


Structured Learning(中)
Structured Learning回顾
结构化学习就是输出可以是各种东西,来帮助我们得到我们想要的结果。
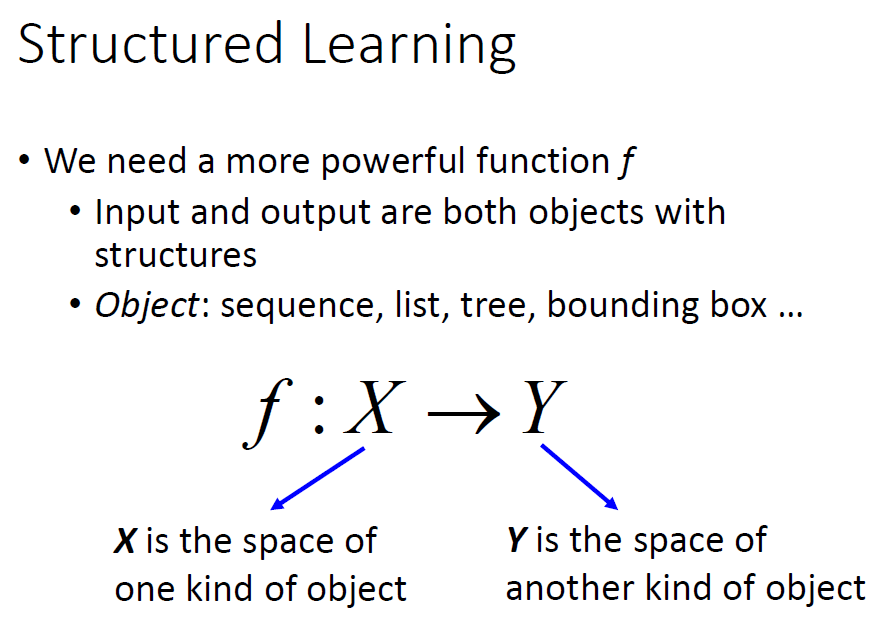
结构化学习一个最典型的应用就是物体的识别。

上一节我们提到过处理Structured Learning,要搞清楚以下三个问题。

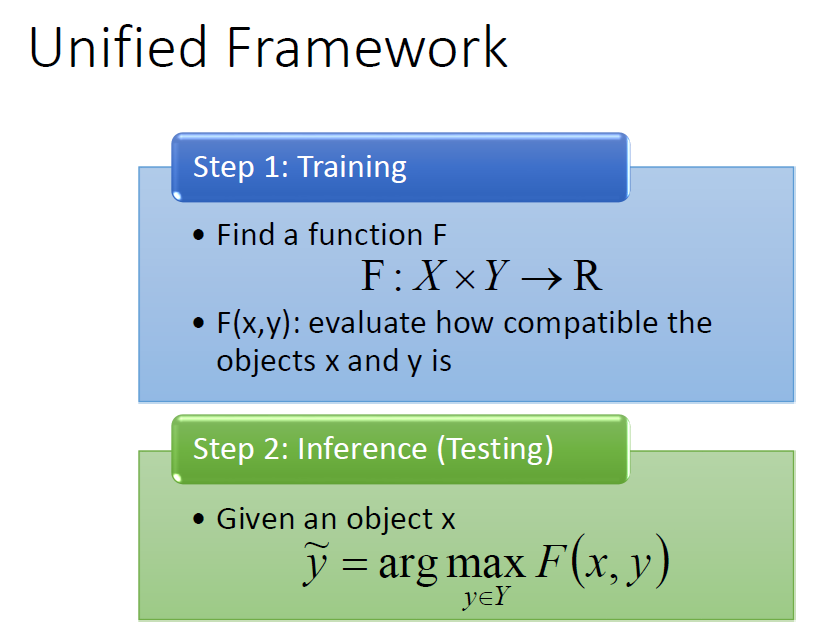
问题1:确定出模型。

问题2:推测出不同状态对应的值,要保证正确状态下的值最大。

问题3:找到或者说训练出这样一个函式使每一个正确位置(我们想得到的结果)代入比其余任意位置代入得到的值都大大,即保证识别的准确性。

本节我们按如下条理来学习结构化学习 SVM.
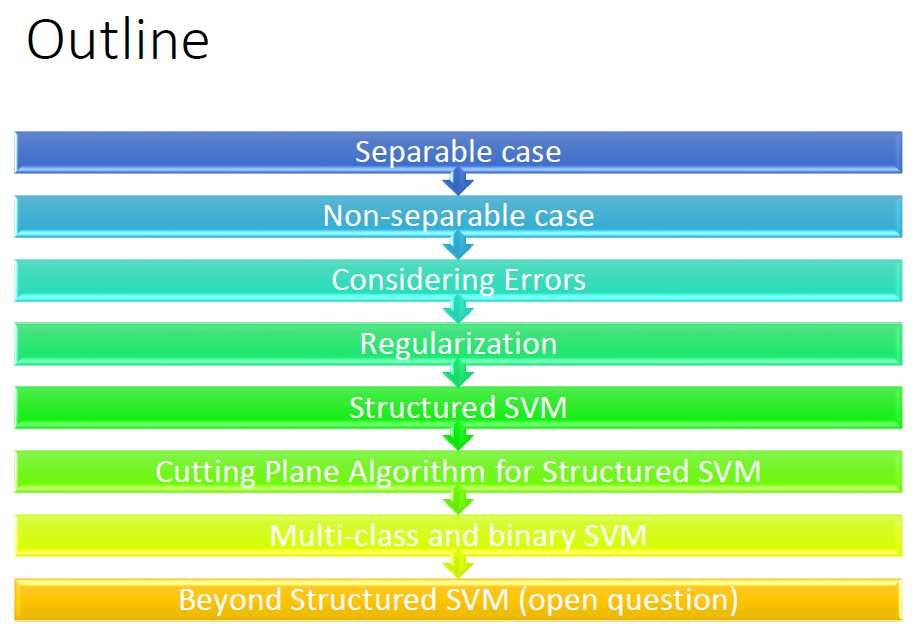
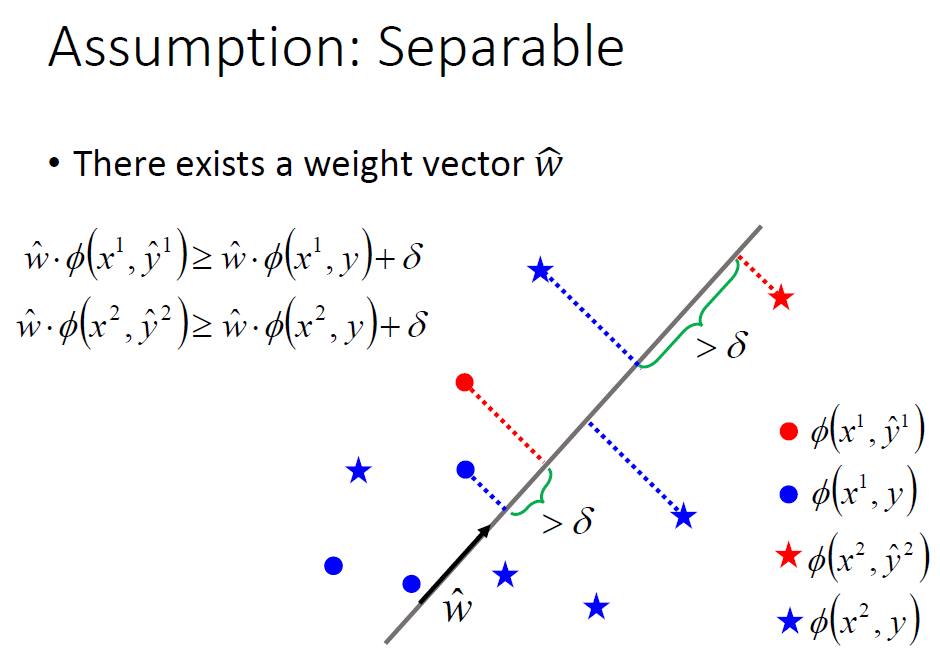
1. Separable case
这种情况就是可分离的情况,通俗了讲在这种情况下,我们可以得到一个函式使正确状态对应的值比其他的都大。
那么我们该如何其中的参数呢?引出Structured Perceptron算法。
对每一组数据如果使函式最大的y值不是真实的y,就改变w的值,改变的方法是后面加上一部分再减去一部分,如下图,加上的部分是真实值,思想就是让w离真实值近一点,减去的是当前错误的最大值,让w远离一点。

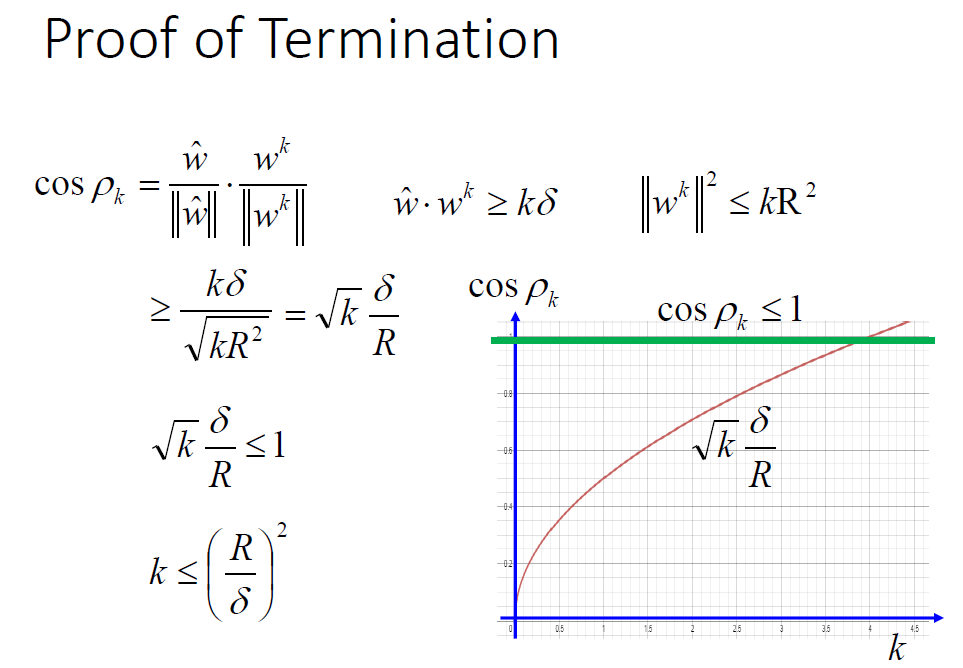
以上算法可行的依据是确定出最理想的w不会超过(R/δ)²次。

这部分的证明如下(简要了解):





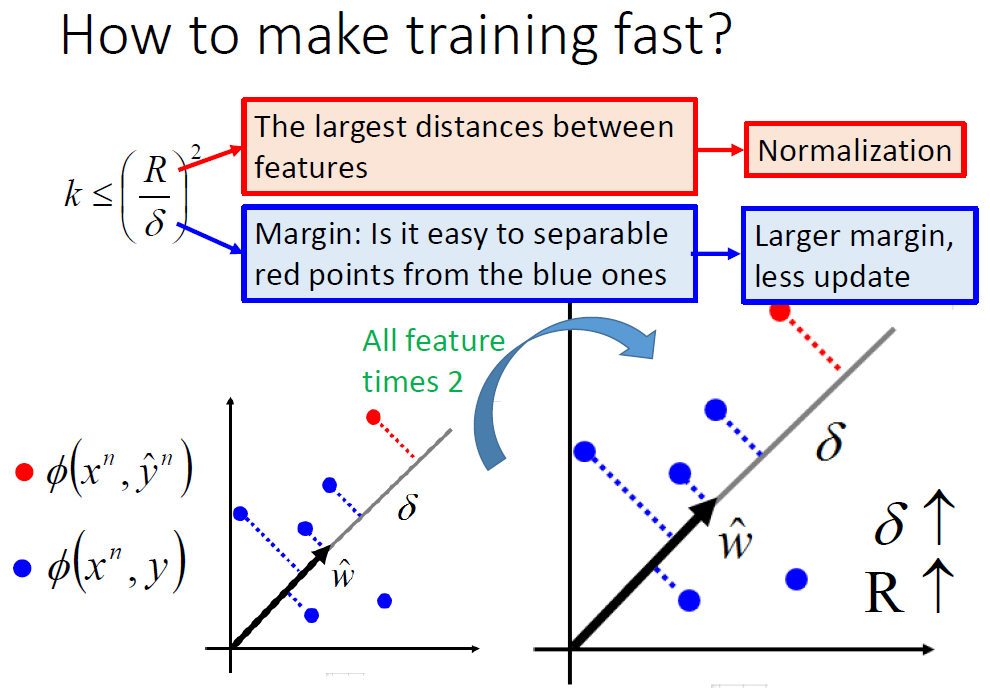
根据上面的结论可以想办法让其训练得更快。
2.Non-separable case
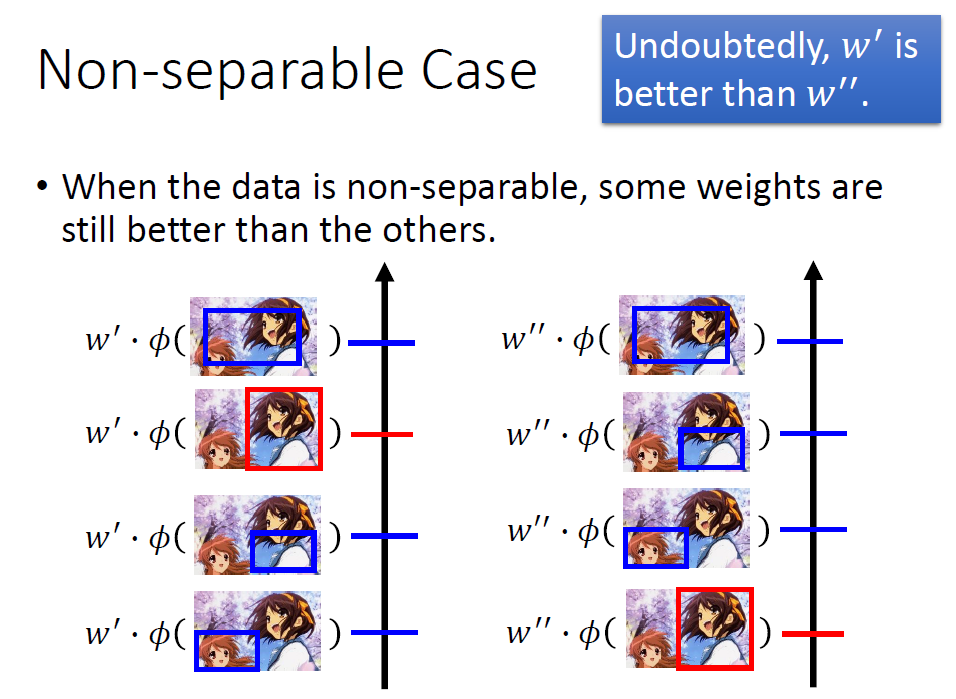
所谓不可分离的情况是:我们想得到的结果代入到函式中不一定取到最大值,反过来说最大值对应的结果是有偏差的。
此时不能使得到理想中的最佳结果对应的值最大,我们就要减小误差尽量得到想要的值。
这时我们要做的是寻找一个w最大化降低这个误差C。

我们采用梯度下降算法。
这里的难点莫过于梯度的计算了。

然而当w不同时,最大值对应的y也不同。我们要把w划分成不同的区域,根据w的情况不同来确定用哪个y来参与计算。
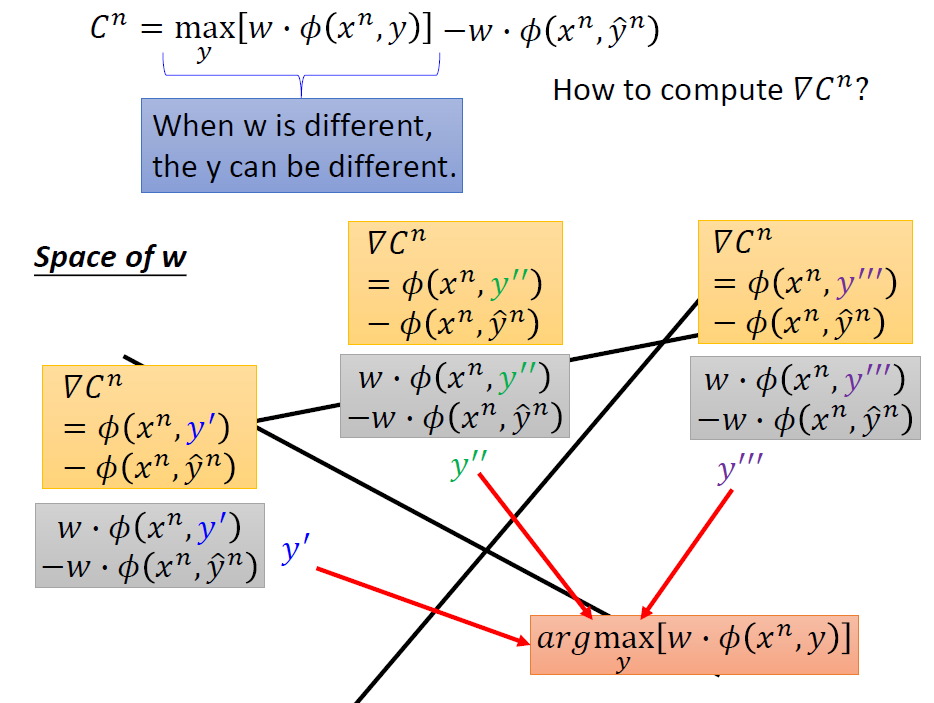
我们计算出对应的梯度之后就能相应的改变w。
我们发现当前面的系数ŋ等于1时,我们其实就是在做structured perceptron.
为什么不直接structured perceptron?
因为structured perceptron每次都要看看是不是理想的值,不是就变,但是这是不可分离的情况不可能最理想的就是最大的,永远不可能等于。

3.Considering Errors
有时候我们想要的可能不需要那么准确,有些结果也在我们接受的范围内,所以我们要考虑到这个问题。
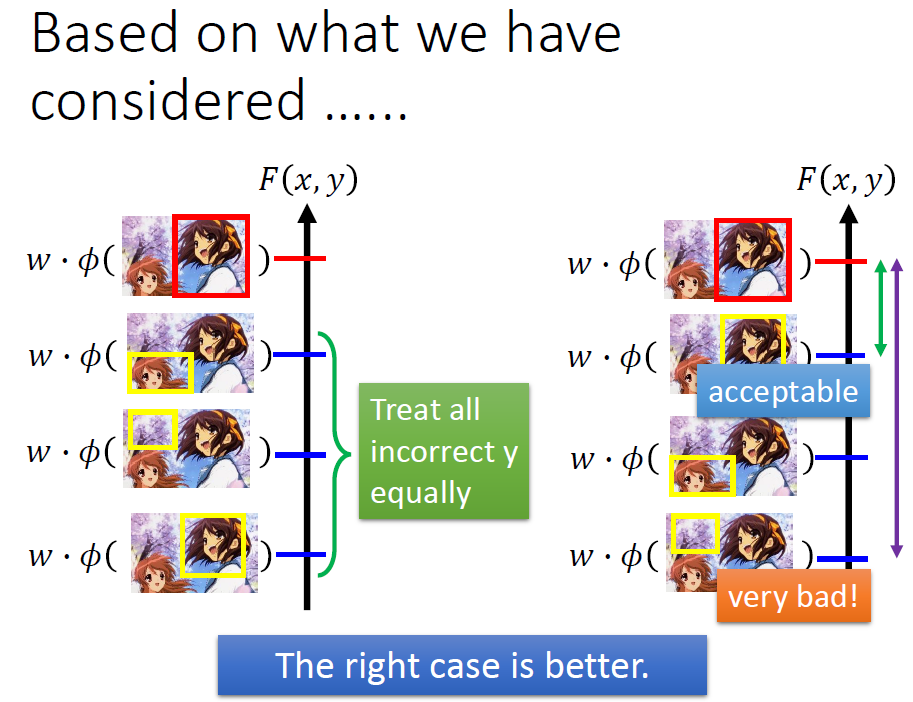
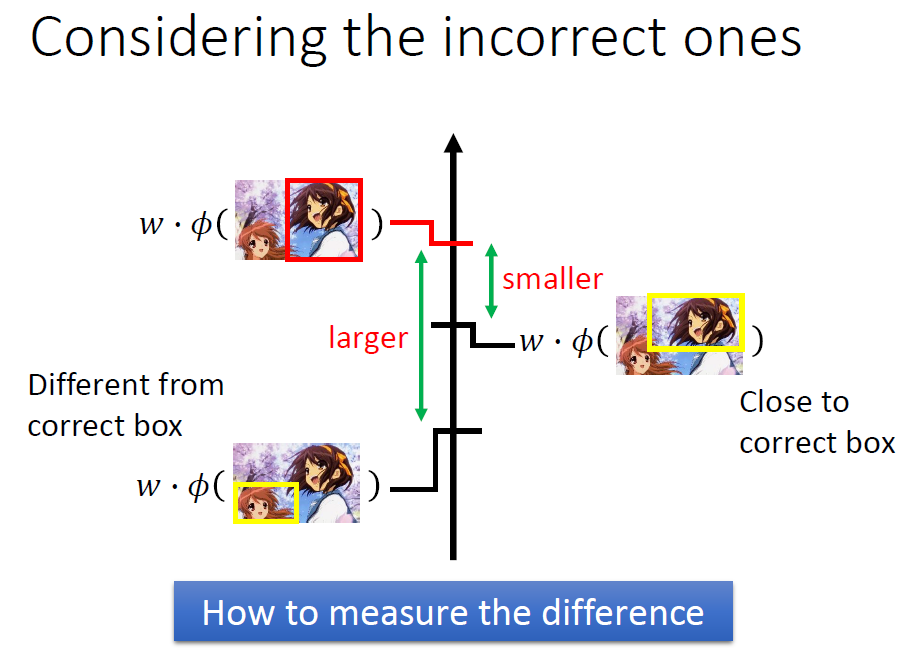
我们定义一个函数来描述一个y与真实的y之间的差距。

这样的话我们可以得到新的损失函数。
大概意思就是我们可以值有一点偏差,只要这个距离小就能勉强接受。
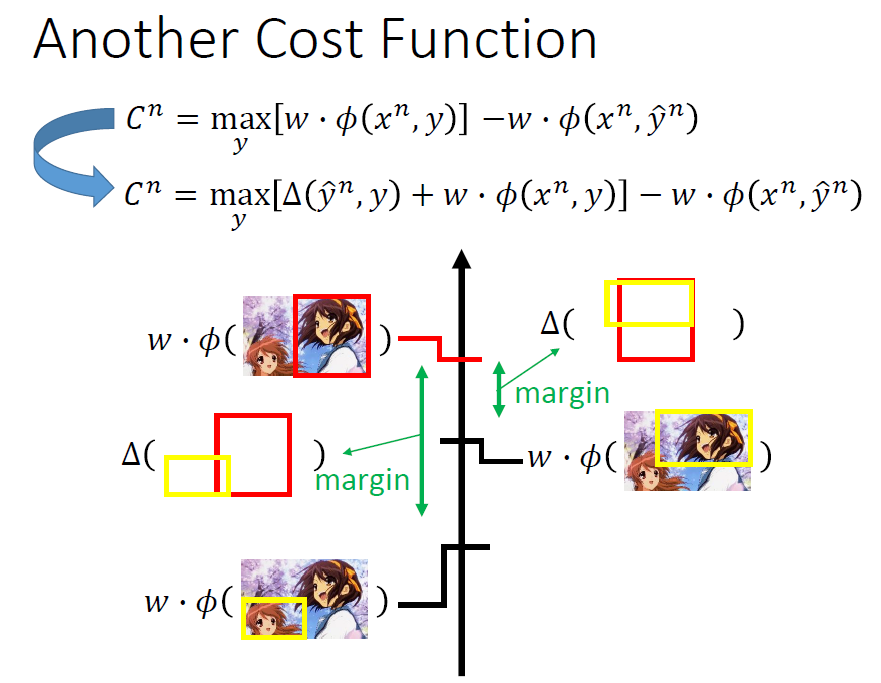
计算的话还是实验梯度下降算法,较之前的只是多加了一部分。

这一部分我们要使C'尽可能得小,我们不容易直接处理,但是可以借助不等式,我们去限制它的上界C,让它的上界足够小。这样就达到等效的结果。

证明如下(了解):

这里损失函数可以有很多种,如下图所示(先了解):

4.Regularization
相对于前面的知识,这里就相对简单了。回顾前面的知识,就是加上带参项使函式更平滑,降低参数的影响。

最终会得到w迭代式中会出现类似DNN中的权值衰减的效果。

5.Structured SVM
前面说了这么多,那么何为SVM?
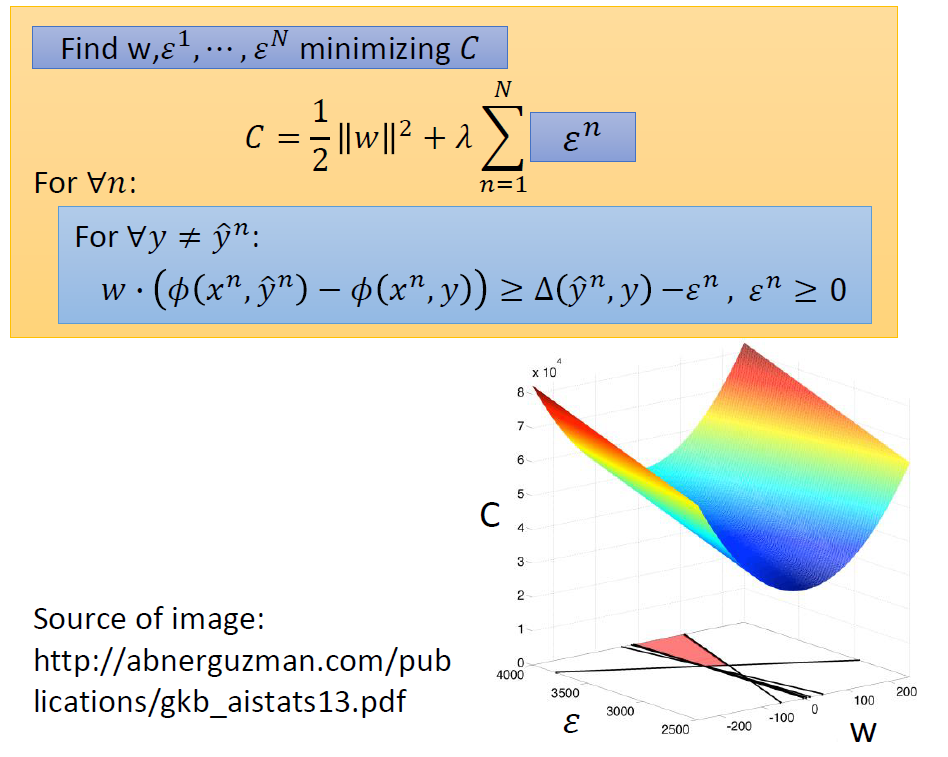
我们要最小化左边的这个C.
又由于右边的Cn展开后表达式中含有最大值,所以我们可以换一种表达方式移项整理,使其变成一个约束条件:
对任意的y...

为了防止混淆,我们把右边的C换成ε,这个ε被称为松弛度,下面再说。
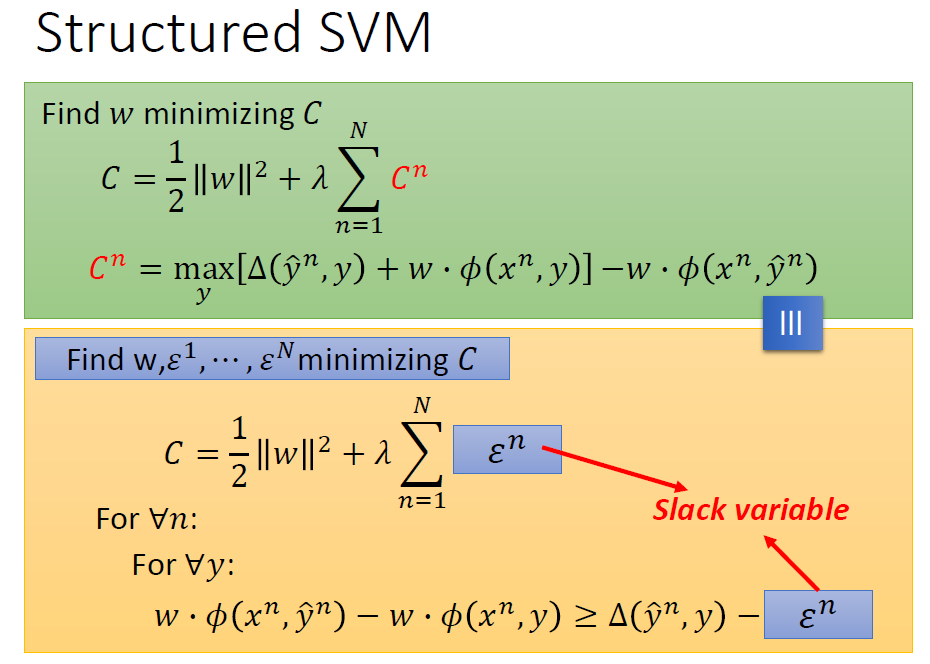
然后我们得到了什么,得到了在下面那个约束条件下求上面这个式子的最小值。

那么上面的松弛度该怎么理解,为什么会引出这个概念?
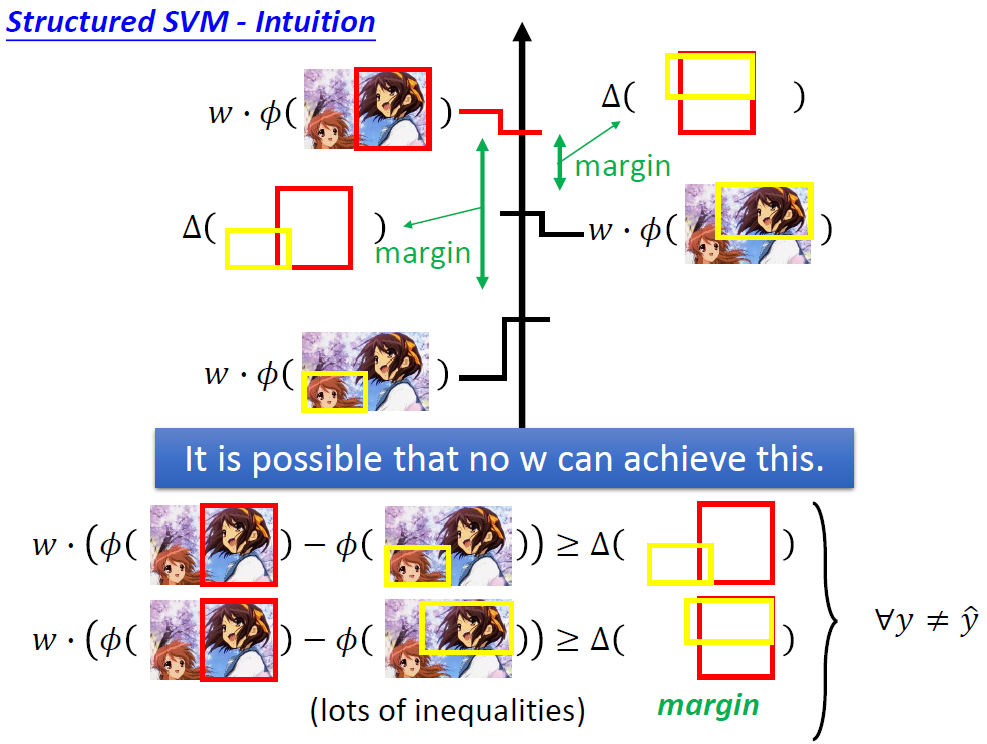
用下述实例来解释,我们看这个不等式,如果没有后面松弛度这一项,不一定能是所有的y代入都能大于等于右边的这个差距。所以后边的这一项相当于放宽界限,让参数的训练变得稍微简单一些,所以叫做松弛度!
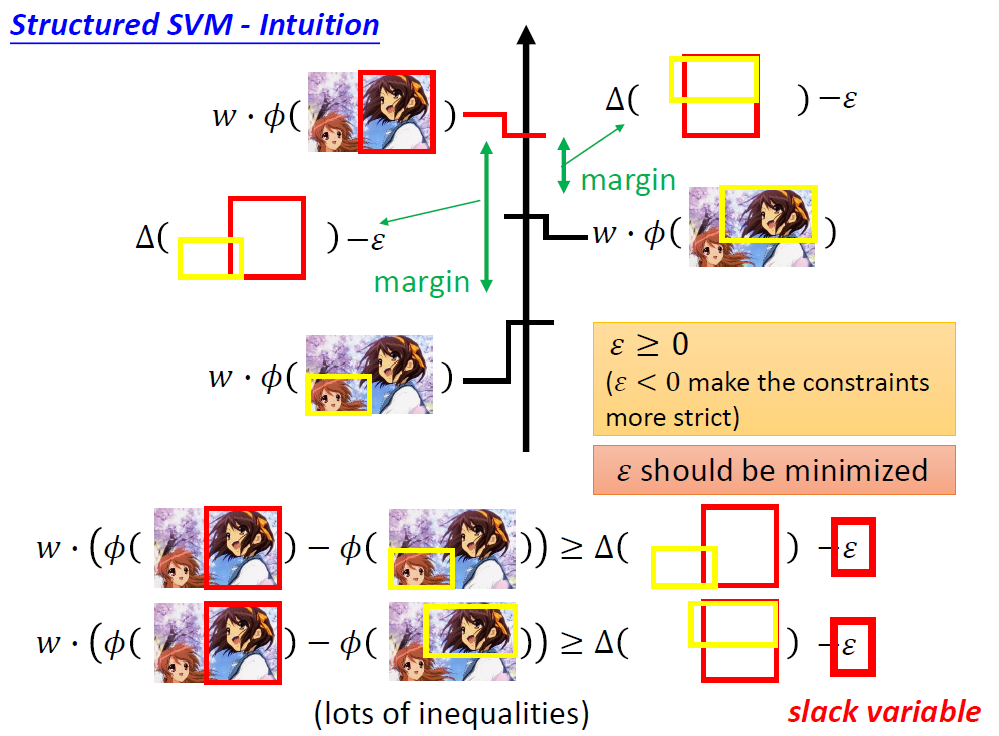
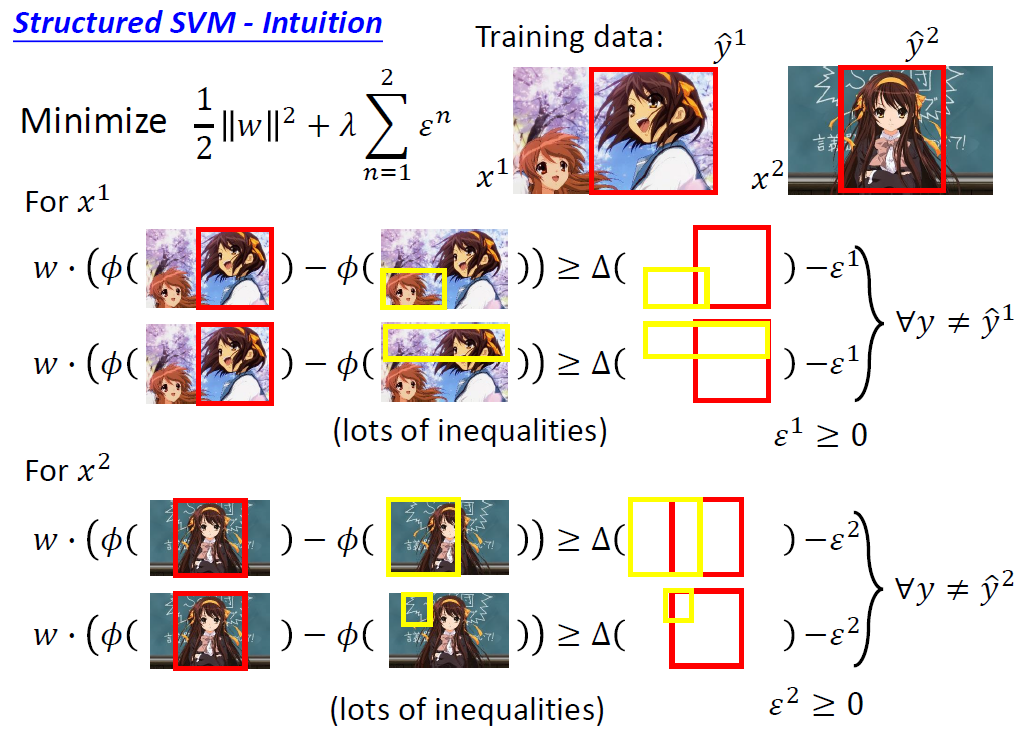
经过这样的处理后,整个结构化学习就变成了一个可解问题。就是在下面的约束条件下寻找上面式子的最小值。

6.Cutting Plane Algorithm for Structured SVM
训练时,在指定约束下寻找最小值就是下面这个情况。
约束会形成一个区域,在这个区域中寻找最小的C即可。
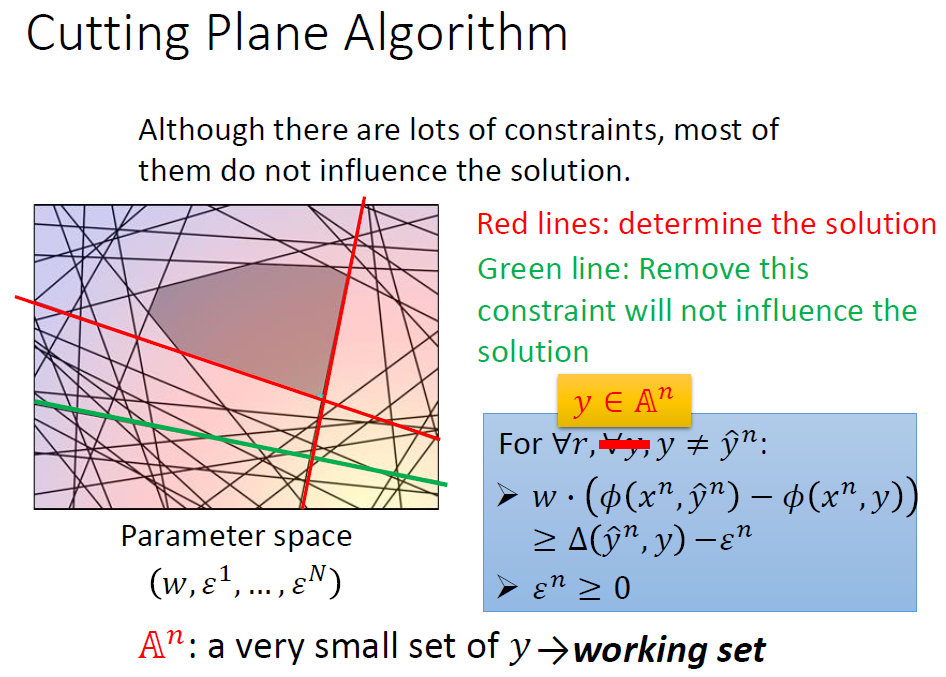
那么关键问题就在如何确定约束区域上了,这里我们采用Cutting Plane Algorithm(割平面算法)。
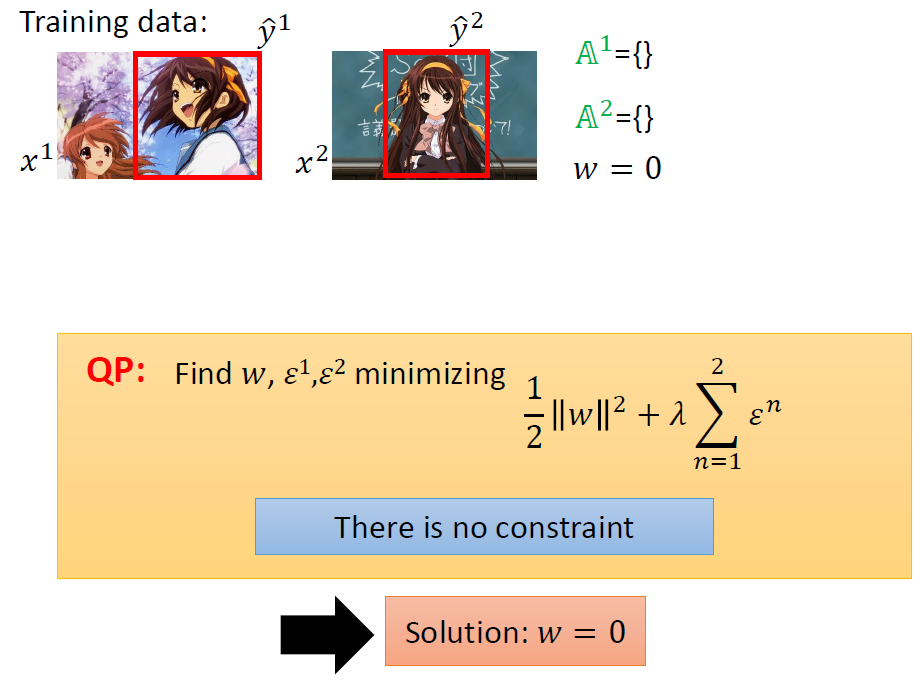
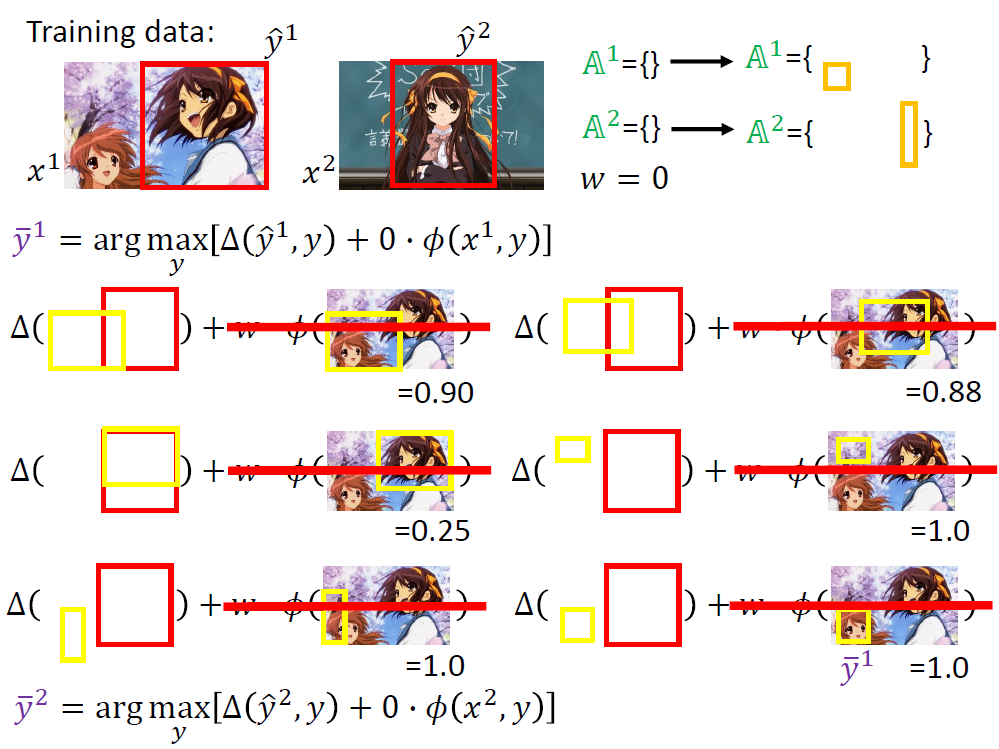
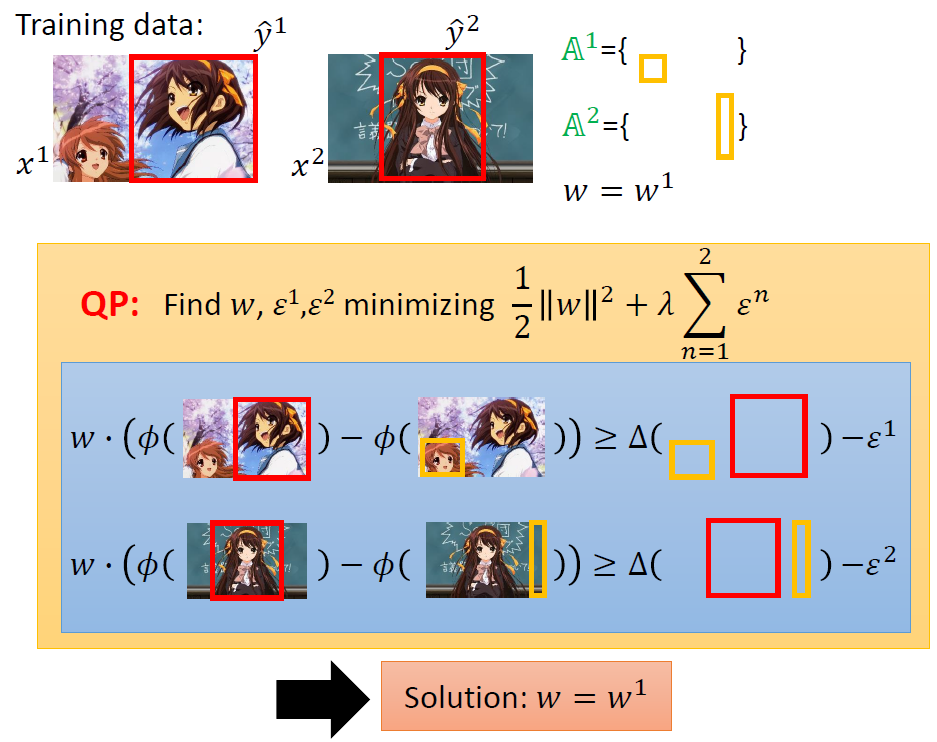
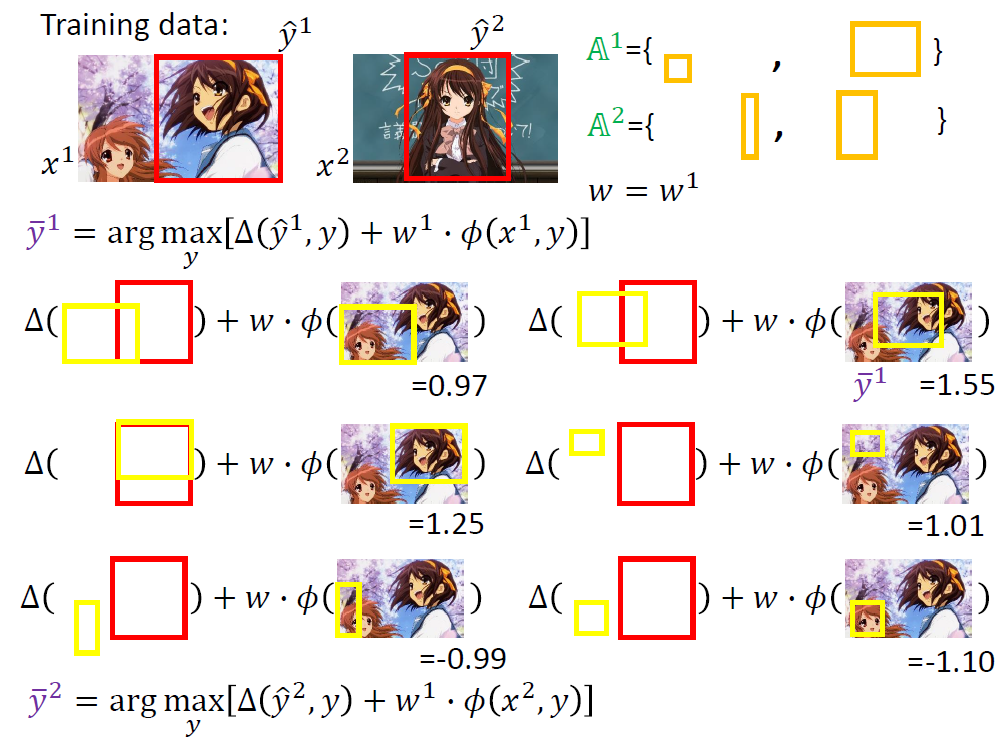
我们通过观察得知,约束有很多条,但是能起到作用的远没有那么多。我们需要向下述过程般的确定约束区域。



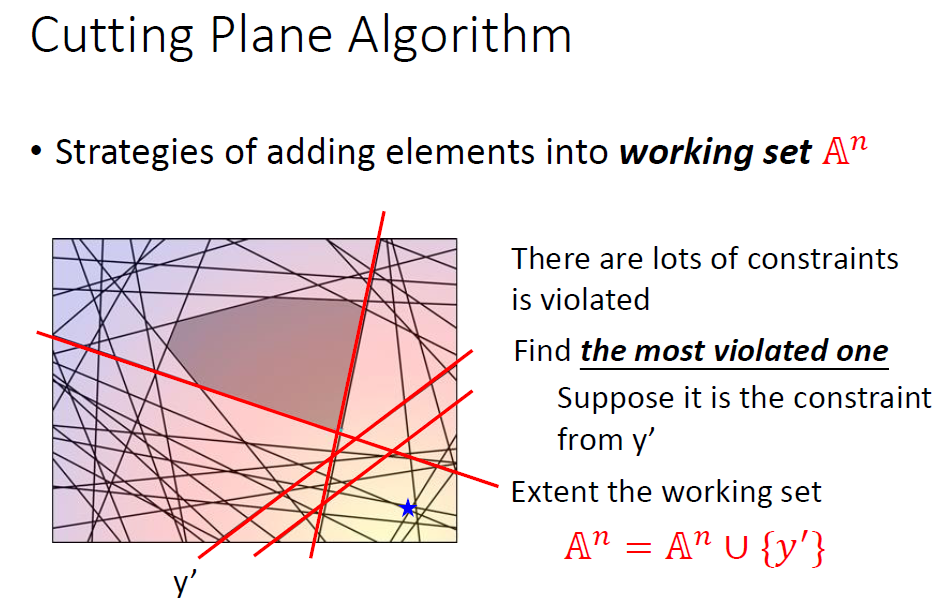
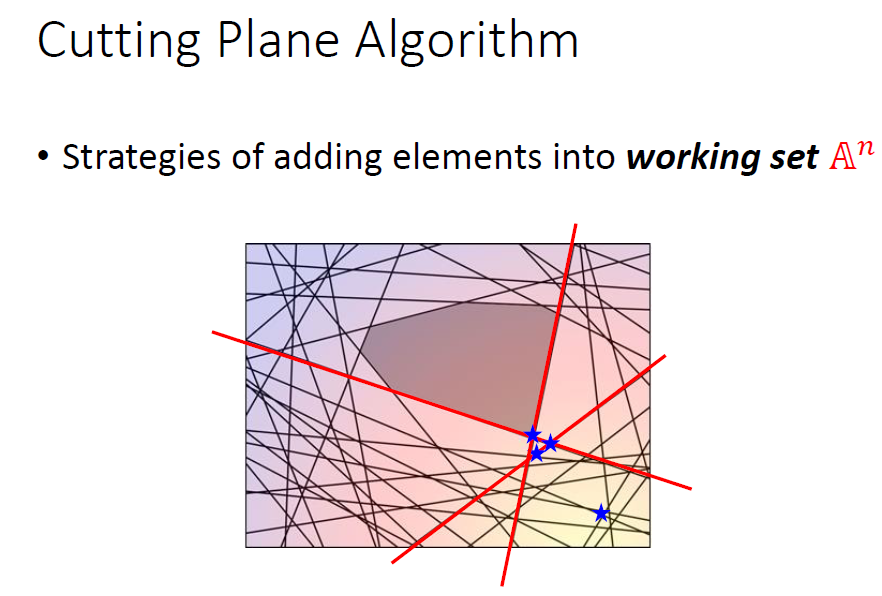
每次关键就是找出最违反约束的y加入到A中。
实际操作的原理还是找[△(y,y) + w·Ф(x, y)]最大的y。


然后不断加入,直到每一组数据的A集合都不在变化,最终的A集合即为我们寻找的有效约束区域。

下面的实例可能更加清楚得描述上述演算法。
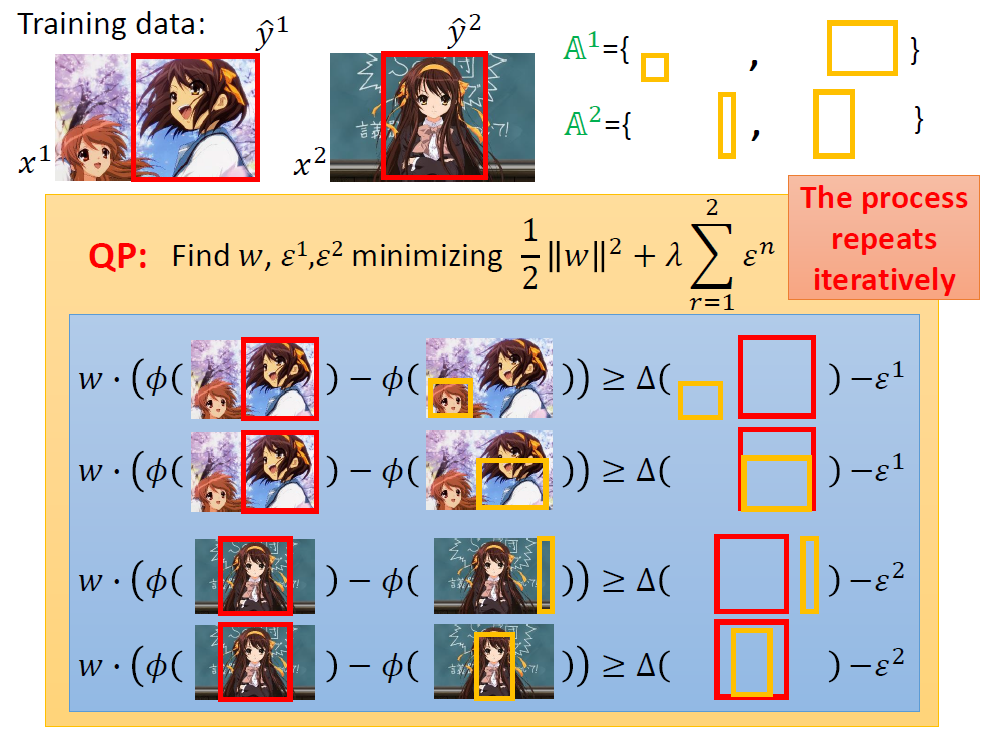
7.Multi-class and binary SVM
多类和二元SVM,其实都是说的是对应的y的数量。
对应多类SVM来说,我们就需要训练k个w.我们改用vector来处理就好,训练不同的w时,x在不同位置。


在这个过程中我们可以自定义这个差距来控制达到我们想要的结果。

对于二元的来说y只有两个。

8.Beyond Structured SVM(open question)
对于结构化的SVM来说它经常会在前面结合DNN来使用,来获得更好的效果。
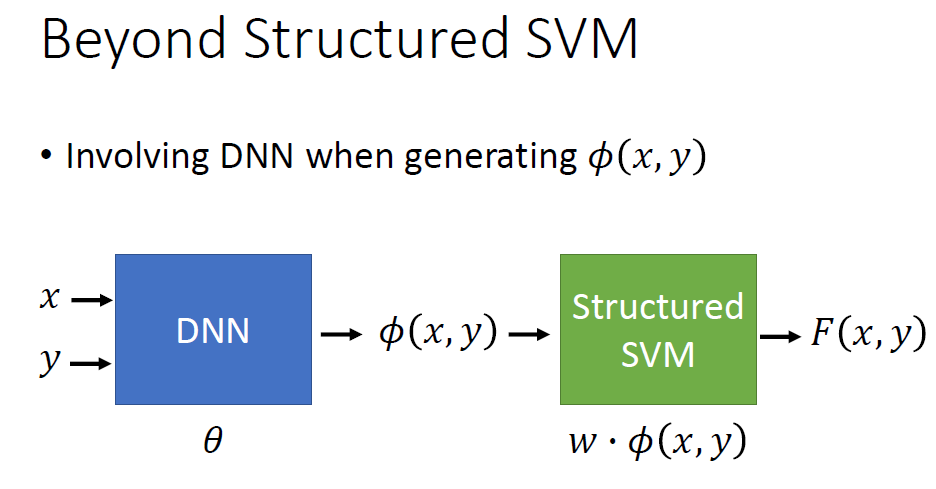
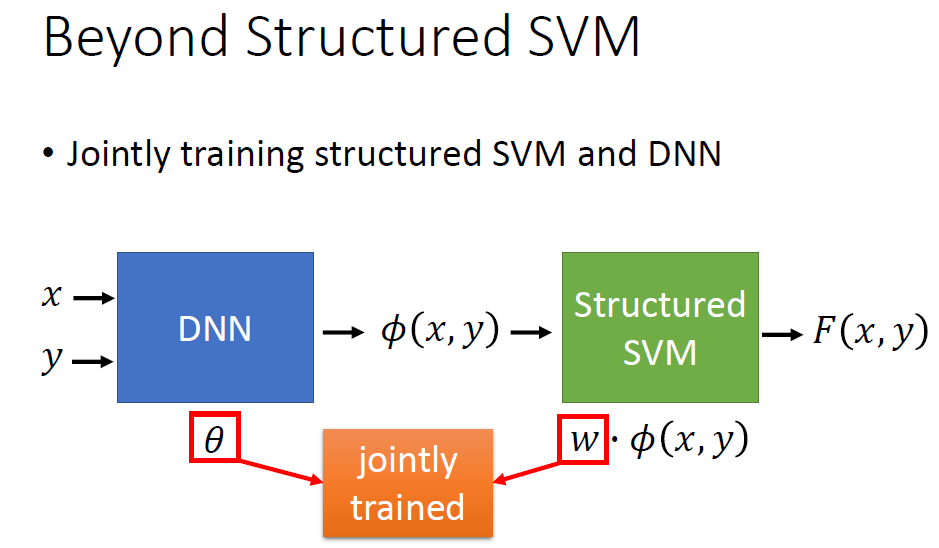
也可以同时训练DNN与SVM的参数。
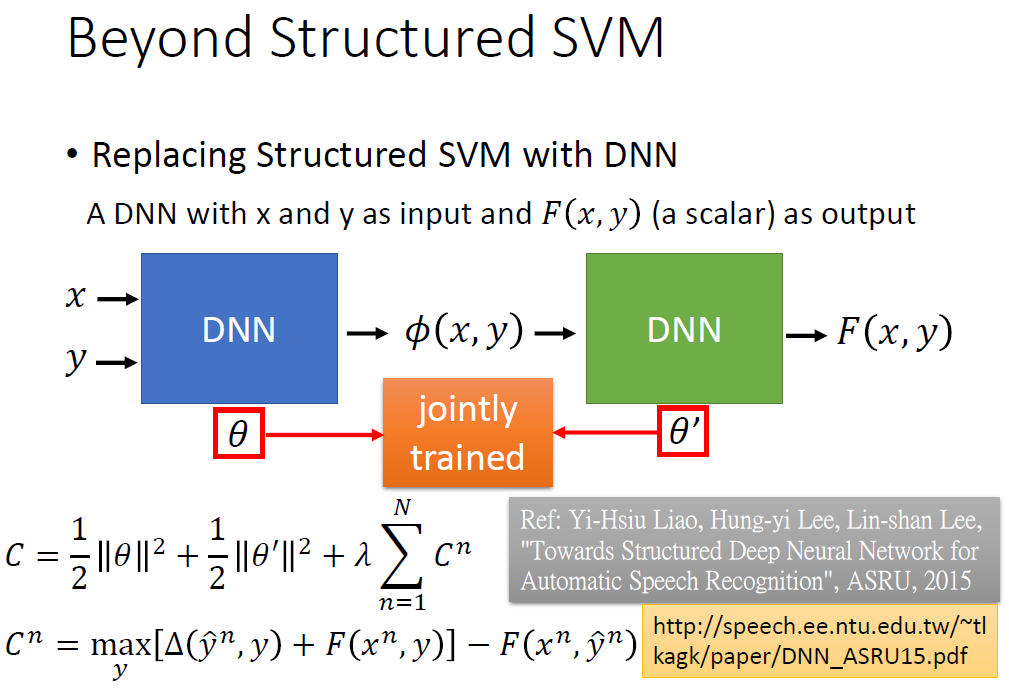
当然也可以用纯DNN来处理一个问题。
Comments NOTHING