


Semi-supervised Learning
Introduction
Semi-supervised Learning,即半监督学习。
我们在训练中可能不只有带标签的数据,有一些不带标签的数据,如果能利用上这部分数据,可能会对我们的训练起到积极的作用。
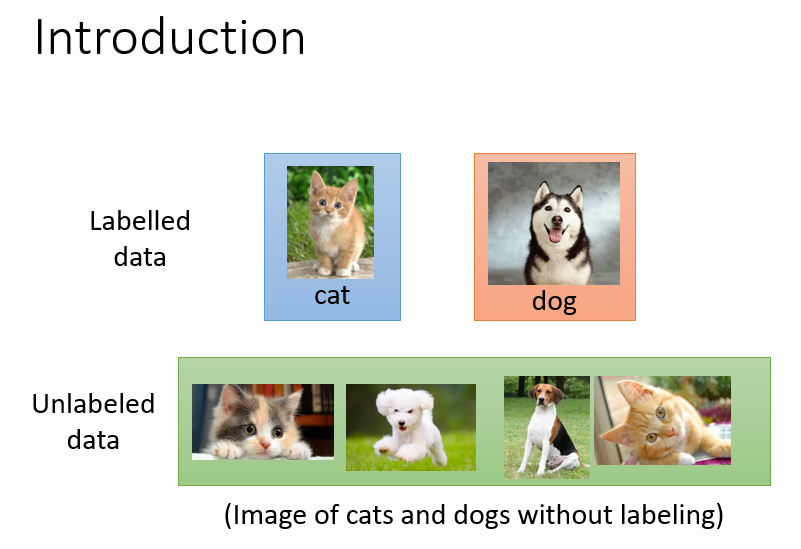

所以我们进行半监督学习,就是除了给一下带标签的数据外,我们提供一些不带标签的数据供机器自己学习,因为这些不带标签的数据总能告诉我们一些东西。

我们按照以下的条理来学习一些semi-supervised Learning的相关知识。

Generative Model
在生成模型下,我们会通过带标签的数据找出一组初始化的参数,然后通过这些无标签的数据去修改它。

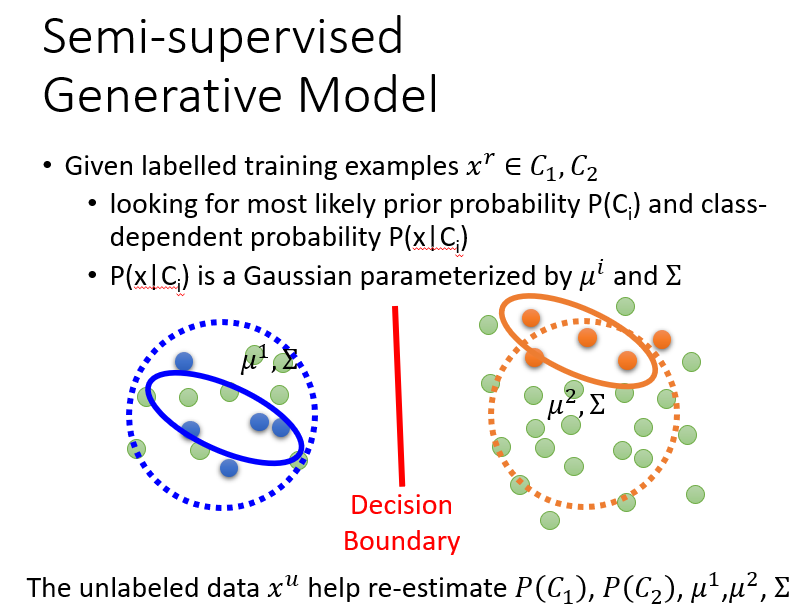
详细的步骤就是确定一组参数,然后用这组参数计算出未标签数据的概率,再用它们去重新计算更新参数。

那么为什么这么做可行?
因为我们的目的都是最大化这个可能性,结合前面说的,我们每次新加入未标签数据进行训练,都会让这个式子的值稍微大一点,一直迭代计算直到收敛。

Low-density Separation Assumption
关于低密度的分类问题,我们坚持'非黑即白'的原则。
和前面一样,先用带标签的数据训练出一个模型,然后用不带标签的数据去优化模型。

但是重点来了,这个为什么“非黑即白”?
因为我们用带标签的数据训练出的模型处理未标签的数据,希望给它"打上标签"参与到优化中,但如果此时使用原始输出数据直接代入模型计算(soft label),不会起作用,因为这些本来就是现有模型得出的结果。所以我们直接哪边概率大就认为它属于谁,直接一边倒(hard label)。
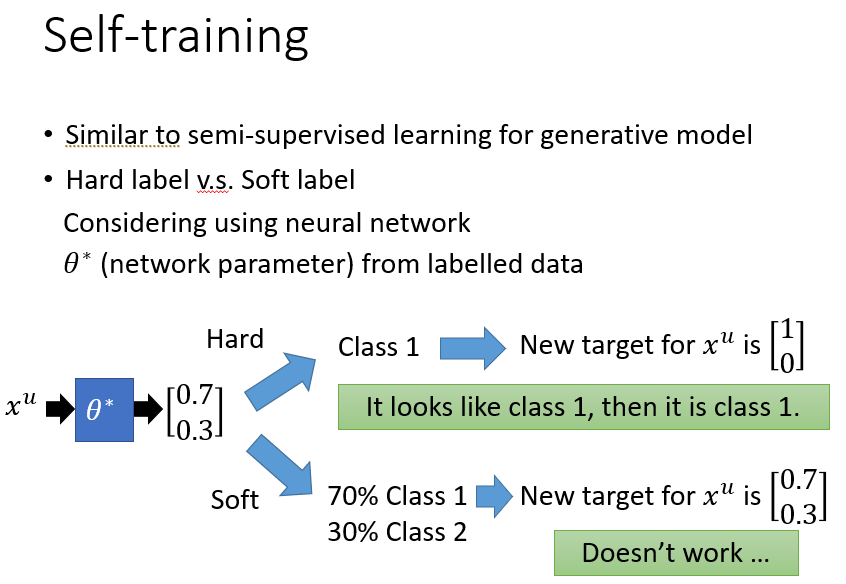
我们在优化中,我们希望给未标签的数据打上标签这个过程能比较大程度的一边倒。不会出现像下述图三那种尴尬的局面。我们可以在损失函数中,加上未标签数据的可能性交叉熵来解决这个问题,只要这个值也足够小,就能实现一边倒。

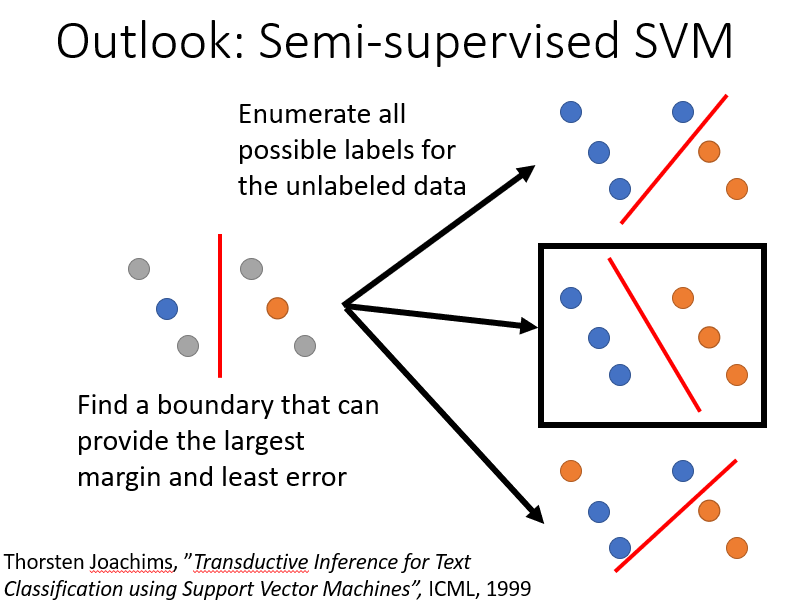
这里还顺带提出半监督的SVM,它不仅考虑到了loss值,同时还考虑到了margin它穷举所有可能的情况,以寻求一个误差最低且分类最明显的状态。
Smoothness Assumption
Smoothness Assumption,即平滑性假设,它讲究一个传递性,“近朱者赤,近墨者黑”。
下图中,可能x2和x3更近一些,但是x1和x2之间被一些密度很高的点连接着,此时我们就可以说x1和x2它们更像,更接近。

就像下面,机器可能会说中间的2和后面的3很像。也识别不了两个侧脸是同一个人。
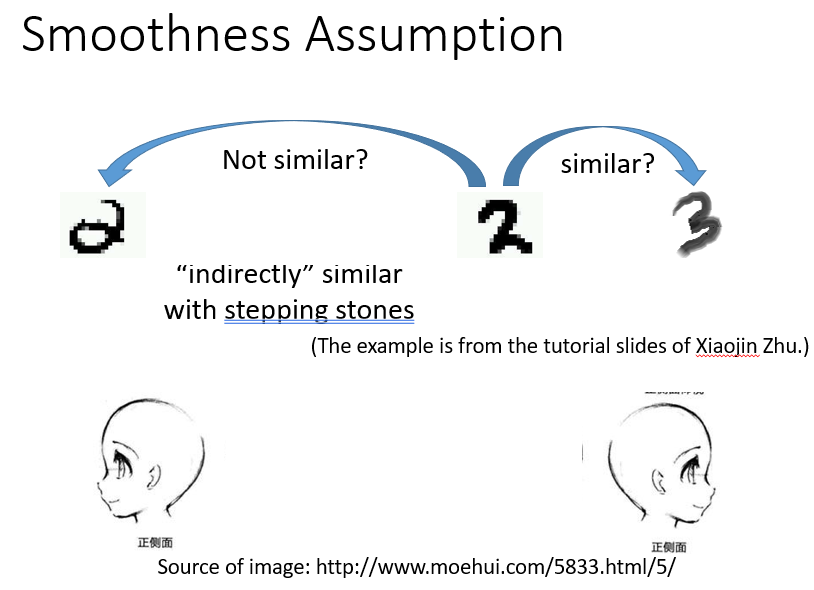
但是当机器得到中间一系列连续变化的数据后,它可能会改变判断,因为这些数据中间有其他稠密的数据支持这种判断。

下面的文章分类也可以用到这种特殊的传递性。


一般情况下,这样做能用所有的数据能训练出一个分类器。

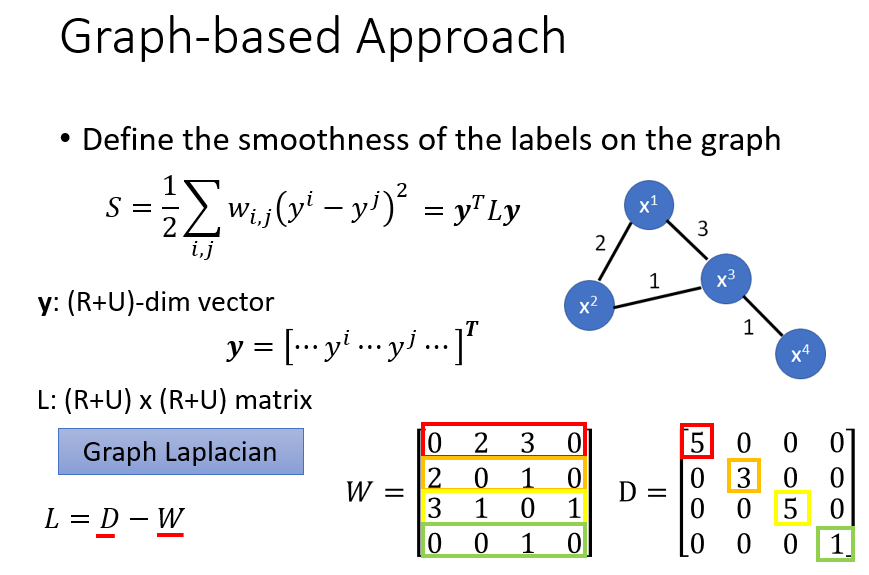
那么怎么认为两个点之间被稠密的点连接着?
引出图基法。
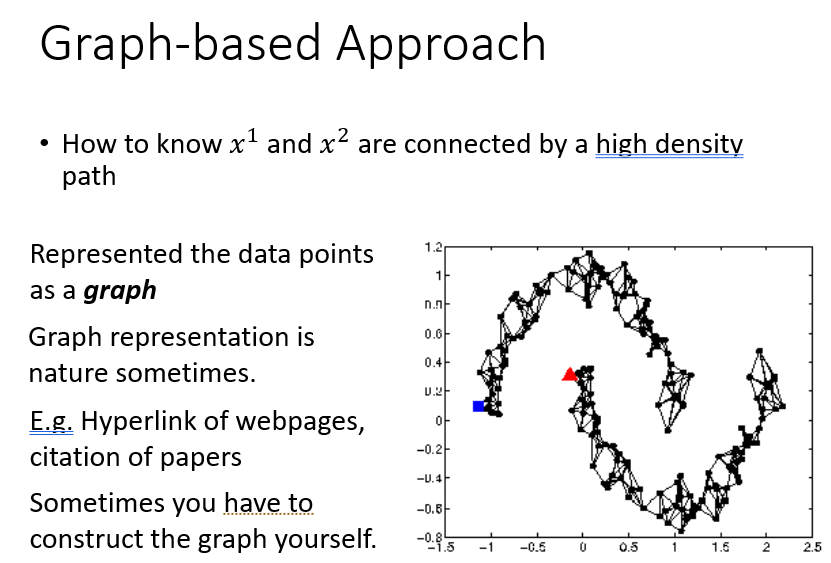
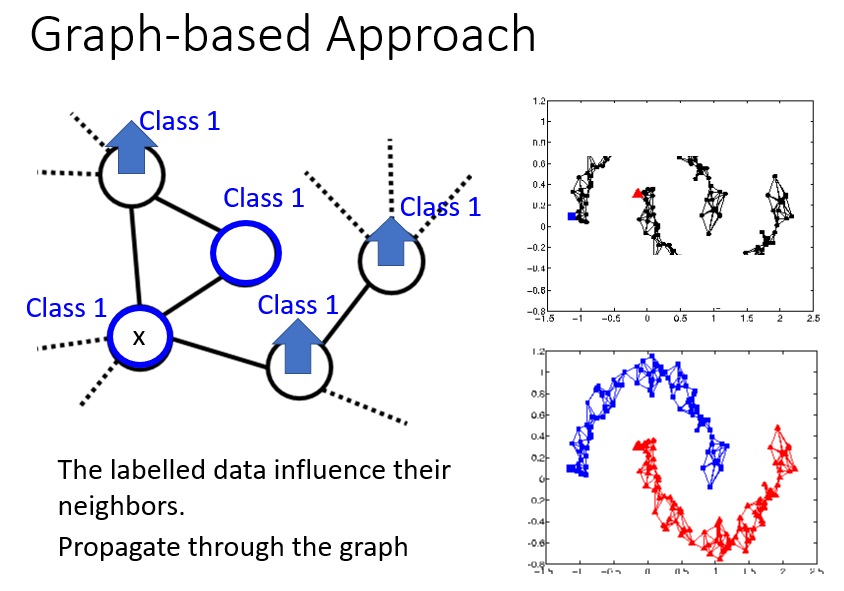
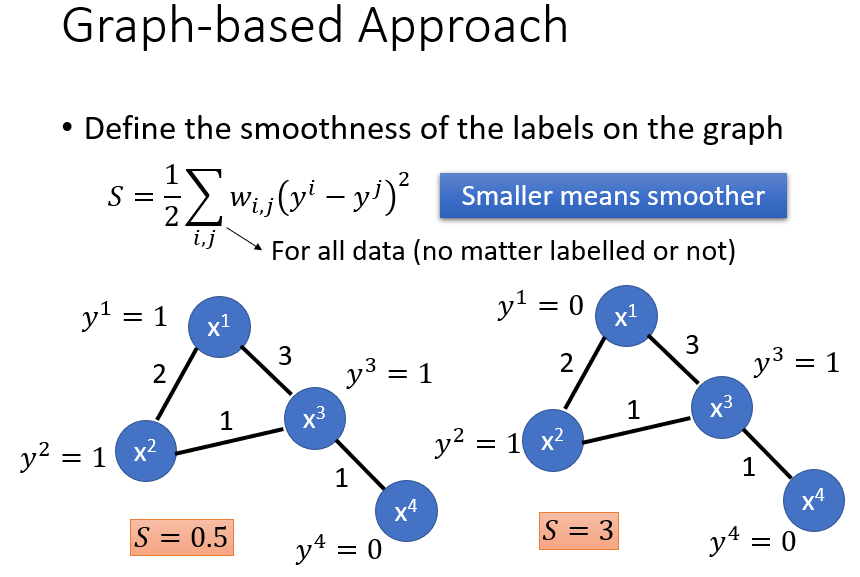
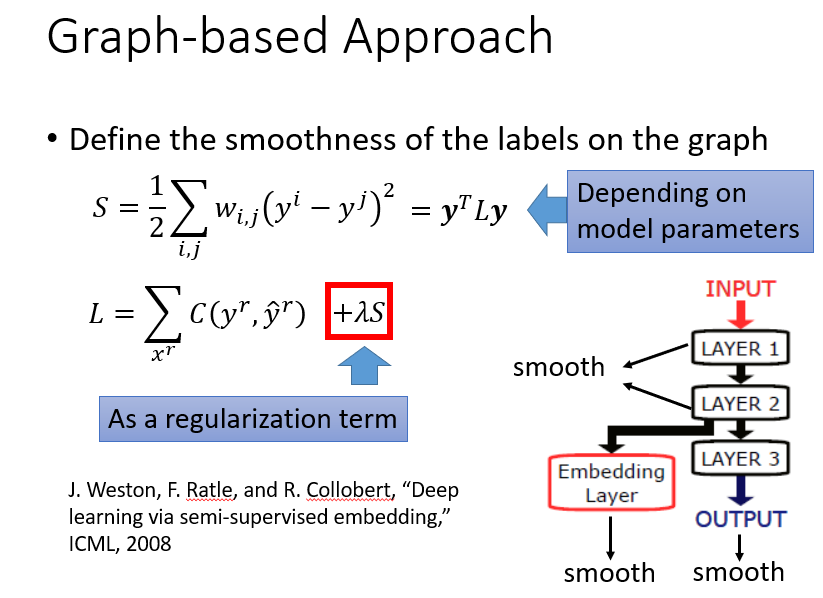
用相似度建图。然后确保比较smooth,如下列图示,说明略。

Better Representation
我们可以从未标签的数据中找到更简单的表示方式,这个我们在后续的无监督学习中再说。
Comments NOTHING