


机器学习中的评价指标
评价指标
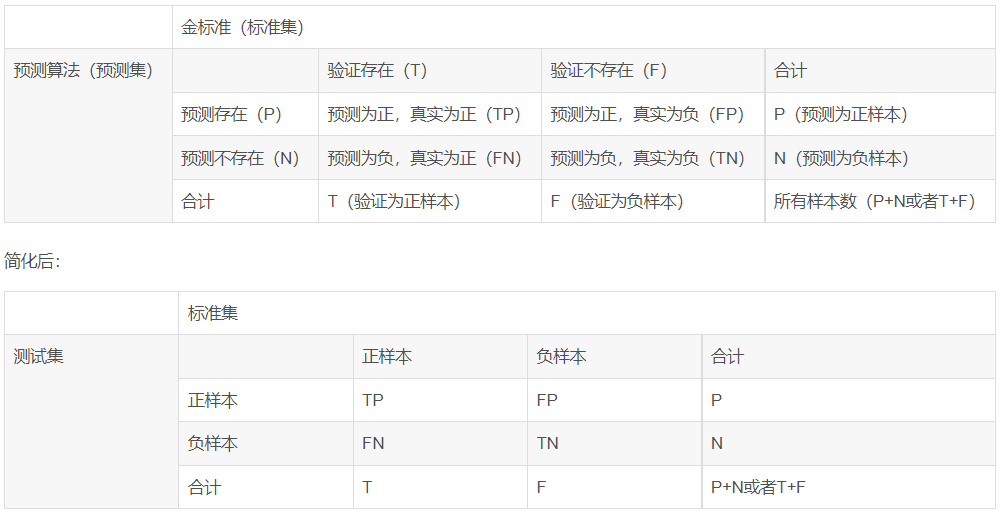
记忆:俩字母,后面的字母代表预测结果(P为正,N为负),前面代表咱预测的对不对。例如FP,后面的是P,就表示咱们的预测结果为正,前面的F表示咱这次预测错了,真正的结果为负。例如:FP表示预测为正,真实为负。
精确度(precision)/查准率:TP/(TP+FP)=TP/P 预测为真中,实际为正样本的概率
召回率(recall)/查全率:TP/(TP+FN) 正样本中,被识别为真的概率
假阳率(False positive rate):FPR = FP/(FP+TN) 负样本中,被识别为真的概率
真阳率(True positive rate):TPR = TP/(TP+FN) 正样本中,能被识别为真的概率
准确率(accuracy):ACC =(TP+TN)/(P+N) 所有样本中,能被正确识别的概率
宏查X率:先计算查X率,后计算平均
微查X率:先计算TP等平均,后计算查X率
丢失率(missrate )/漏警率:MA = 1-recall=FN/(TP+FN)
虚警率(FalseAlarm ):FA=FP/(FP+TP)
ground truch:TP+FN
model result:TP+FP
P:precision,预测正确的个数/测试总个数
AP:average precision,每一类别P值的平均值
MAP:mean average precision,对所有类别的AP取均值
PR曲线
PR曲线实则是以precision(精准率)和recall(召回率)这两个为变量而做出的曲线,其中recall为横坐标,precision为纵坐标。
一个阈值对应PR曲线上的一个点。通过选择合适的阈值,比如50%,对样本进行划分,概率大于50%的就认为是正例,小于50%的就是负例,从而计算相应的精准率和召回率。(选取不同的阈值,就得到很多点,连起来就是PR曲线)

如果一个学习器的P-R曲线被另一个学习器的P-R曲线完全包住,则可断言后者的性能优于前者,在没有完全包住的情况下,可以比较面积大小,但是这时一般看平衡点(BEP),平衡点是P=R时的取值(即PR曲线与P=R的交点),如果这个值较大,则说明学习器的性能较好。
ROC曲线
ROC的全称是Receiver Operating Characteristic Curve,中文名字叫“受试者工作特征曲线”,顾名思义,其主要的分析方法就是画这条特征曲线。
该曲线的横坐标为假阳性率(False Positive Rate, FPR)
纵坐标为真阳性率(True Positive Rate, TPR)
ROC曲线也需要相应的阈值才可以进行绘制,原理同上的PR曲线。
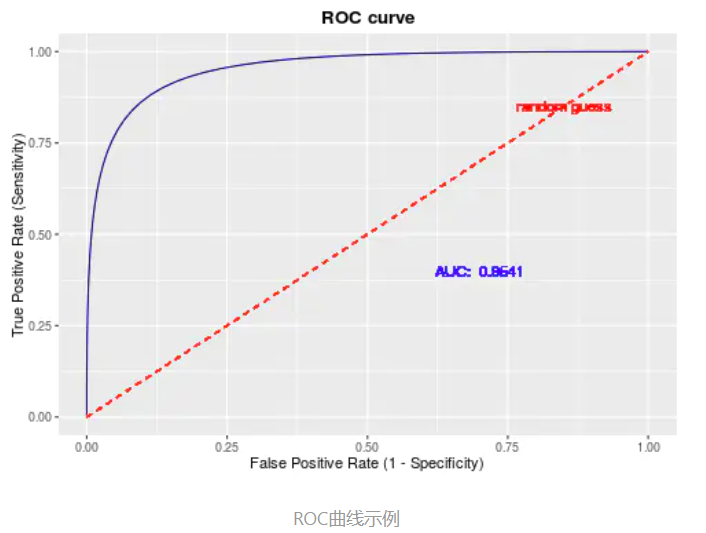
ROC曲线的应用场景有很多,根据上述的定义,其最直观的应用就是能反映模型在选取不同阈值的时候其敏感性(sensitivity, FPR)和其精确性(specificity, TPR)的趋势走向。不过,相比于其他的P-R曲线(精确度和召回率),ROC曲线有一个巨大的优势就是,当正负样本的分布发生变化时,其形状能够基本保持不变,而P-R曲线的形状一般会发生剧烈的变化,因此该评估指标能降低不同测试集带来的干扰,更加客观的衡量模型本身的性能。
ROC曲线图中的四个点
第一个点:(0,1),即FPR=0, TPR=1,这意味着FN=0,并且FP=0。这是完美的分类器,它将所有的样本都正确分类。
第二个点:(1,0),即FPR=1,TPR=0,类似地分析可以发现这是一个最糟糕的分类器,因为它成功避开了所有的正确答案。
第三个点:(0,0),即FPR=TPR=0,即FP=TP=0,可以发现该分类器预测所有的样本都为负样本(negative)。
第四个点:(1,1),分类器实际上预测所有的样本都为正样本。经过以上的分析,ROC曲线越接近左上角,该分类器的性能越好。
ROC曲线往左上越凸越好,PR曲线往右上越凸越好。

AUC
这里补充一下AUC的简单介绍。
AUC (Area under Curve):ROC曲线下的面积,介于0.1和1之间,作为数值可以直观的评价分类器的好坏,值越大越好。
AUC = 1,是完美分类器,采用这个预测模型时,存在至少一个阈值能得出完美预测。绝大多数预测的场合,不存在完美分类器。
0.5 < AUC < 1,优于随机猜测。这个分类器(模型)妥善设定阈值的话,能有预测价值。
AUC = 0.5,跟随机猜测一样(例:丢铜板),模型没有预测价值
Comments NOTHING