


16.Explainable ML
Introduction
我们做一个ML,不仅希望能得到我们想要的结果,更希望知道它为什么会得出这个结果,因为这样更有说服力,证明是正确的。
所以引出Explainable ML,能帮我们更好得理解机器学习。
一个Explainable ML,有两个需要解决的问题,即Local Explanation和Global Explanation。例如在猫狗分类实验中,它们分别解决了“某张图片为什么会被认为是猫?”和“什么样的图片会被认为是猫?”
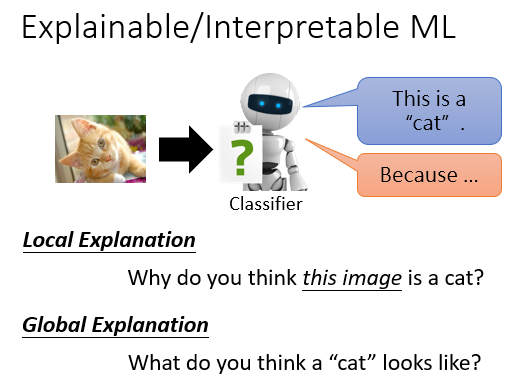
此外,拥有一个可以解释的ML,我们能更好的,更有针对得对其进行优化。

当然,Explainable ML并不是让你完全理解模型内部是如何运转的,就像宏毅老师说的那样,就是让你感觉很爽,然后对我们的训练还有一些积极的促进作用。

那么此时就该考虑了,大部分的DNN它们的内部都很复杂,想要解释清楚几乎是一件不可能的事,用简单的linear model可能很好解释但是它又比较弱,这个选择难题就摆在了我们面前。

Local Explanation
我们想做到Local Explanation,也就是想办法知道此次结果为什么是我们想要的。
基本思想就是控制变量得让输入每次拿掉一些元素,观察对结果的影响,如果某一块对结果影响较大,我们就可以说是这一块支持了我们的结果。
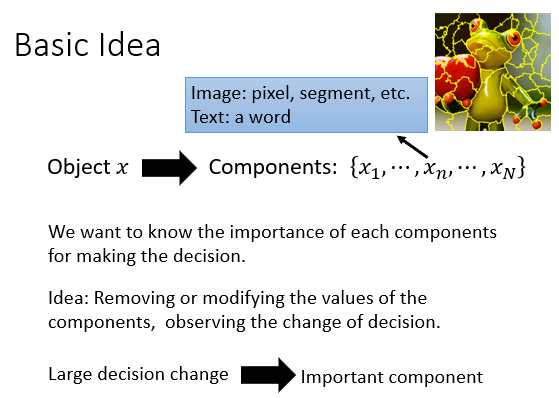
就像下面如果我们将某一部分用灰色方块码住后不能再次正确识别,我们就认为其比较重要。此时再结合我们的思维,就像图一中的小狗,我们把它的脸堵住,发现结果坏的厉害,那么我们就知道机器确实是看到了狗狗的脸推断出这是一只小狗,而不是其他的背景什么奇怪的东西。

我们可以通过上述方法,可以用偏微分算出输入的每一块对我们作出判断的影响的大小,然后作出Saliency Map这种图。其中影响越大的点在图中会越亮。
这样我们能发现机器并不是在胡说,它确实有学习到识别的方法。

那既然机器能很好得去学习,我们Explainable ML的目的是什么?
其实机器有时候做得并不好,可能只是误打误撞得到了我们期待的结果,可能它在胡乱分析,Explainable ML就是为了发现这种情况。下面有一个很有趣的实验,识别一个pet是神奇宝贝还是数码宝贝。

好,素材都有了,开始实验。

随便整一下CNN让它训练,最后突然发现竟然有98%多的正确率,高呼 好耶!但是但是...继续看!

但是当我们作出Saliency Map的时候,我们发现事情并不是我们想的那样简单,发现对结果影响大的点都在背景上,压根不在主体上...


这是怎么回事呢,原来我们的素材中大部分神奇宝贝是png格式的,也就是透明底,读进去训练是黑色的。也就是说机器是根据背景识别的,我滴乖乖...如果不是做了Explainable ML,真相信了机器的鬼话了!

此外,在做Explainable ML时,我们可能会相遇到下面的问题。
就是在计算偏微分时,某一块明明影响很大,却被算成了没有影响。就像根据鼻子长度来判断一个动物是不是大象时,在鼻子长度达到一定长度后,计算结果显示鼻子长度影响确实不大,但我们知道这并不是真的没影响。所以我们要小心应对!
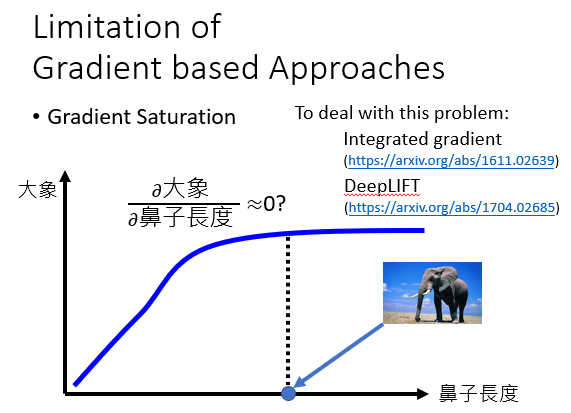
有时候我们的数据混入了噪声,虽然并没有影响我们的结果,但是作出判断的依据却发生了改变。Explainable ML能帮我们发现这种情况!

Global Explanation
前面说过Global Explanation解决的是"机器眼中的猫到底长啥样"?
我们复习一下之前学过的方法Activation Minimization,就是找一个素材能让对应的结果的值最大,就能知道机器眼中什么样的素材最标准。
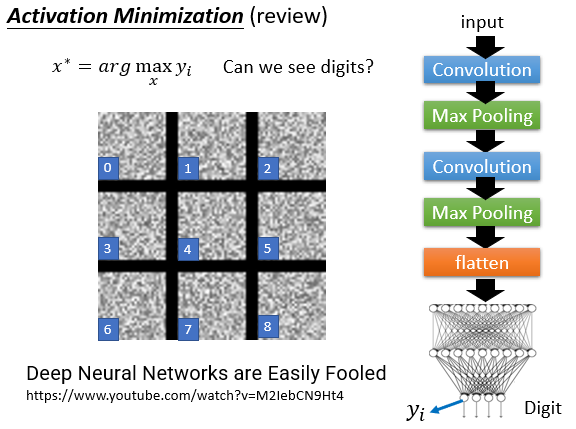
当然如果像上面那样直接用arg函数来确定这个最佳对象,可能会形成根本看不懂的图,而且在人眼看来毫无特征。
此时可以在后面加上一项R(x),可以让图中的像素点更集中。

下面是某位大佬找到的计算机认为最标准的动物图片,当然这是需要很复杂的调参才能有的结果,尤其是刚才说的后面的正则项。

想让机器看看哪个最标准,也得有图吧,那么图片该怎么生成呢?整个流程如何?
我们可以先用GAN等方法训练出一个图片生成器,它的输入部分是一个低维数组。
然后再连接一个图片分类器,这个也是提前训练好的。在随后的找的过程中图片生成器和分类器的参数都保持不变。仅通过改变输入的低维数组让分类器的输出最大。
最后在将这个低维数组放入单独的图片生成器中可视化就行了。
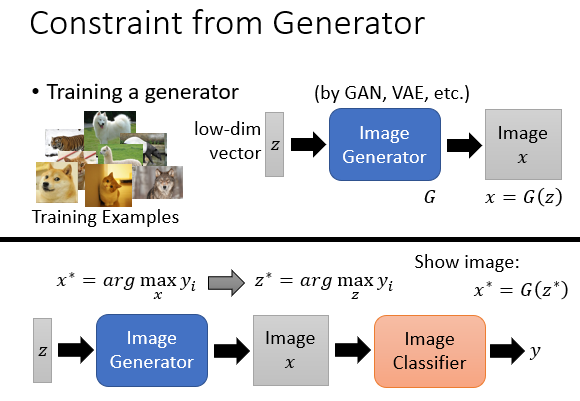
你可能不敢相信,下面是机器认为的“标准”。

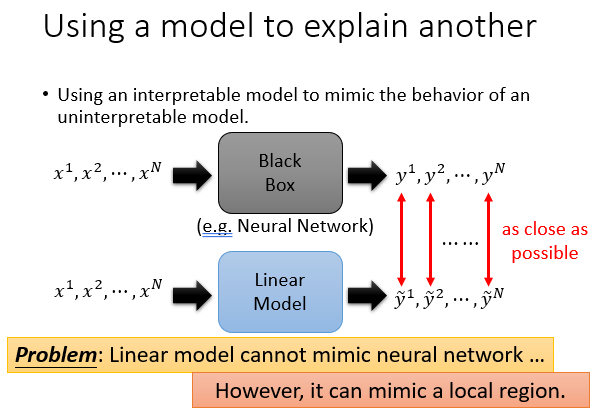
using a model to explain another
这一块主要讲究一个等价替换,复杂的解释不了,我们就找个简单的但是效果一样的去解释。
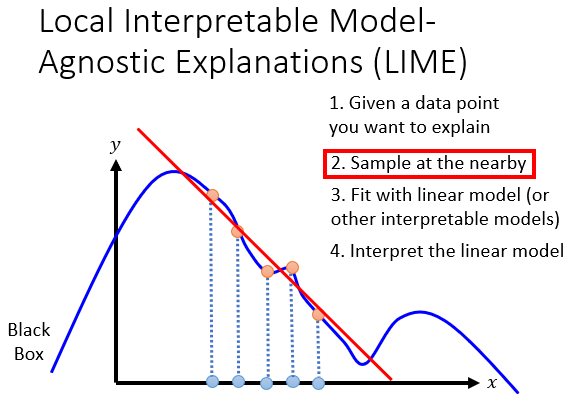
核心思想就是通过在要弄清楚的点附近,随机出一些其他点,然后用线性模型来模仿这个变化,对后续的优化作出指导。
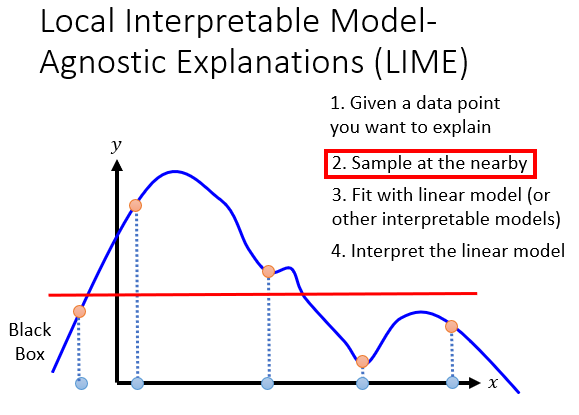
有时候我们随机选择的点可能不恰当,当然这需要很熟练的操作。
LIME算法能让我们在图片识别中作出这个事情。
它将原始图片,分别随机拿掉不同的部分,作为神经网络的输入,然后得到了不同的结果,随机出了不同的“点”。

然后,找一个线性模型来模拟这个结果。
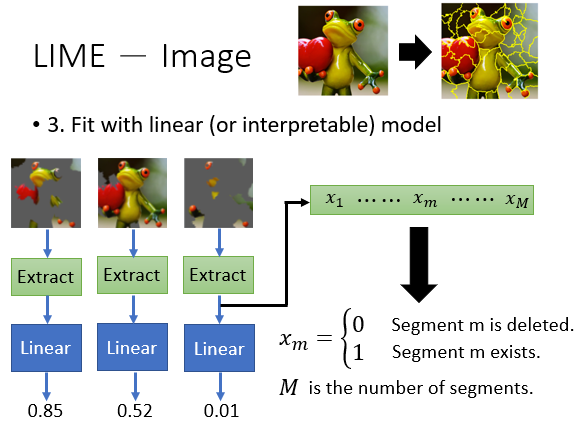
其中m代表块号,我们惊奇的发现,这个model中每一项代表一块,前面的参数不正反映了它对结果的影响吗?真是太神奇了,它确实能解释一些东西!

此外,我们还可以使用决策树来解释复杂的DNN。当然我们不想这个这个决策树太深,太大。
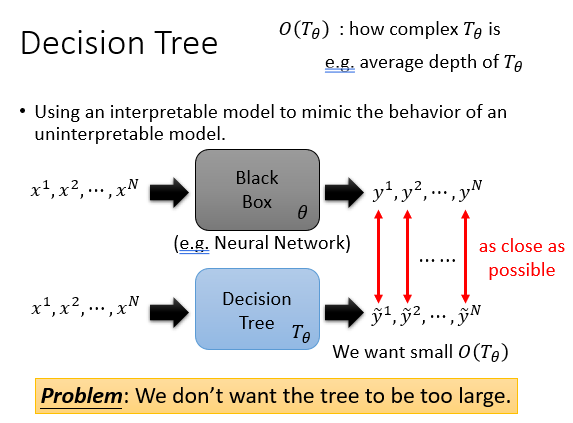
我们可以在神经网络训练时加入一些控制决策树深度的参数项,就是我们在训练前就想用决策树来模拟它。

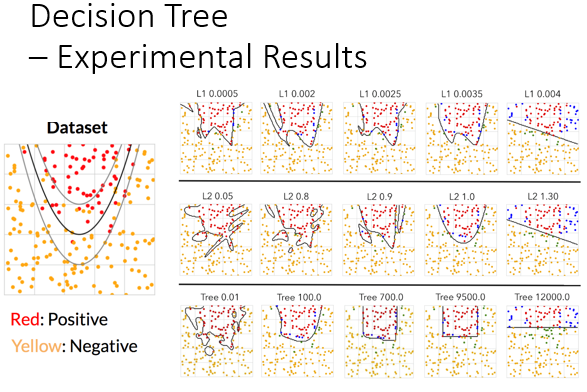
Comments NOTHING