


Regression - Case Study
1.What's Regression?

2.A Example Application
已知宝可梦进化前的数值,进行一个Regression来预测它进化后的数值.
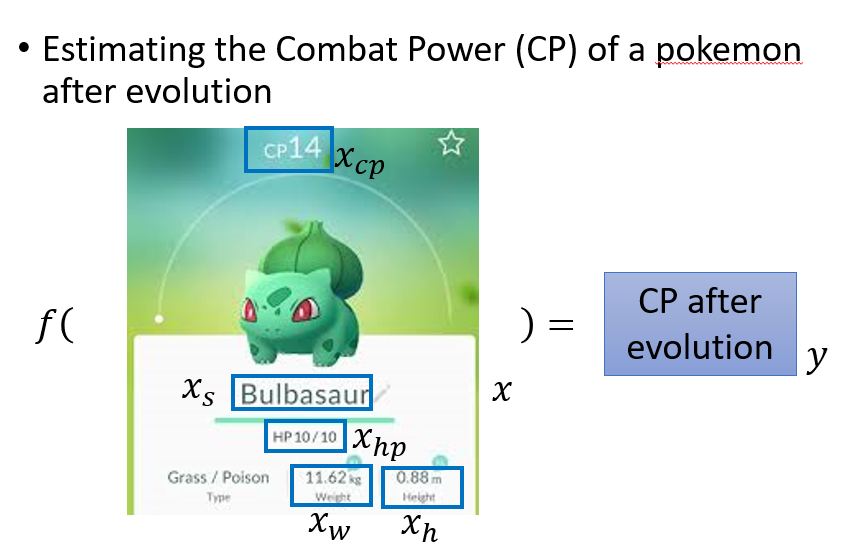
Step 1:Find a Model
选取 a set of function,f1,f2...fn,即一系列函式,构成一个Linear Model

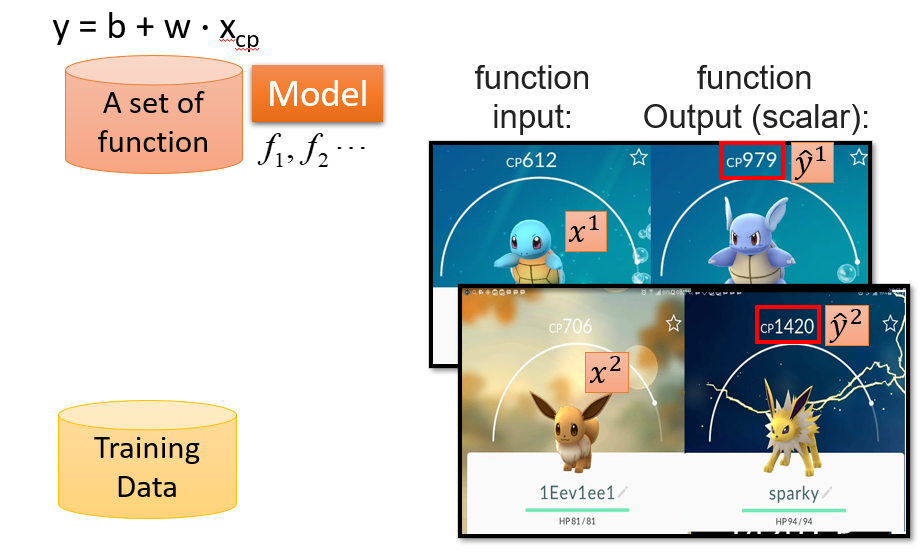
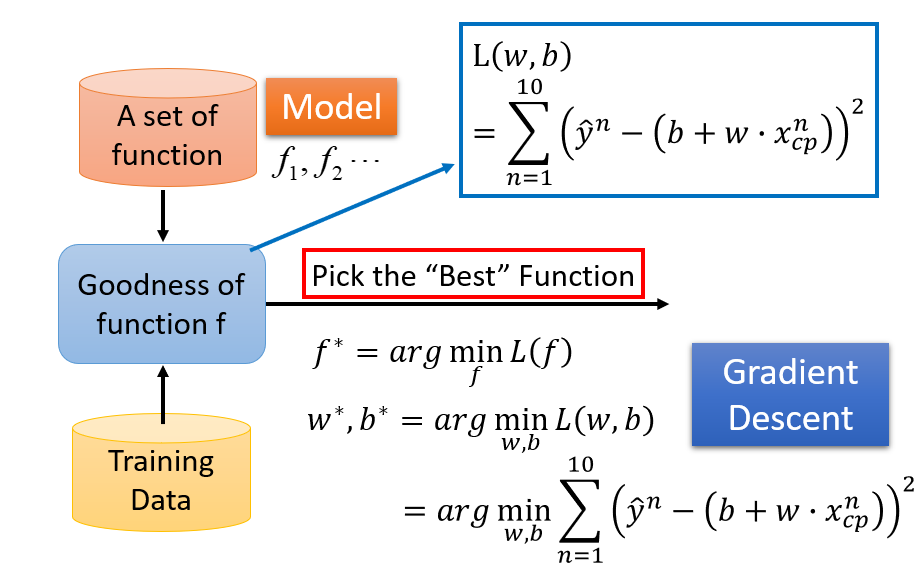
Step 2:Goodness of Function
用 Training Data去评判Model中函式的好坏
每一个Training Data都有一个真实的Yn
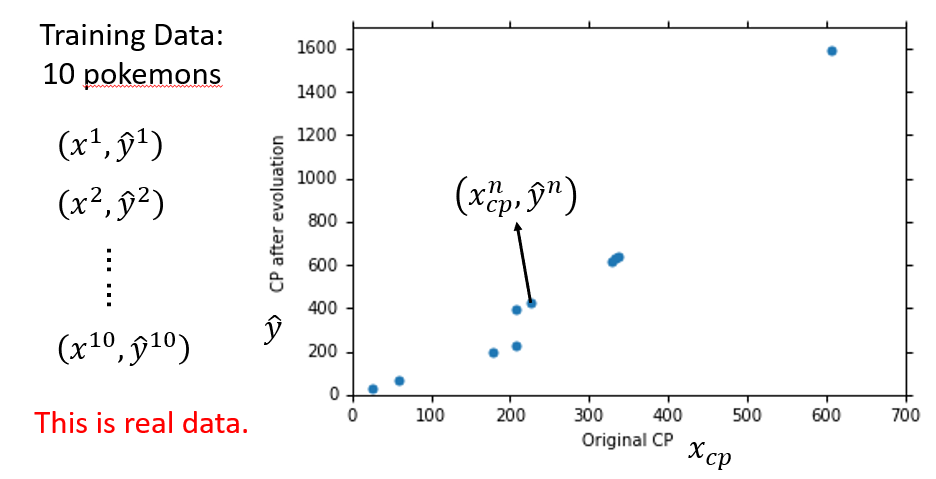
定义Loss function L,来验证函式f1,f2...的好坏,L即为function的function
input: a function
output:how bad it is

得出原model中当取不同函式时(即w,b的值不同时),Loss function的值,并画出图像,颜色越深代表Loss越小,效果越好
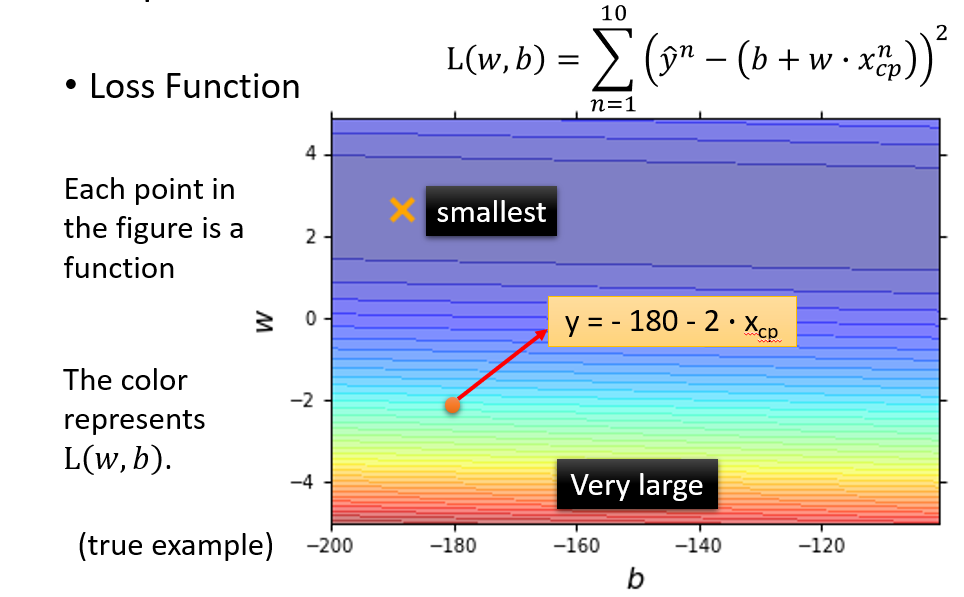
选出Loss最小的函式,即最好的f
Step 3:Gradient Descent
通过Gradient Descent可以让我们求出Loss的最小值以及对应的参数的值
我们先假设如果Loss Function只具有一个参数:
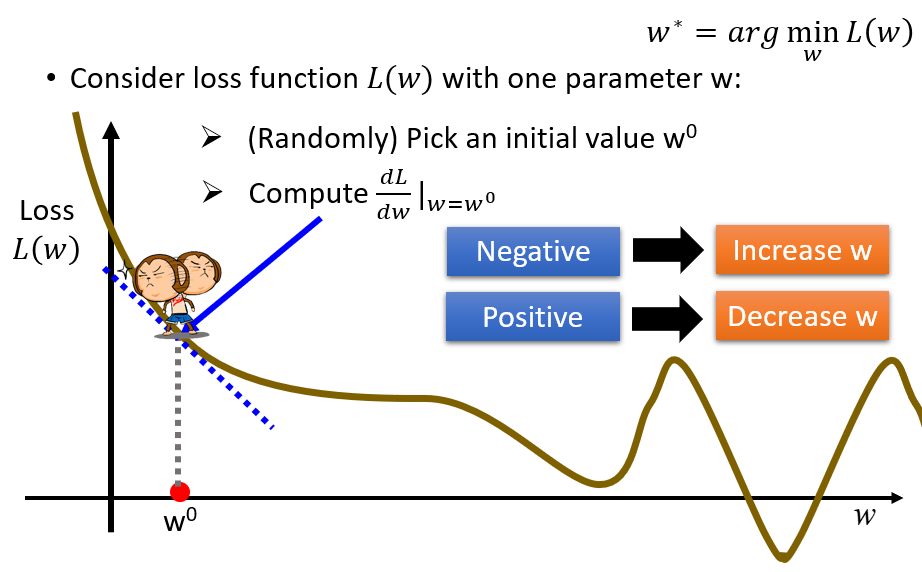
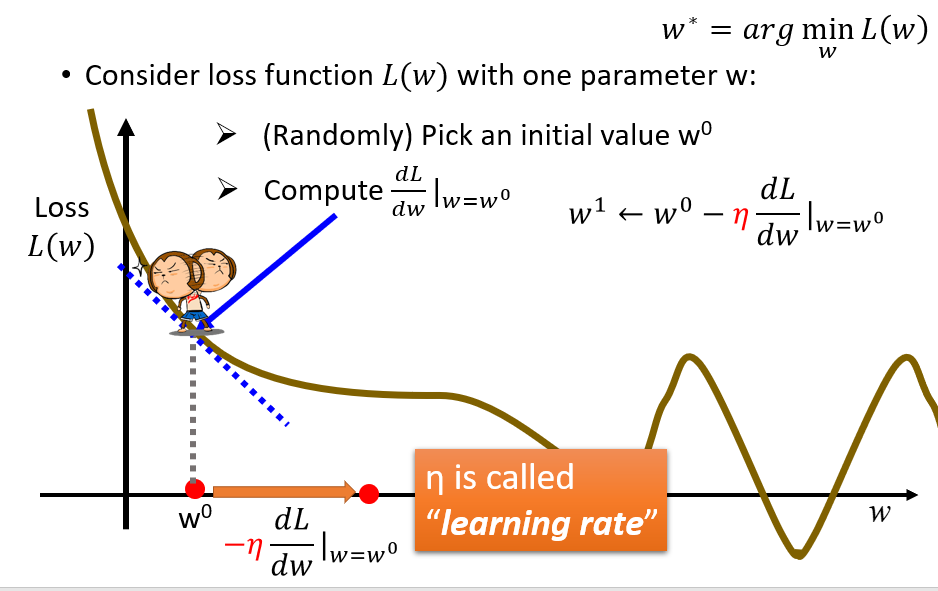
我们肯定是需要求他的一个微分,为了让Loss减小,如果在某一点处(会找一个初始点)的导数大于0,肯定要让w减小往左走;反之导数小于0,肯定要让w向右走.
移动多少与微分值和它前面的系数有关.
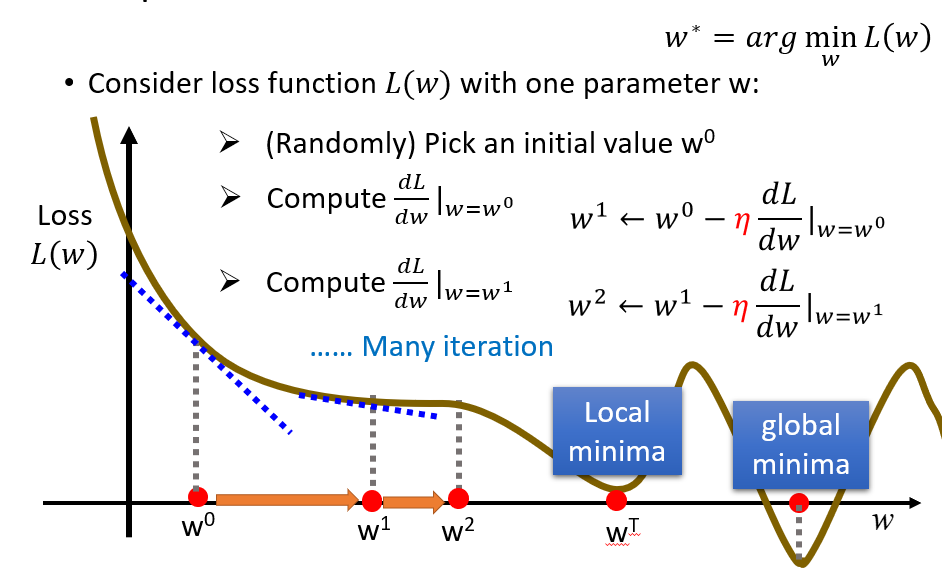
于是,经过数步可以求到一个Local minima(局部最优,即函数的极小值),当然也有可能你运气好,刚好求得的就是global minima(全局最优,即函数的最小值)
有了以上知识的铺垫,我们来想一下今天的这个问题,它具有两个参数
当然通过求偏导数来解决问题.

补:偏导数的求法

经过数次移动后,我们可以到达一个Loss最小的地方,并得知此时参数w,b的值
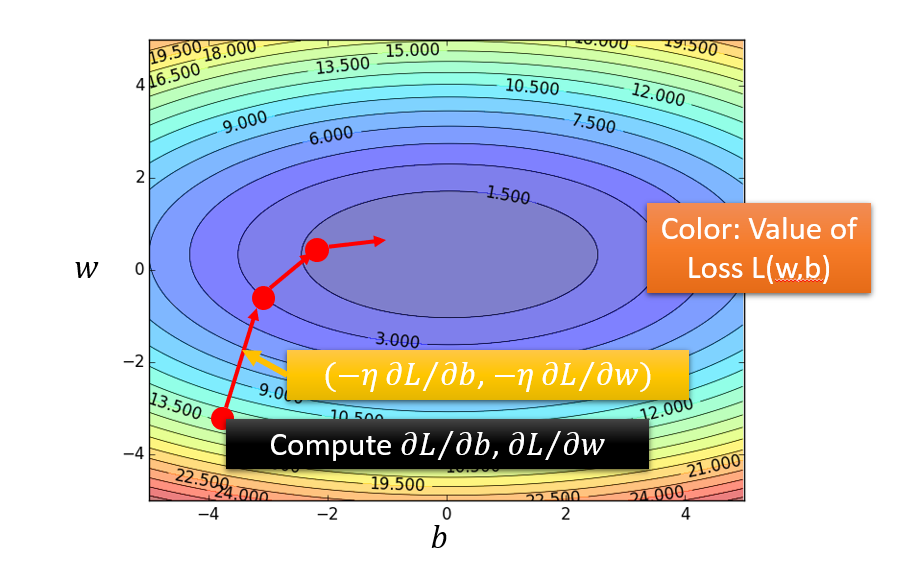
思考:这个会不会有什么运气不好求得的参数值不是全局最优的问题么?
显然是不会的。
因为它是一个凸面的函数,弯下去就不会再弯上来,区域内极小值即最小值。
联系用偏导求出来的多元函数极值即为最值.(高等数学中有提到)
我们通过上述计算得到参数的值了,那么这个function效果怎么样呢
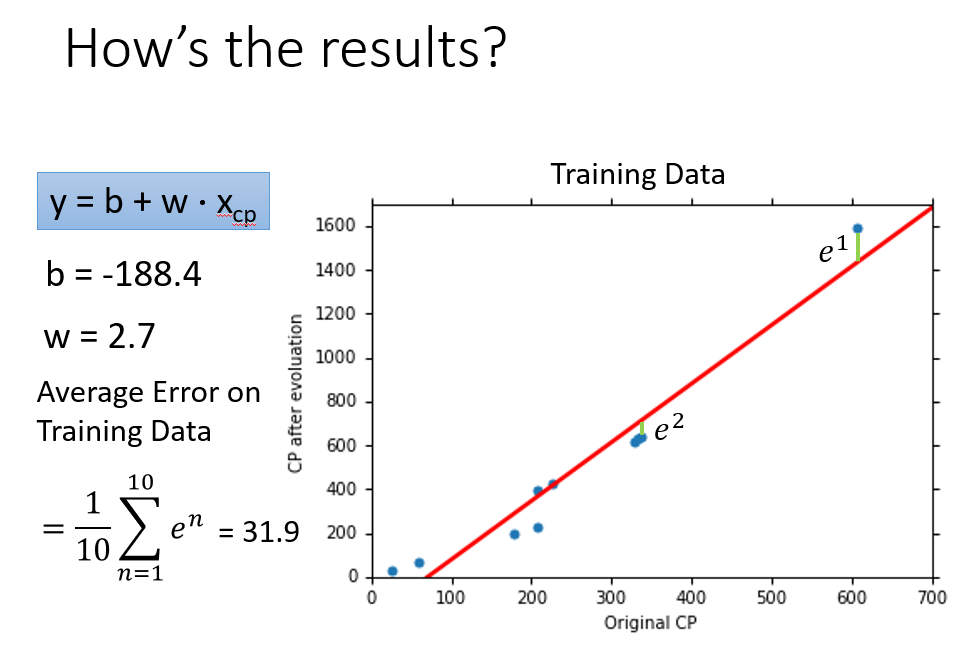
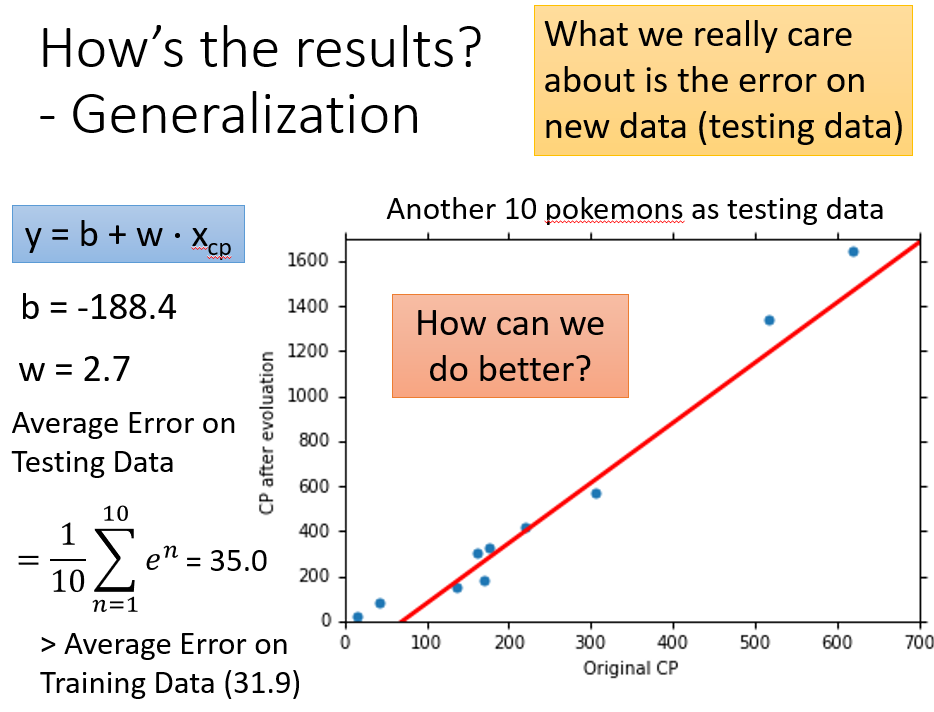
当然效果好不好,还得用在Testing Data上
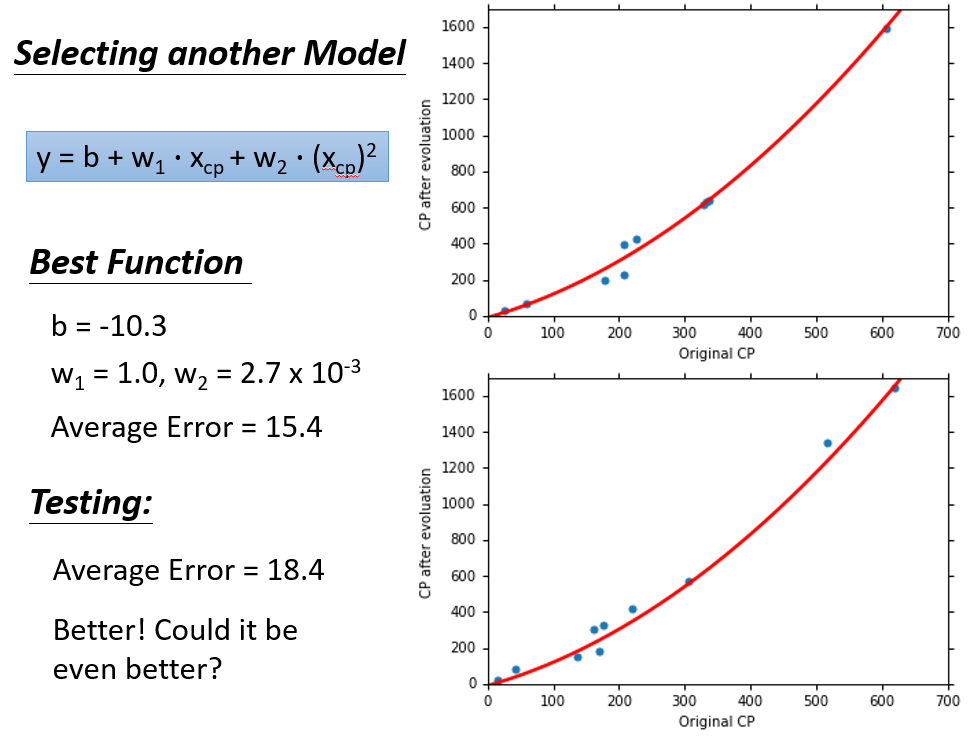
当我们选择其他的model时,重新计算参数的值,并观察效果
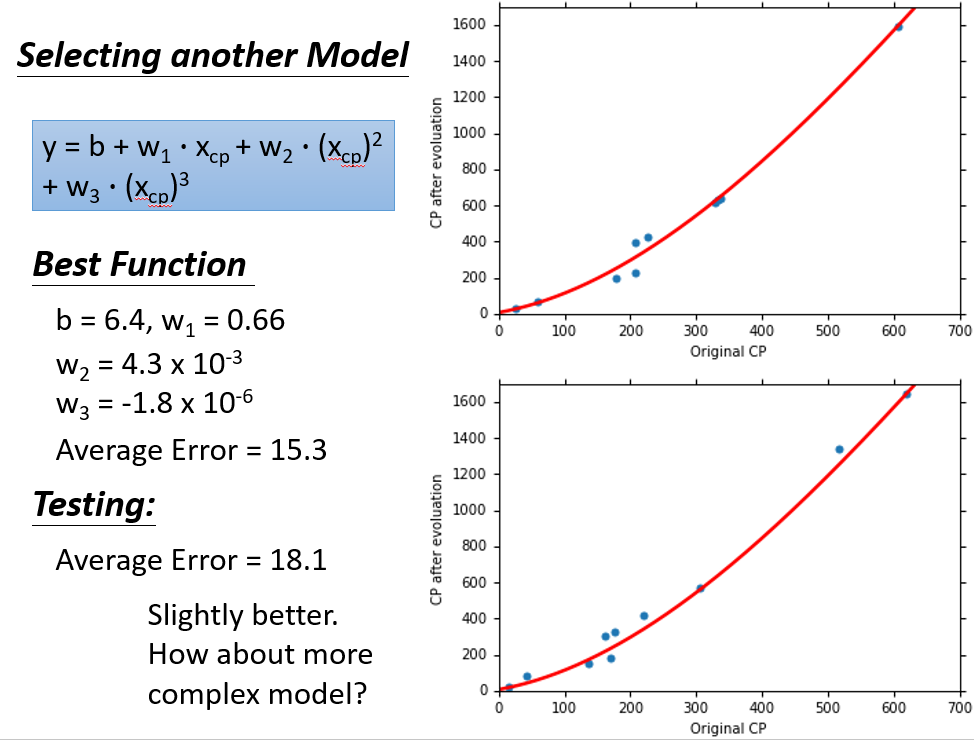
二次式:
三次式:
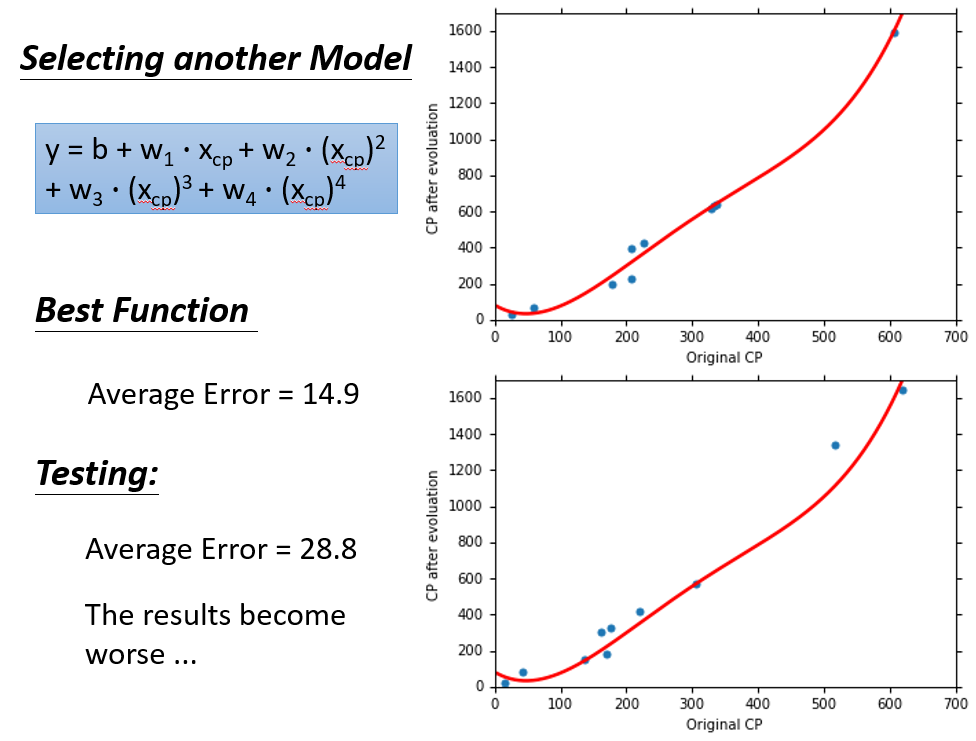
四次式:
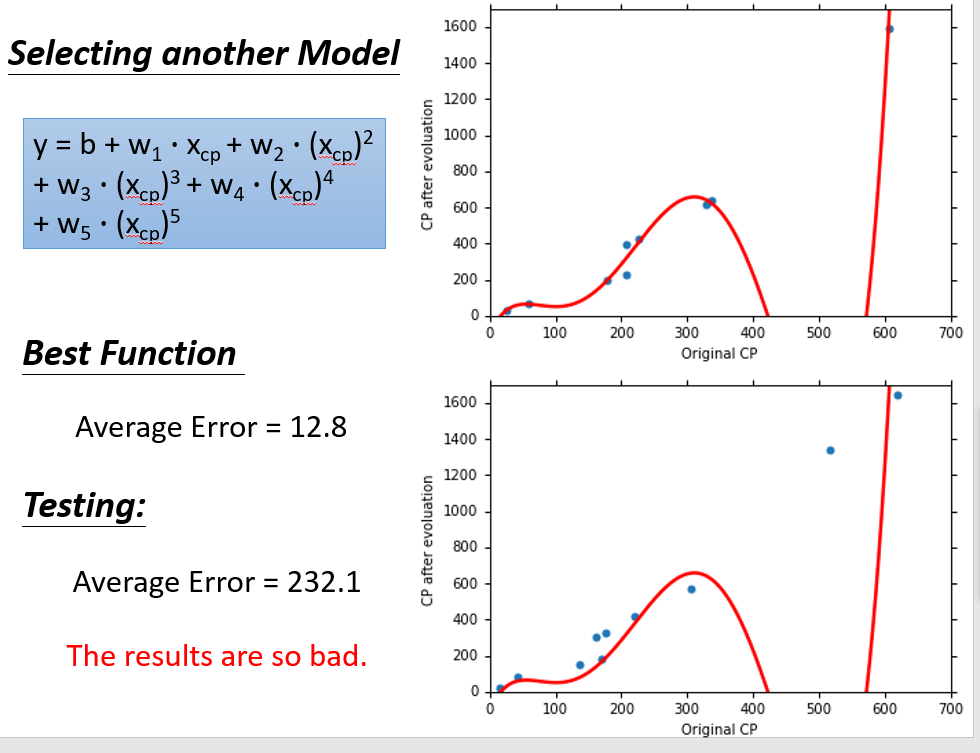
五次式:
这么多model,我们就不可避免要进行选择
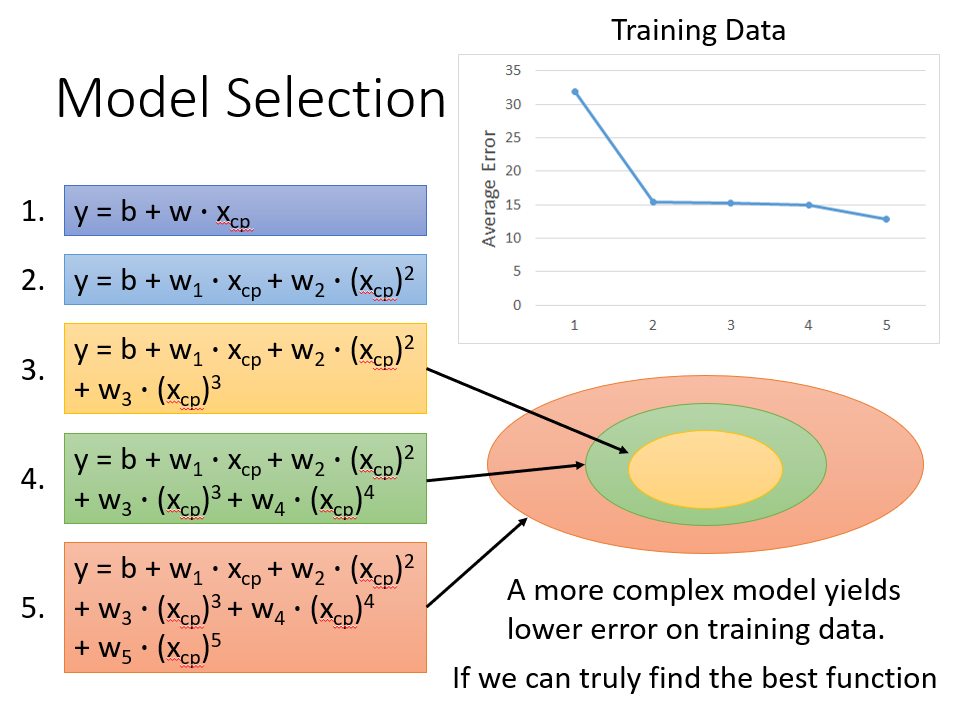
可以清晰看见,并不是选择的函式越复杂越好,复杂的函式反而会过拟合(后面会说),反正可以看见当次数为3时,在Testing Data上的效果最好

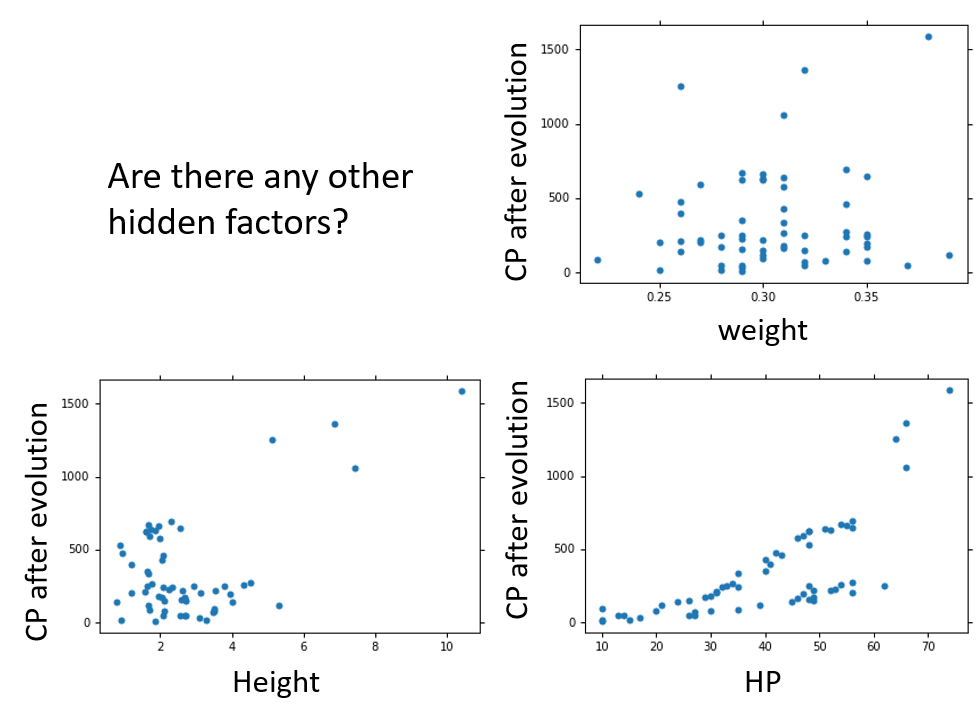
当我们选好模型之后,是不是就可以完事了呢,当然不是,因为可以存在着一些其他复杂的因素对我们的实验造成影响,当收集测试更多的数据时问题就越明显

例如在这个宝可梦种族值预测实验中,宝可梦的种类就是一个不可忽视的因素,因为不同种类的宝可梦,使用的肯定不是一个函式.

这种问题我们直接回归到函式设计那一步,直接弄一个类似电路0,1选择那种的超级函式就行,是这个物种的话它前面的系数就为1,其他的系数为0.
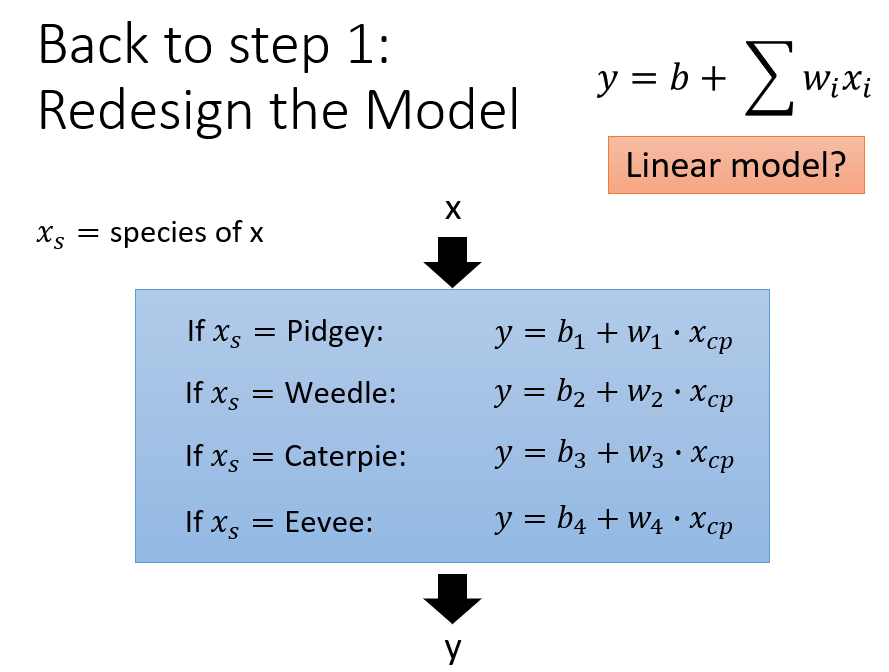

如果此时还考虑其他因素,就一并加上.
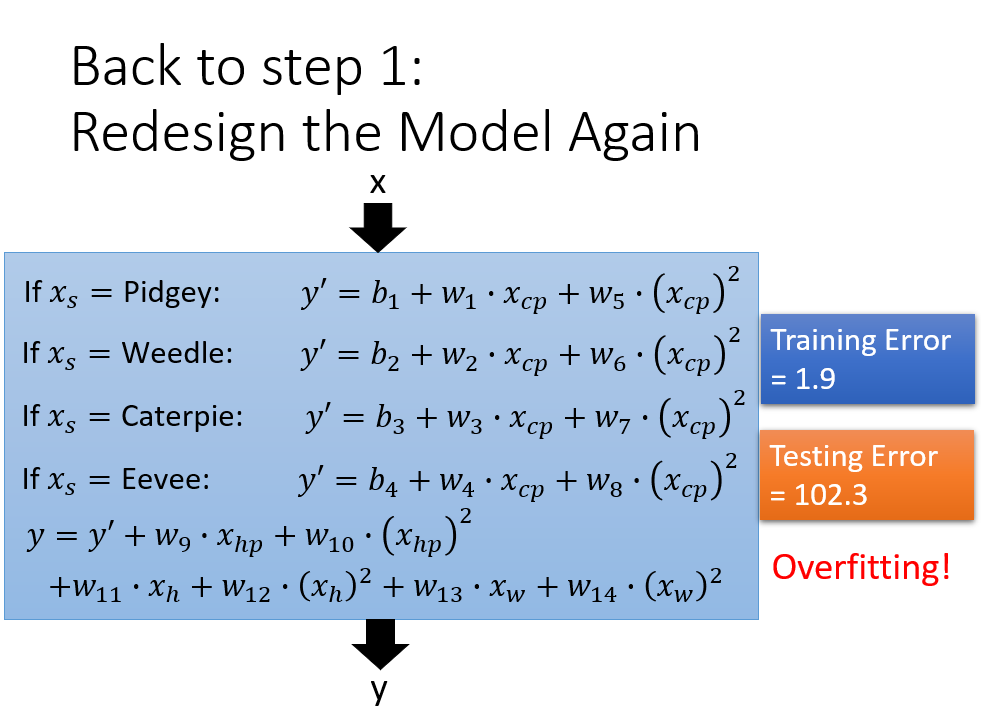
就像上面那样,考虑到了一大堆因素,结果可能会导致过拟合,所以还差一步正则化(使函式变得平滑)
在整个函式后面加一项关于w的式子,它拥有一个系数Lambda.
新添的式子不带b是因为b是个常数,只会上下移动函式图像,不会改变其平滑程度,对实验无意义.

系数越大,wi的影响就相对越小,function就越平滑
但系数并不是越大越好,太大依旧会使error变得很大,所以应该选择合适的系数
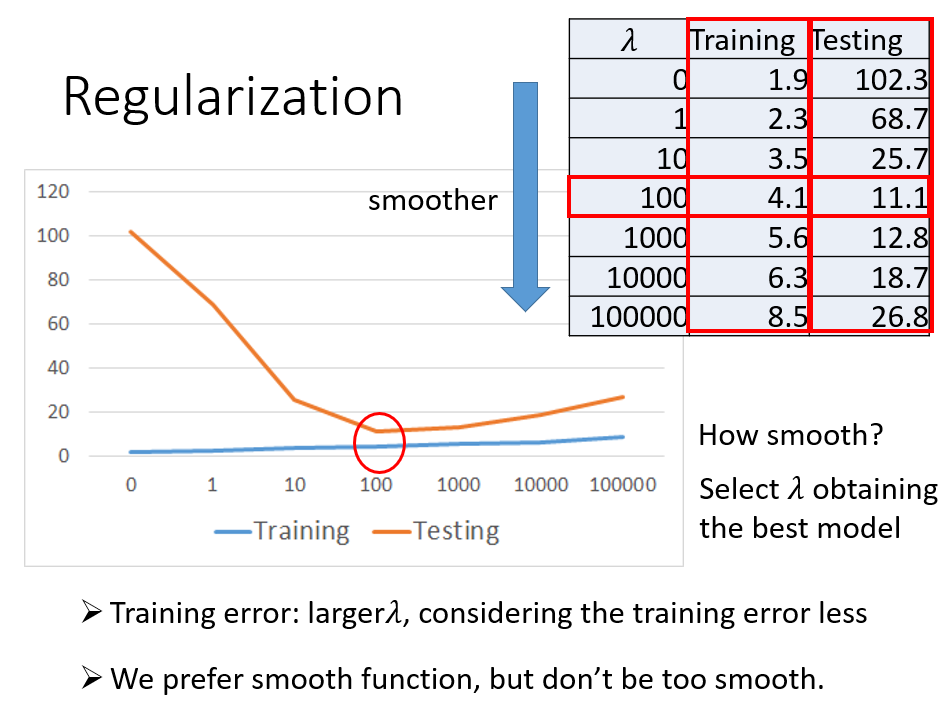
经过一番努力,最终确定系数为100
最终的Testing Error=11.1
小总结

Comments NOTHING