


Classification: Logistic Regression
Review
上一节我们已经了解了用Generative去进行一个Classification,我们最后讨论了边界会呈线性的原因。并提出疑问能不能直接确定表达式中的参数w和b,而不通过Generative进行计算?
引出今天的要学习的另一种分类算法:Logistic Regression
Logistic Regression(逻辑回归)
Step 1:以下依旧假设是二元分类,根据上节的计算我们得出我们的Model是一个关于z的函数δ(z).

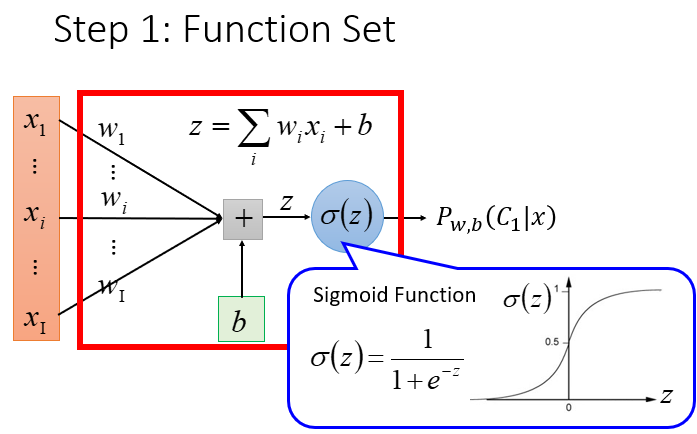
Step 2:我们要做的是找到一组参数w*和b*,使出现我们这个Traning Data的概率最大,我们可以把出现每一个数据概率的乘积作为我们的评估函数,这个评估函数L(w,b)越大说明w,b参数的值选的越好。

直接观察这个评估函数发现它是一个乘积式,我们处理起来很复杂,后续计算w*和b*也很复杂,将其转化为求-lnL(w,b)取最小值时的w*和b*,形成新的评估函数。
并且把数据的类别用数值1和0来替代。

对这个新的评估函数进行化简后发现它类似两个伯努利分布的Cross entropy(交叉熵);
交叉熵越接近0,就表示这两个分布越接近,我们的Model就越能预测数据的一个分类。

所以我们要得到最好的预测效果,就是想办法让这个交叉熵最小化。

Step 3:计算最好的参数,依旧使用之前的Gradient Descent算法。
前一部分对w求偏微分:
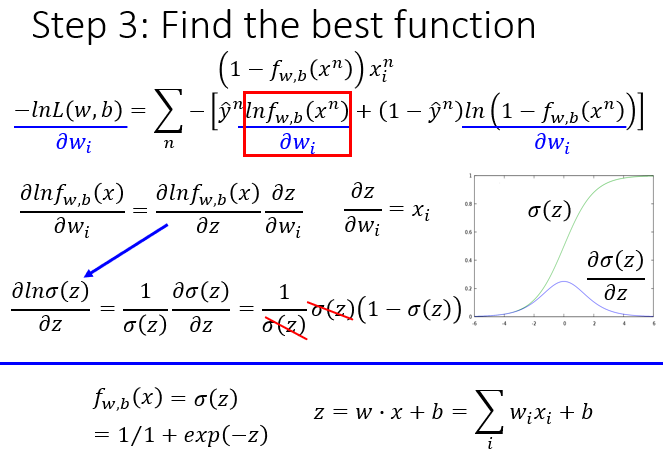
后一部分对w求偏微分:

然后得到下一个w,和之前的梯度下降类似。

Logistic Regression + Square Error
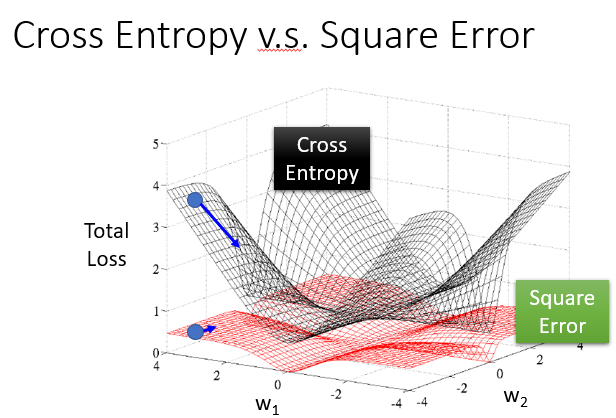
如果我们使用Logistic Regression的Model,然后在第二步设计损失函数时图省事,使用了Gradient Descent的损失函数(平方误差损失函数),不使用我们上面提到的交叉熵,会出现什么后果?
我们会发现不管结果是否接近真实效果(预期效果),我们都很难调整这个参数,因为它的微分值(变化率)始终会是0,就是很难去调整它。


如图,使用简单的平方误差很难调整参数以达到最好的效果。但当我们使用交叉熵时就很好,它在离目标较远时有一个很快的变化速率,然后在接近目标时变得平缓。
Logistic Regression(逻辑回归) 与 Linear Regression(线性回归)
- Logistic Regression的Model的Output会在0和1之间,它的数据的真实值只会是1或0(因为是一个二元分类),使用的损失函数为交叉熵。
- Linear Regression的Model的Output会是一个任意的值,它的数据的真实值也会是一个随机的真实数据,使用的损失函数为平方误差。
但是奇异的是,它们最终推导的参数迭代式竞会一模一样。

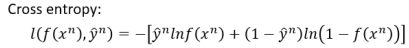
Discriminative(判别模型) 与 Generative(生成模型)
这节课我们学习的判别模型中参数是通过直接计算得到的,与上一节中讲到的生成模型还是有很大区别的。其中最关键的是,上一节中的生成模型中间有假设环节,我们通过已有的数据计算摇出指定数据的概率时,就假设整体是一个高斯分布。
并且使用同一份训练数据,两种模型训练出来的最好参数也不会相同。

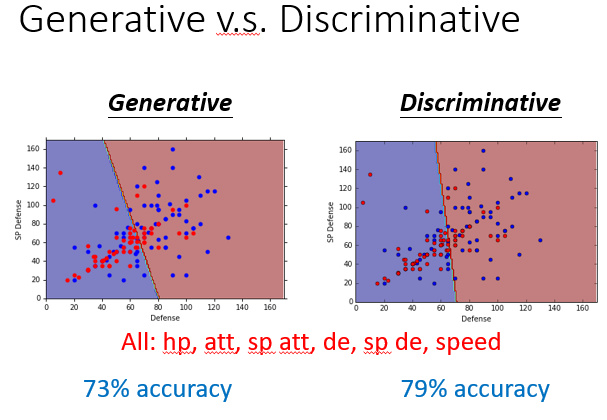
大家可以看一下预测的准确率,判别模型一般是要比生成模型的准确率要高;因为在绝大多数条件下假设都是不太好的。
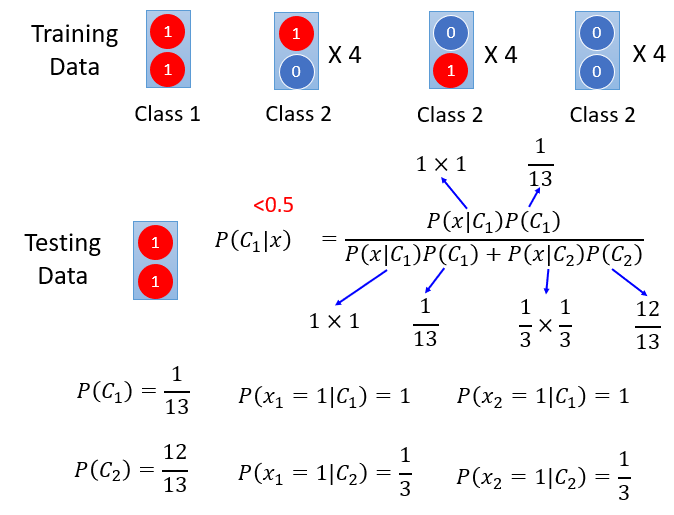
在下面这个简单的例子中,人眼一下就能看出两个红球应该归为Class 1(虽然众多实例中只有一份支持我们的判断),但是如果使用一个生成模型,它可能会假设盒子中的两个球相互独立,然后经过一系列计算,并不会把它归为Class 1.

所以我们得出:
一般使用判别模型会比较好。
以下情况选用生成模型可能更佳:
- 当我们的训练数据比较少,必须要求我们进行一个假想。
- 我们的数据本身就是一个有噪声的数据,通过假设可能有一个修复效果。
- 因为我们进行了一个假设,他可能更适应不同源头的一个数据,就像之前我们取编号小于400的宝可梦,使用生成模型得出的结果还是能适应于编号大于400号的宝可梦。

对于多元分类
这个Model的建立方法我们先进行了解,详细参考Bishop。
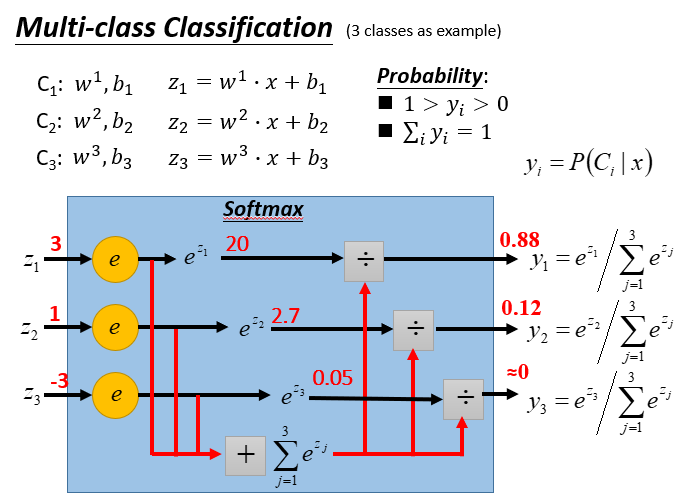
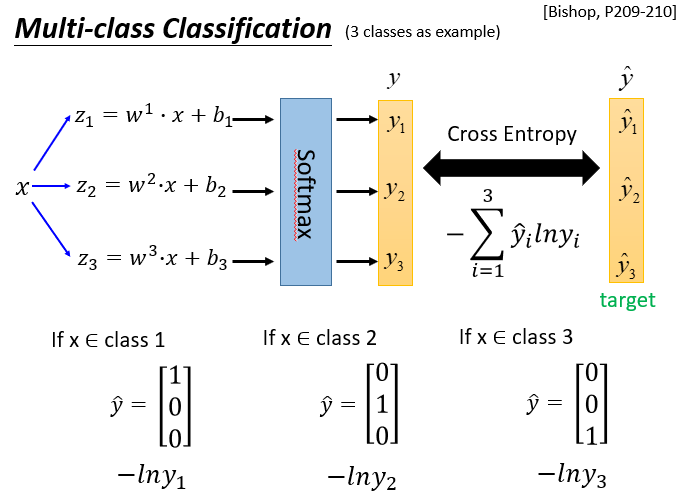
就是进行一个softmax,放大和三个类别的相似度,然后进行归类,看图:
Limitation of Logistic Regression
下述是一个简单的分类,输入的数据有两个特征,这两个特征不同就归为Class 1,相同就对归为Class 2.
这个对于人类来说并不难,但是让机器去做这样一件事,特别是我们的分类边界还是线性的,根本没法划分。

对于这种情况,我们只能进行特征转换,将输入的特征转换为机器能划分的数据。
在这个例子中就可以将特征一转换为到(0,0)的距离,将特征二转换为到(1,1)的距离。但是这样做并不总是容易的。
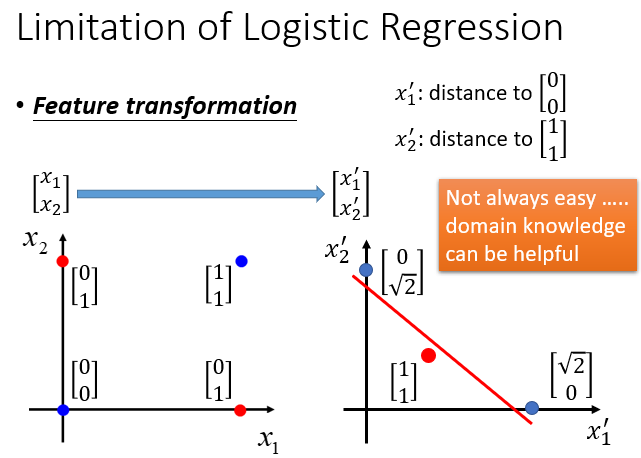
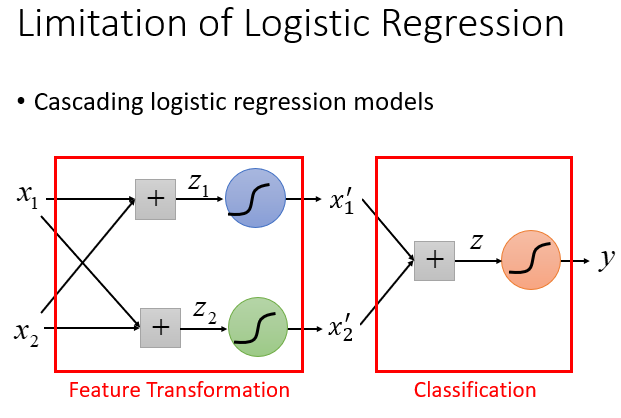
所以我们要设计一个级联的逻辑回归模型,去调整数据的特征。
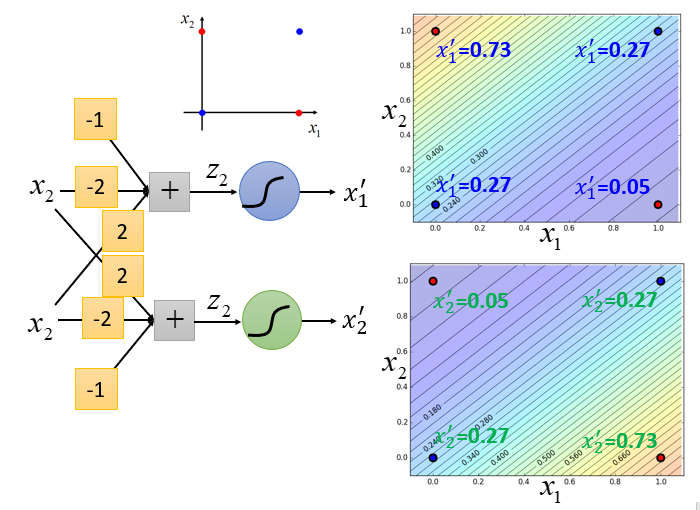
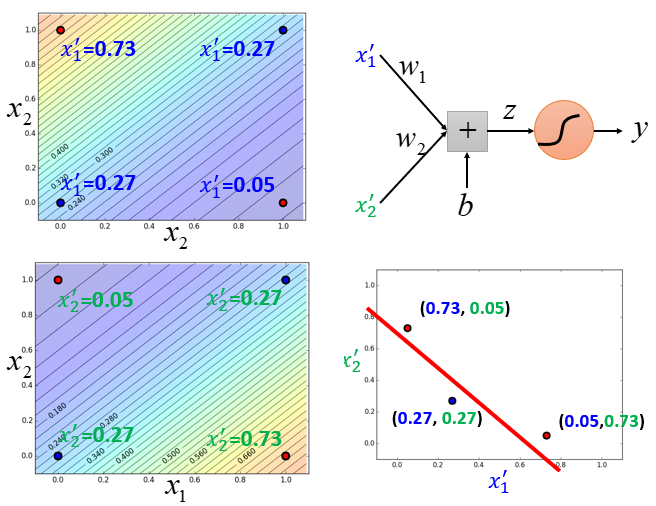
可以看到在使用级联逻辑回归模型后,机器就能进行划分了,达到预期效果。
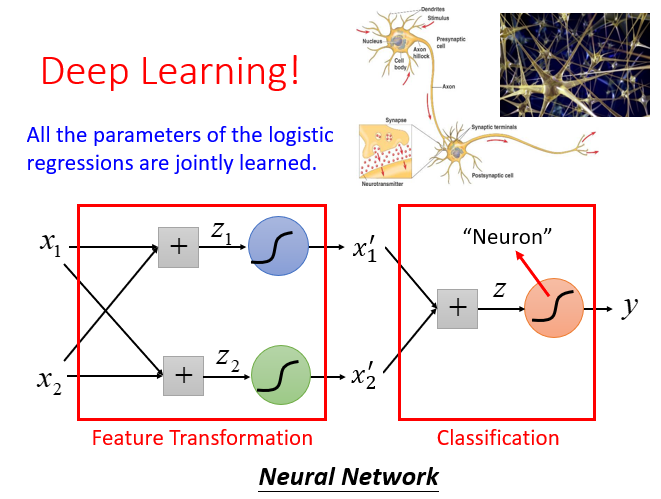
在所有的参数都加入学习之后,
一个Logistic Regression的input来自上一个Logistic Regression的output,同时它的output也会作为下一个Logistic Regression的input...逐级叠加,最终就会形成类神经网络。
引出我们接下来要学习的:Deep Learning
Comments NOTHING