


19.Transformer
简介
首先,我们需要明确Transformer是一个Seq2Seq的模型,输入是一个序列,输出也是一个序列。它由Encoder和Decoder两部分组成,结构图如下:
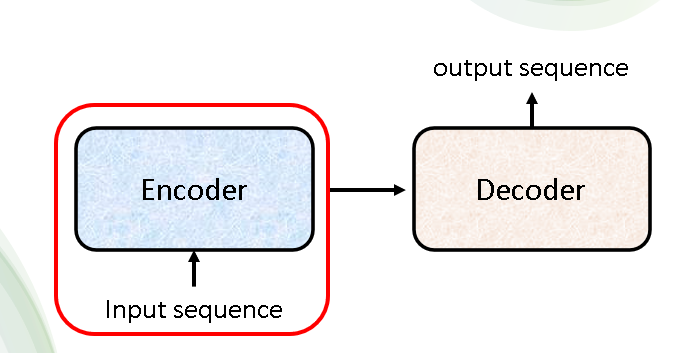
整个Transformer模型全貌如下:

Encoder
Encoder所做的工作就是输入一个序列,然后输出一个强化的序列,它包含更多的信息。
Encoder由多个Block组成,每个Block中都进行了self-attention处理。
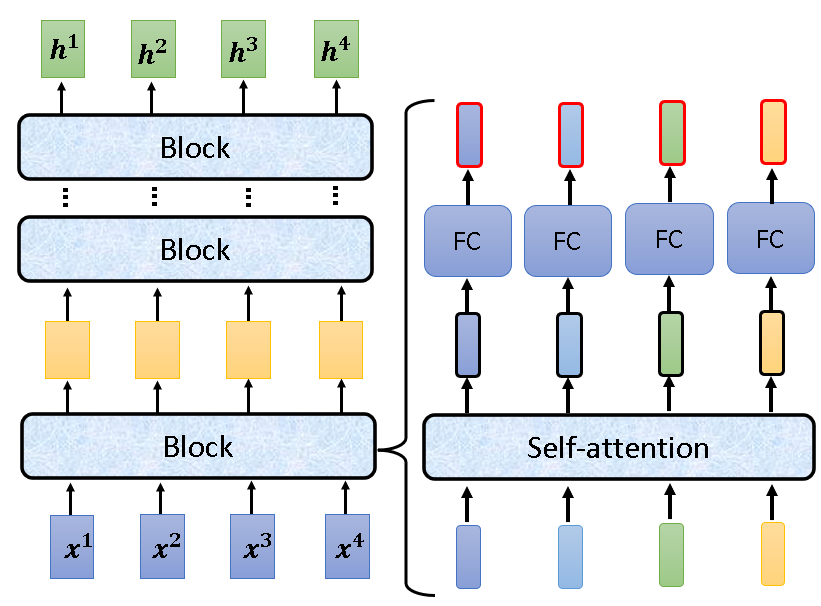
但是其中每一块进行的self-attention不是上一节中最基础的那种,它加上了位置信息,使用了多头注意力机制,使用了residual connection,还使用了Layer Normalization。如下图右边的部分就是Encoder的一个块,像这样的块有N个。

其中添加位置信息和使用多头注意力机制我们已经有所了解,接下来我会简单讲解residual connection和Layer Normalization。
-
residual connection:即残差连接,它会将一个网络的输入加到它的输出上,主要是预防梯度消失。
-
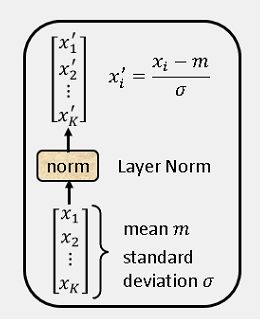
Layer Normalization:即层标准化,相比于 Batch Normalization,它不是将个多个输入向量的同一维度标准化,而是将一个向量的不同维进行标准化。它输入一个向量,输出一个向量。下图中有Layer Normalization的具体做法。
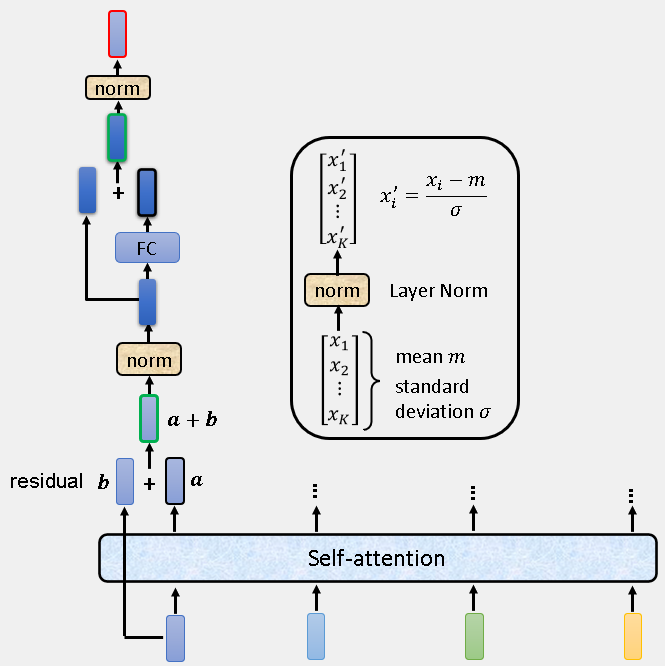
好了,做了这么多铺垫,我们来具体看一下Encoder的一个块里面具体有哪些东西,如下图:
文字总结一个块:Input 先加上位置信息后,经过一个多头注意网络(residual connection),然后进行Layer Normalization,再经过一个全连接层(residual connection),再进行一次Layer Normalization,之后Output输出。
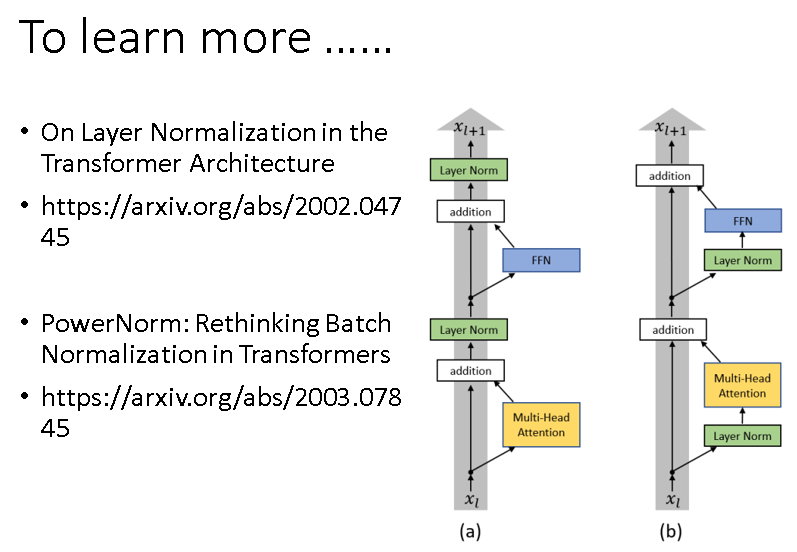
我们需要明白一点,原始的Encoder中的一个块内的各部分是按上述结构组织的,但是随着时间的发展,诞生了效果更好的组织方式。下图中右边这种组织方式的效果就比左边原始的要好。
Decoder
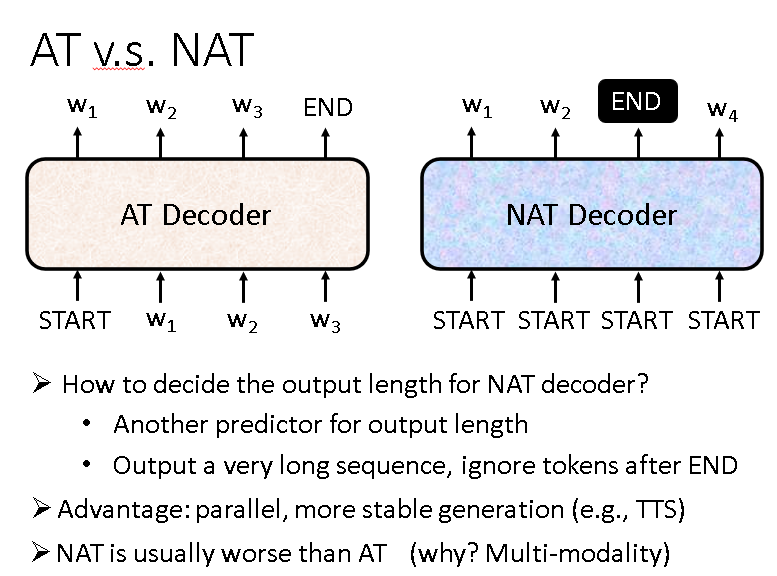
首先,Transformer的Decoder有两种,一种是Autoregressive,另外一种是Non-Autoregressive。
我们先对Autoregressive进行讲解:
Autoregressive,简称AT。它的输入有两部分:Encoder的输出和自己前一时刻的输出(刚开始输入start)。它的输出虽然是一个序列,但其中的元素是一个一个输出的,当然什么时候停止输出也是靠学习得到。
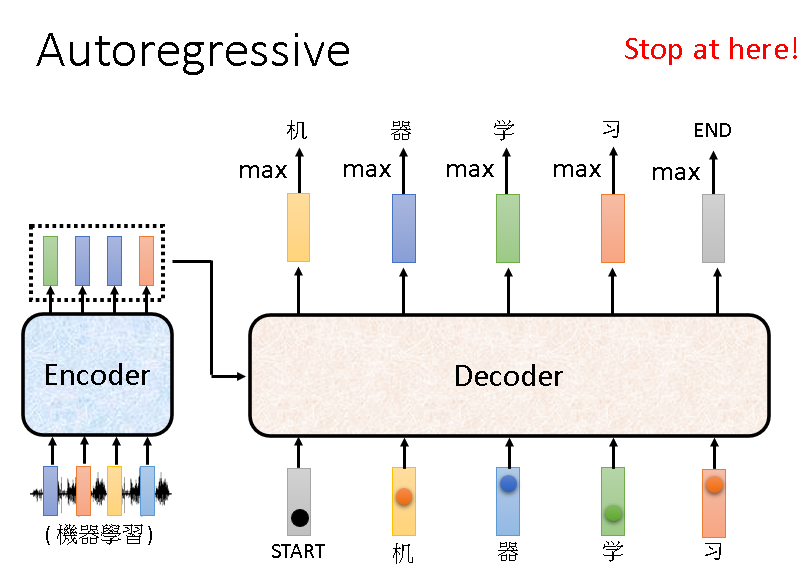
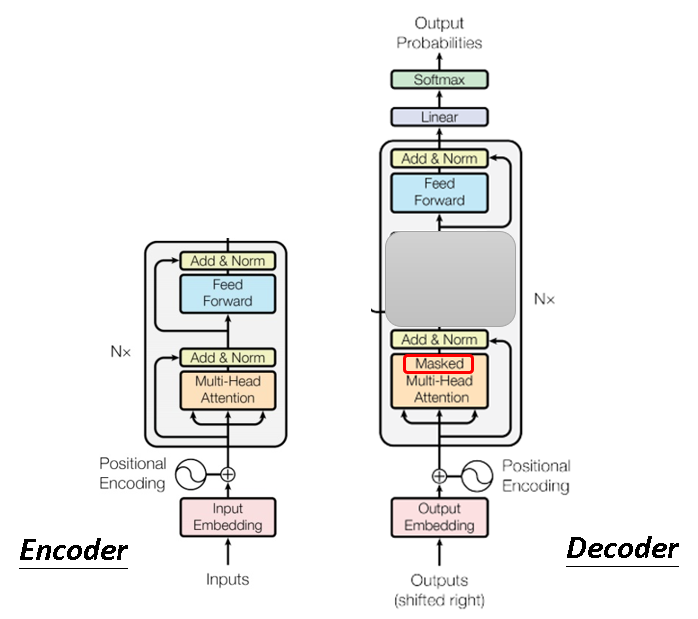
Decoder也由很多块组成,下图的右边展示的就是Decoder中的一块,可以看到它比Encoder还要复杂。

但是我们像下面这样把Decoder的中间那一块给遮住的话,会发现剩下的和Encoder其实是差不多的结构,只是把Multi-Head Attention换成了Masked Multi-Head Attention。
需要注意的是,中间被遮掉的那部分刚好是Decoder连接Encoder的部分,这部分会在下一节中进行讲解。
所以先弄懂剩余部分即可!
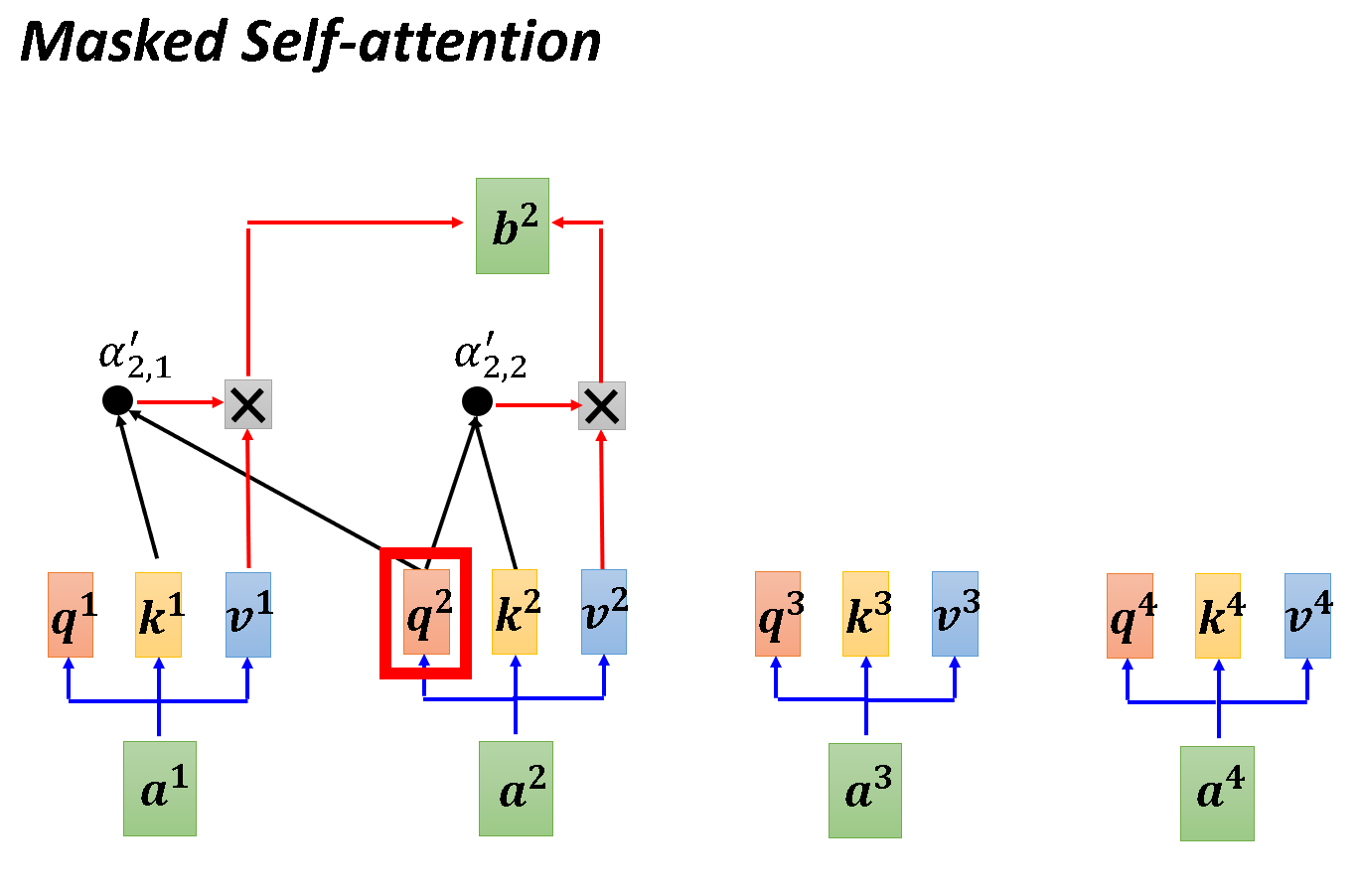
那什么是Masked Self-attention?
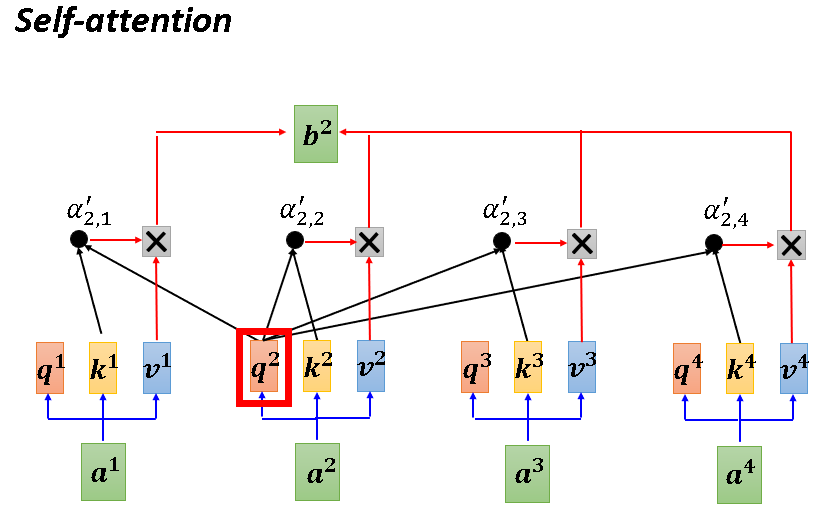
在Self-attention中,每一个向量都会考虑它和所有向量的联系,然后输出结果。

但在Masked Self-attention中,每一个向量只考虑它之前的向量。如下图,生成b1时只考虑a1,生成b2时只考虑a1,a2...
为什么要使用Masked Self-attention呢?
这是因为Autoregressive这种Decoder的输出是一个字一个字崩的,而且只有前一个输出再次输入Decoder中才会产生下一个输出。举个例子,在产生b2的时候你只有a1,a2能考虑,你根本没有a3和a4。

OK,我们通过下述两幅图再理解一下Self-attention和Masked Self-attention的不同运作方式(以产生b2为例)。
接下来是另外一种Decoder:Non-Autoregressive,它简称NAT,这种Decoder它所有的输出是一起产生的(平行化),而且它还能灵活控制输出的长度。
虽然和AT相比NAT有众多优点,但是NAT的效果一般没有AT好,这是Multi-modality这个问题造成的,在这里不多作解释,感兴趣可以另行了解。
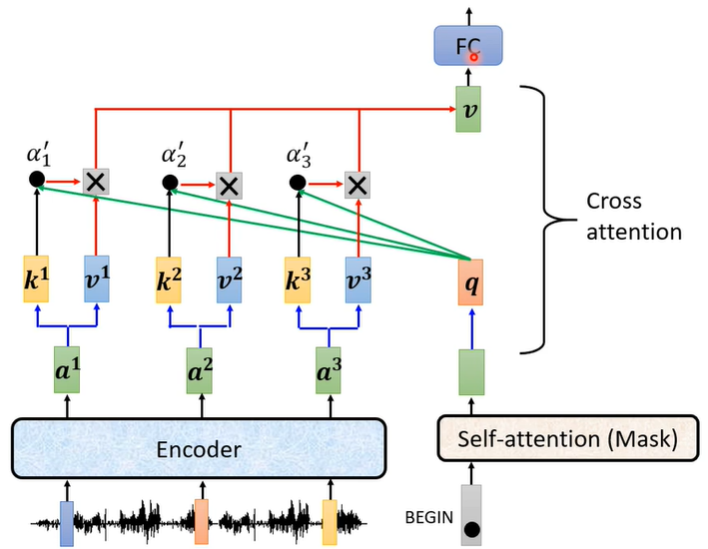
连接部分
在学习完Encoder与Decoder之后,剩下的就是连接部分了,这部分被设置在Decoder里面,就是刚刚遮住的那部分。
连接部分所做的工作就是一个交叉注意,它有三个输入,其中有两个来自Encoder,另外一个来自Decoder。

连接部分具体运转如下图:
来自Encoder的两个输入分别是Encoder输出所产生的key和value。
另一个来自Decoder的输入是连接部分之前的输出所产生的query。
一句话概括此过程:Decoder用自己中间层输出产生query,然后去Encoder中抓取信息。
关于训练
关于训练,因为输出的每一项仍旧是一个个分类问题,所以还是最小化交叉熵那一套东西。
但是由于AT的后一个输出依赖前一个输出,所以为了避免一步错步步错这种情况。在训练时,可以主动给一些错误的输入,这样可以提升模型鲁棒性。
Comments NOTHING