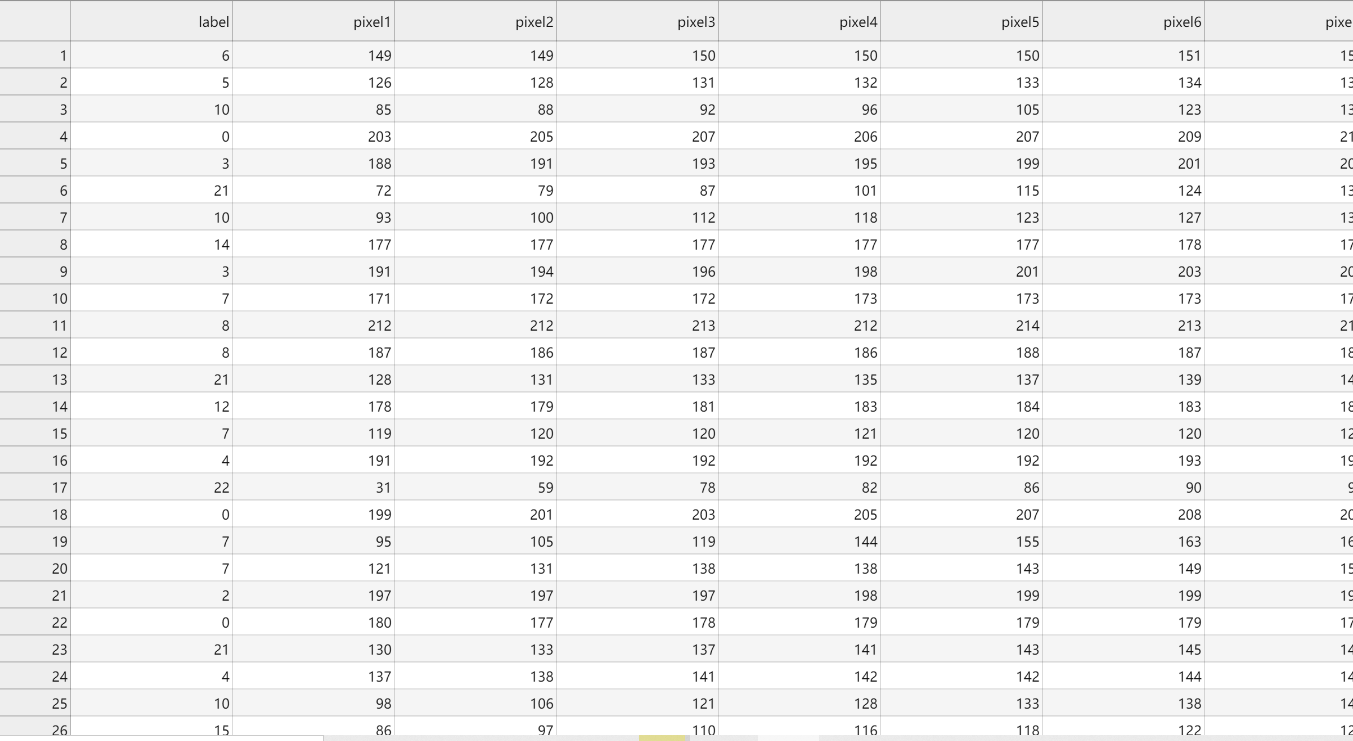
数据预处理
import csv
import numpy as np
import tensorflow as tf
from tensorflow.keras.preprocessing.image import ImageDataGenerator
def get_data(filename):
with open(filename) as training_file:
csv_reader = csv.reader(training_file, delimiter=',')
first_line = True
temp_images = []
temp_labels = []
for row in csv_reader:
if first_line:
# print("Ignoring first line")
first_line = False
else:
temp_labels.append(row[0])
image_data = row[1:785]
image_data_as_array = np.array_split(image_data, 28)
temp_images.append(image_data_as_array)
images = np.array(temp_images).astype('float')
labels = np.array(temp_labels).astype('float')
return images, labels
training_images, training_labels = get_data('sign_mnist_train.csv')
testing_images, testing_labels = get_data('sign_mnist_test.csv')
print(training_images.shape)
print(training_labels.shape)
print(testing_images.shape)
print(testing_labels.shape)(27455, 28, 28)
(27455,)
(7172, 28, 28)
(7172,)training_images = np.expand_dims(training_images, axis=3)
testing_images = np.expand_dims(testing_images, axis=3)
train_datagen = ImageDataGenerator(
rescale=1. / 255,
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode='nearest')
validation_datagen = ImageDataGenerator(
rescale=1. / 255)
print(training_images.shape)
print(testing_images.shape)(27455, 28, 28, 1)
(7172, 28, 28, 1)模型定义及训练
model = tf.keras.models.Sequential([
tf.keras.layers.Conv2D(64, (3, 3), activation='relu', input_shape=(28, 28, 1)),
tf.keras.layers.MaxPooling2D(2, 2),
tf.keras.layers.Conv2D(64, (3, 3), activation='relu'),
tf.keras.layers.MaxPooling2D(2, 2),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(128, activation=tf.nn.relu),
tf.keras.layers.Dense(26, activation=tf.nn.softmax)])
# Before modification
# model.compile(optimizer = tf.train.AdamOptimizer(),
# loss = 'sparse_categorical_crossentropy',
# metrics=['accuracy'])
#
# After modification
model.compile(optimizer = tf.optimizers.Adam(),
loss = 'sparse_categorical_crossentropy',
metrics=['accuracy'])
history = model.fit_generator(train_datagen.flow(training_images, training_labels, batch_size=32),
steps_per_epoch=len(training_images) / 32,
epochs=5,
validation_data=validation_datagen.flow(testing_images, testing_labels, batch_size=32),
validation_steps=len(testing_images) / 32)
model.evaluate(testing_images, testing_labels)Epoch 1/15
858/857 [==============================] - 24s 28ms/step - loss: 2.8346 - accuracy: 0.1390 - val_loss: 2.0034 - val_accuracy: 0.3611
Epoch 2/15
858/857 [==============================] - 24s 28ms/step - loss: 2.1808 - accuracy: 0.3113 - val_loss: 1.6024 - val_accuracy: 0.4413
Epoch 3/15
858/857 [==============================] - 24s 28ms/step - loss: 1.8357 - accuracy: 0.4080 - val_loss: 1.2396 - val_accuracy: 0.5455
Epoch 4/15
858/857 [==============================] - 23s 27ms/step - loss: 1.5816 - accuracy: 0.4843 - val_loss: 1.0176 - val_accuracy: 0.6177
Epoch 5/15
858/857 [==============================] - 23s 27ms/step - loss: 1.4129 - accuracy: 0.5408 - val_loss: 1.0217 - val_accuracy: 0.6460
Epoch 6/15
858/857 [==============================] - 24s 28ms/step - loss: 1.2887 - accuracy: 0.5829 - val_loss: 0.8568 - val_accuracy: 0.7097
Epoch 7/15
858/857 [==============================] - 23s 27ms/step - loss: 1.1790 - accuracy: 0.6110 - val_loss: 0.8046 - val_accuracy: 0.7154
Epoch 8/15
858/857 [==============================] - 23s 27ms/step - loss: 1.1048 - accuracy: 0.6346 - val_loss: 0.7046 - val_accuracy: 0.7658
Epoch 9/15
858/857 [==============================] - 24s 28ms/step - loss: 1.0506 - accuracy: 0.6494 - val_loss: 0.5894 - val_accuracy: 0.7939
Epoch 10/15
858/857 [==============================] - 24s 27ms/step - loss: 0.9842 - accuracy: 0.6732 - val_loss: 0.5881 - val_accuracy: 0.7893
Epoch 11/15
858/857 [==============================] - 23s 27ms/step - loss: 0.9247 - accuracy: 0.6924 - val_loss: 0.5618 - val_accuracy: 0.8265
Epoch 12/15
858/857 [==============================] - 23s 27ms/step - loss: 0.8841 - accuracy: 0.7070 - val_loss: 0.5434 - val_accuracy: 0.8130
Epoch 13/15
858/857 [==============================] - 24s 27ms/step - loss: 0.8422 - accuracy: 0.7228 - val_loss: 0.6367 - val_accuracy: 0.7743
Epoch 14/15
858/857 [==============================] - 23s 27ms/step - loss: 0.7952 - accuracy: 0.7332 - val_loss: 0.5824 - val_accuracy: 0.8040
Epoch 15/15
858/857 [==============================] - 24s 28ms/step - loss: 0.7751 - accuracy: 0.7463 - val_loss: 0.5417 - val_accuracy: 0.7984
225/225 [==============================] - 1s 6ms/step - loss: 309.7298 - accuracy: 0.5199
[4]:
[309.7298278808594, 0.5199386477470398]分析
可以作图来分析一下此次训练。
本次由于数据集过小,会出现反弹现象,测试集上面的效果比训练集要好一些,当然从上面的训练过程也不难看出。
import matplotlib.pyplot as plt
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(len(acc))
plt.plot(epochs, acc, 'r', label='Training accuracy')
plt.plot(epochs, val_acc, 'b', label='Validation accuracy')
plt.title('Training and validation accuracy')
plt.legend()
plt.figure()
plt.plot(epochs, loss, 'r', label='Training Loss')
plt.plot(epochs, val_loss, 'b', label='Validation Loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()图略。
Comments NOTHING